







paper:Twins: Revisiting the Design of Spatial Attention in Vision Transformers
official implementation:https://github.com/Meituan-AutoML/Twins
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/twins.py
本文的创新点
- 提出了两个新的视觉Transformer架构:Twins-PCPVT和Twins-SVT。
- Twins-PCPVT基于PVT和CPVT,通过使用条件位置编码(CPE)替代绝对位置编码,解决了PVT在处理变尺寸输入时的性能问题。
- Twins-SVT提出了一种简单但高效的空间分离自注意力(SSSA)机制,包括局部分组自注意力(LSA)和全局子采样自注意力(GSA),以同时捕获短距离和长距离信息。
方法介绍
Twins-PCPVT
PVT(具体介绍见 Pyramid Vision Transformer, PVT(ICCV 2021)原理与代码解读)引入了金字塔multi-stage设计,从而可以更好的处理密集预测任务比如目标检测和语义分割。它继承了ViT和DeiT中的绝对位置编码,所有层都是用全局注意力机制。但最近提出的基于移动局部窗口的Swin-Transformer,效果比PVT要好得多。
作者惊讶的发现PVT的性能较差主要是因为使用了绝对位置编码,如CPVT(具体介绍见CPVT(ICLR 2023)论文解读)所示,绝对位置编码在处理不同大小输入时存在困难(这在密集预测任务中很常见)。此外这种绝对位置编码也破坏了平移不变性。而Swin-Transformer使用了相对位置编码,不存在这些问题。
因此作者用CPVT中提出的条件位置编码(conditional position encoding,CPE)来代替绝对位置编码。CPE依赖于输入,可以自然地避免绝对位置编码的问题。用来生成CPE的位置编码生成器(position encoding generator,PEG)放置在网络每个stage的第一个encoder block后。我们使用PEG最简单的形式,一个2D深度卷积和一个BN。此外遵循CPVT的设计作者还去掉了class token并用全局平均池化来代替。作者经过实验证明,这种简单的改进可以匹配Swin-Transformer的性能。
Twins-SVT
由于高分辨率的输入,Vision transfomers在密集预测任务中存在严重的计算复杂性问题。本文提出了空间可分离自注意力(spatial separable self-attention,SSSA)来缓解这一问题,SSSA由局部分组自注意力(local-grouped self-attention,LGA)和全局欠采样自注意力(global sub-sampled self-attention,GSA)组成。
LSA其实就是Swin-Transformer中的window-based self-attention,即将特征图等分为多个窗口,在每个窗口内部计算self-attentio。虽然LSA降低了计算量,但窗口之间是不重叠的,还需要一种机制在不同子窗口之间通信,否则只处理窗口内的信息,感受野很小,性能也会下降。
一种简单的解决方案是在LSA后添加额外的标准全局self-attention,但全局自注意力的计算复杂度又很大。这里作者使用一个维度较低的特征作为子窗口的表征,然后与其它窗口通信(作为self-attention中的key),可以大幅降低计算复杂度。这种方法实际上就是对特征图进行降采样,其中对K、V的特征进行了降维,而Q还是全局的,因此注意力仍然可以恢复到全局。
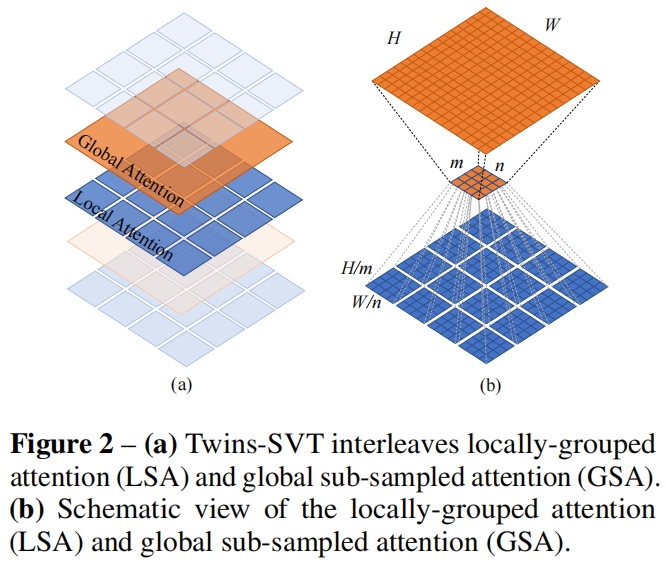
实验结果
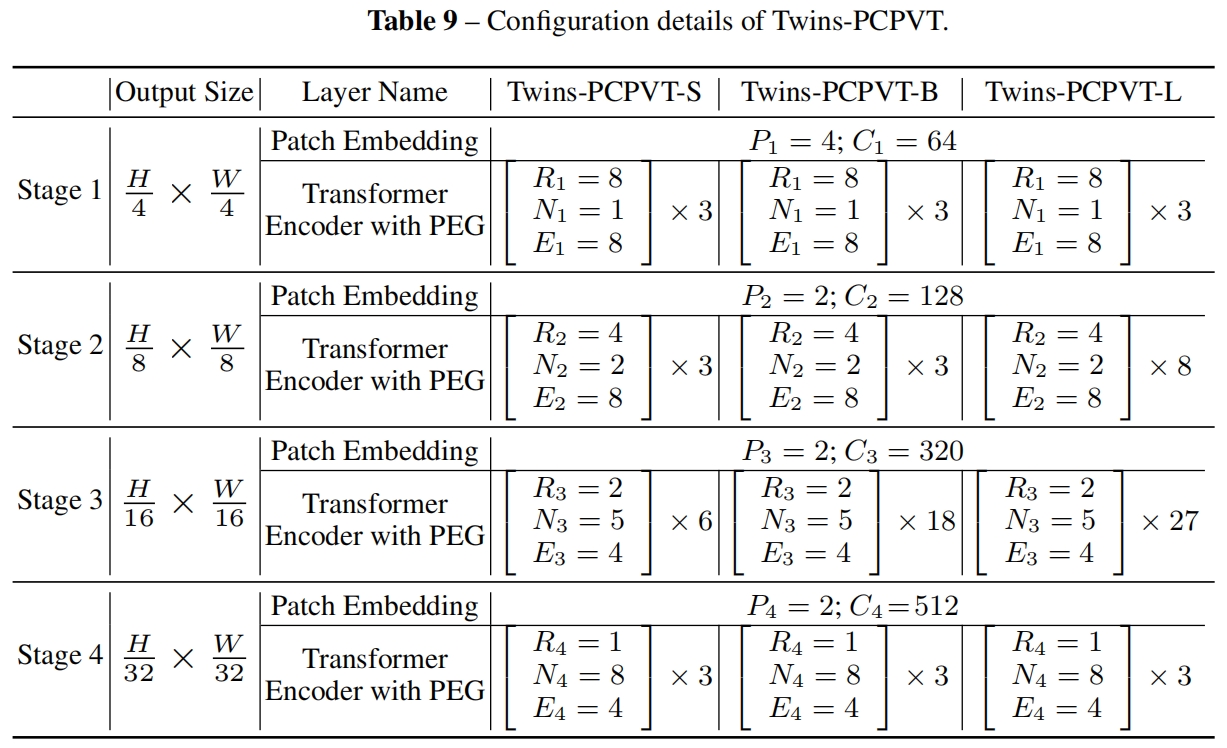
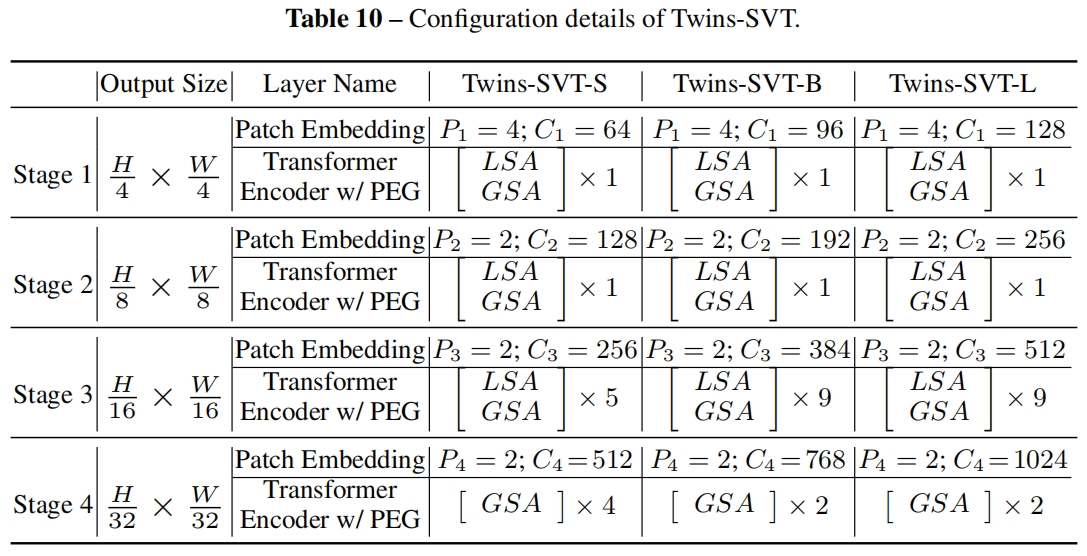
网络配置如下
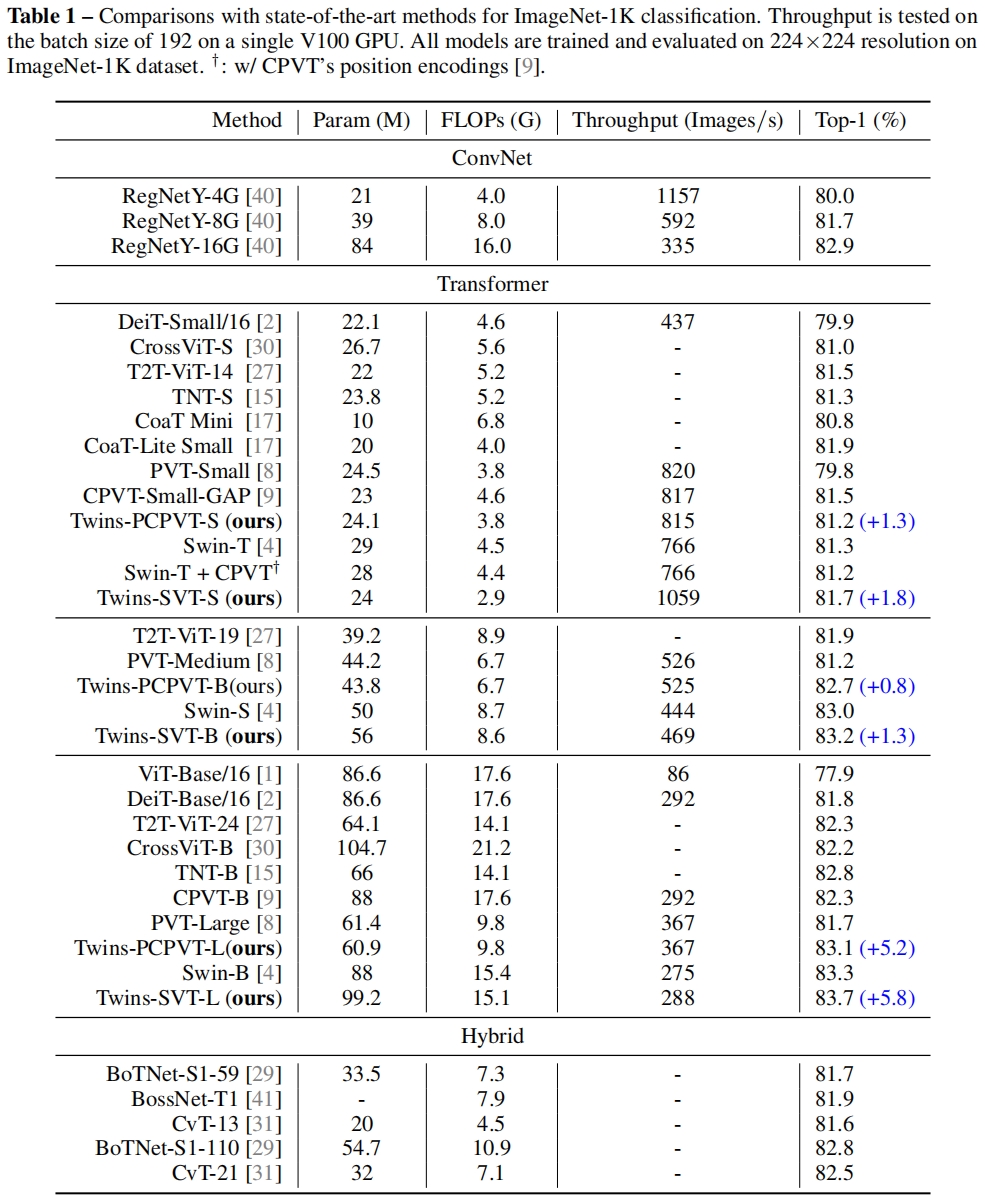
在ImageNet-1K上的结果如下所示
代码解析
这里以timm中的实现为例,模型选择"twins_svt_small",输入大小为(1, 3, 224, 224)。
LSA就是swin-transformer中的window-based self-attention,通过reshape将spaial维度等分多个窗口,然后将窗口数量合并到batch size维度,然后在每个窗口内计算全局自注意力,这里就不贴代码了。
GSA的代码如下,其中除了对key和value进行了降维,其它都是常规的self-attention操作。
class GlobalSubSampleAttn(nn.Module):
""" GSA: using a key to summarize the information for a group to be efficient.
"""
fused_attn: torch.jit.Final[bool]
def __init__(self, dim, num_heads=8, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim # 64
self.num_heads = num_heads # 2
head_dim = dim // num_heads # 32
self.scale = head_dim ** -0.5
self.fused_attn = use_fused_attn()
self.q = nn.Linear(dim, dim, bias=True)
self.kv = nn.Linear(dim, dim * 2, bias=True)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
else:
self.sr = None
self.norm = None
def forward(self, x, size: Size_): # (1,3136,64), (56,56)
B, N, C = x.shape
# Linear(in_features=64, out_features=64, bias=True)
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # (1,31,36,64)->(1,3136,2,32)->(1,2,3136,32)
if self.sr is not None: # Conv2d(64, 64, kernel_size=(8, 8), stride=(8, 8))
# 这里如果sr的kernel_size=(7,7), stride=(7,7)是不是更能跟local_group_attn对应起来,因为LGA是在局部7x7的window内计算attn的
x = x.permute(0, 2, 1).reshape(B, C, *size) # (1,64,3136)->(1,64,56,56)
x = self.sr(x).reshape(B, C, -1).permute(0, 2, 1) # (1,64,7,7)->(1,64,49)->(1,49,64)
x = self.norm(x)
# Linear(in_features=64, out_features=128, bias=True)
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # (1,49,128)->(1,49,2,2,32)->(2,1,2,49,32)
k, v = kv.unbind(0) # (1,2,49,32),(1,2,49,32)
if self.fused_attn:
x = torch.nn.functional.scaled_dot_product_attention(
q, k, v,
dropout_p=self.attn_drop.p if self.training else 0.,
)
else:
q = q * self.scale
attn = q @ k.transpose(-2, -1) # (1,2,3136,49)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = attn @ v # (1,2,3136,32)
x = x.transpose(1, 2).reshape(B, N, C) # (1,3136,2,32)->(1,3136,64)
# Linear(in_features=64, out_features=64, bias=True)
x = self.proj(x) # (1,3136,64)
x = self.proj_drop(x)
return x

















 2849
2849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











