







paper:ResMLP: Feedforward networks for image classification with data-efficient training
official implementation:https://github.com/facebookresearch/deit
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/mlp_mixer.py
背景
ResMLP和Google的MLP-Mixer的发布只隔了3天,后者的介绍具体见MLP-Mixer(NeurIPS 2021, Google)论文与源码解读-CSDN博客。两者都是基于MLP架构的视觉模型,但在具体实现细节上有一些区别。
ResMLP和MLP-Mixer的异同
相同点:
- 两者都基于MLP架构,舍弃了CNN中的卷积层和Transformer中的self-attention,使用全连接层来处理图像数据。
- 两者都受到Transformer的启发,利用了Transformer中token-to-token交互的概念。两者都利用patch embedding层将输入图片分割成不重叠的patch然后展平,每个patch看作一个token。
- 两者都采用分离的策略来处理图像中的token(或patch)和通道(channel)信息。具体来说,两者都会通过一个全连接层处理token维度的信息,然后通过另一个全连接层处理通道维度的信息。
不同点:
- MLP-Mixer通过两个MLP分别处理patch和通道的信息,每个MLP中包含两个全连接层。而在ResMLP中,只用了一个全连接层来处理patch的信息,处理通道的信息和MLP-Mixer一样采用了一个包含两个全连接层的MLP。
- MLP-Mixer中采用LayerNorm的规范化。ResMLP采用了"pre-normalization"和"post-normalization"两种规范化,其中pre-normalization采用了Affine per-channel transformation,post-normalization采用了CaiT(具体介绍见CaiT(ICCV 2021,Meta)论文与代码解析-CSDN博客)中的LayerScale。
- MLP-Mixer研究了MLP在更大的数据集上的预训练效果,比如ImageNet-22k和JFT-300M,而ResMLP更聚焦于在ImageNet-1k上用更强的数据增强训练更快的MLP模型。
- ResMLP进行了详细的消融实验,探索了不同模型组件(如规范化、池化、patch大小等)对模型性能的影响。此外还测试了线性层替换为不同类型卷积的效果,发现深度可分离卷积在参数和计算量上与线性层相当,但在准确率上略有提升。
- 除了常规的监督学习,ResMLP还展示了在自监督学习和知识蒸馏中的应用,显示出其在多种训练范式中的灵活性和适应性。
方法介绍

ResMLP的整体结构如图1所示,可以看到一个block中包含一个cross-patch sublayer和一个cross-channel sublayer,前者只有一个线性层,后者有两个线性层,都采用了residual connection,规范化都采用Affine,整体没有太多新的东西,如下

其中每个sublayer中都包含了两个Affine,这里的Affine取代了BN或LN,就是一个简单的仿射变换,如下
![]()
每个sublayer包含两个Affine,线性层前的称为pre-normalization,就是式(1)。线性层后的称为post-normalization,类似于CaiT中的LayerScale,即每个通道单独学习一个加权参数。
代码解析
timm中的实现如下,对照MLP-Mixer的实现可以看到区别在于:(1)self.mlp_tokens变成了一个线性层self.linear_tokens(2)self.norm1由LayerNorm改为Affine(3)线性层后多了一个self.ls1即一个layerscale层。
其中Affine中 \(\alpha\) 初始化为1,\(\beta\) 初始化为0,是为了在刚开始训练时让Affine表现的像一个identiy。self.ls1和self.ls2都初始化为一个很小的数1e-4,和CaiT中一样。
class Affine(nn.Module):
def __init__(self, dim):
super().__init__()
self.alpha = nn.Parameter(torch.ones((1, 1, dim)))
self.beta = nn.Parameter(torch.zeros((1, 1, dim)))
def forward(self, x):
return torch.addcmul(self.beta, self.alpha, x) # \alpha * x + \beta
class ResBlock(nn.Module):
""" Residual MLP block w/ LayerScale and Affine 'norm'
Based on: `ResMLP: Feedforward networks for image classification...` - https://arxiv.org/abs/2105.03404
"""
def __init__(
self,
dim,
seq_len,
mlp_ratio=4,
mlp_layer=Mlp,
norm_layer=Affine,
act_layer=nn.GELU,
init_values=1e-4,
drop=0.,
drop_path=0.,
):
super().__init__()
channel_dim = int(dim * mlp_ratio) # 384*4=1536
self.norm1 = norm_layer(dim)
self.linear_tokens = nn.Linear(seq_len, seq_len) # 196,196
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp_channels = mlp_layer(dim, channel_dim, act_layer=act_layer, drop=drop) # 384,1536
self.ls1 = nn.Parameter(init_values * torch.ones(dim))
self.ls2 = nn.Parameter(init_values * torch.ones(dim))
def forward(self, x): # (1,196,384)
# Linear(in_features=196, out_features=196, bias=True)
# (1,196,384)->(1,384,196)->(1,384,196)->(1,196,384)
x = x + self.drop_path(self.ls1 * self.linear_tokens(self.norm1(x).transpose(1, 2)).transpose(1, 2))
# Mlp(
# (fc1): Linear(in_features=384, out_features=1536, bias=True)
# (act): GELU()
# (drop1): Dropout(p=0.0, inplace=False)
# (norm): Identity()
# (fc2): Linear(in_features=1536, out_features=384, bias=True)
# (drop2): Dropout(p=0.0, inplace=False)
# )
x = x + self.drop_path(self.ls2 * self.mlp_channels(self.norm2(x))) # (1,196,384)
return x实验结果
和其它sota模型在ImageNet上的分类性能对比如表1所示,可以看到虽然ResMLP的速度-精度权衡以及FLOPs和吞吐都不如卷积或Transformer好,但ResMLP简单的设计也取得了不错的性能,表明网络的设计对性能的影响没有那么大,特别是在有充足的训练数据和新的训练方法时。

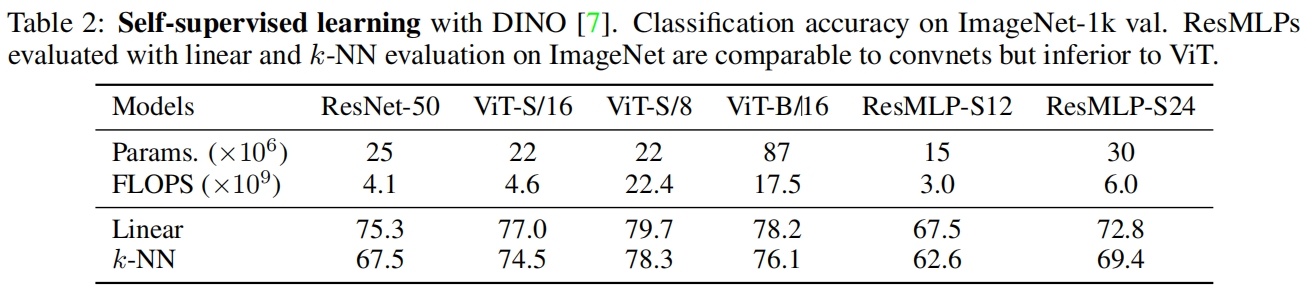
用自监督方法DINO对ResMLP、ResNet、ViT进行了预训练,结果如表2所示。结果的趋势和有监督训练相同,效果不如ResNet和ViT,但对于一个纯MLP结构来说已经足够好了,特别是在k-NN评估下的结果和卷积相比很具有竞争力。
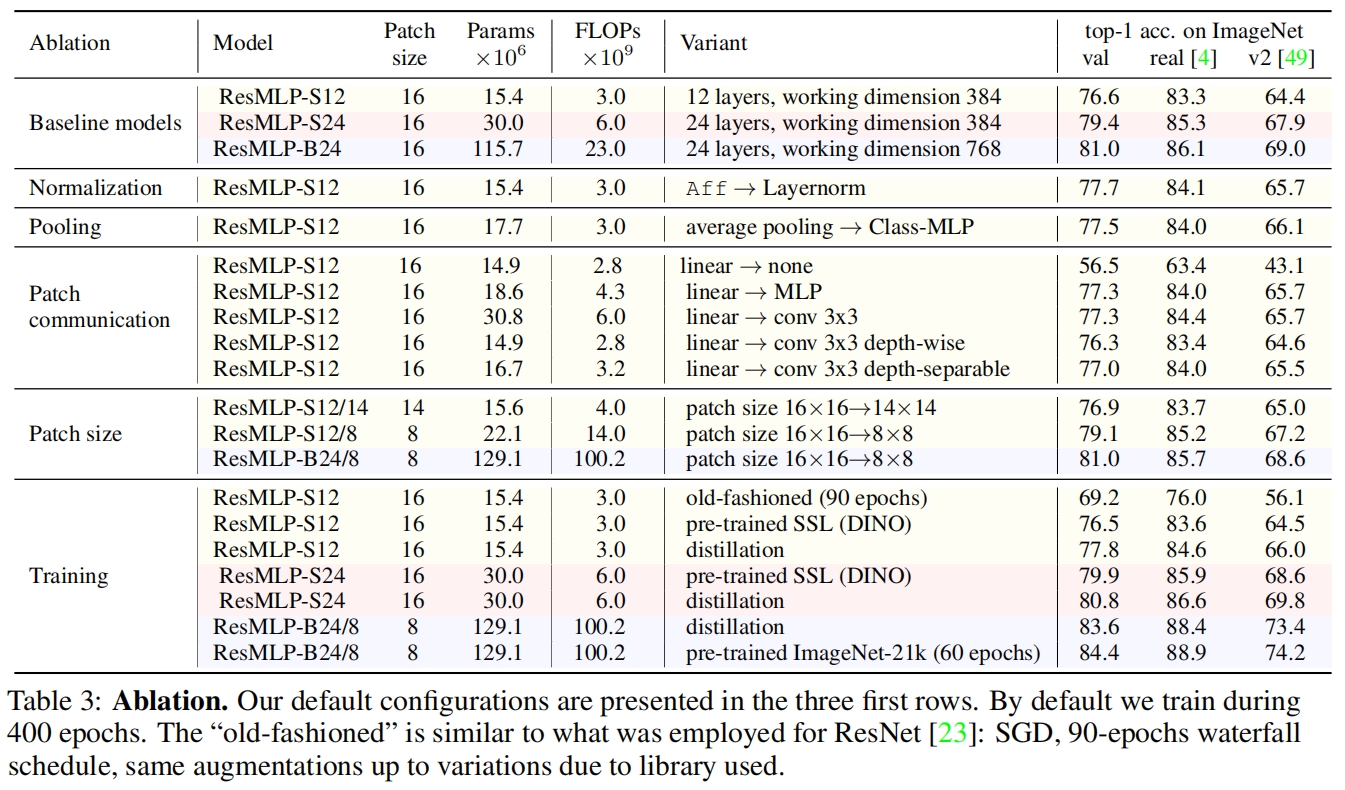
作者还采用了DeiT中的蒸馏方法对ResMLP也进行了蒸馏,结果如下,可以看到ResMLP从卷积网络中蒸馏也受益很大。
















 2723
2723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











