







背景
对浙大《机器学习》课程,支持向量机部分的一点消化。对应2.1.1, 2.2.1, 2.3.1。
支持向量机求解
对于一个线性可分的训练样本集,支持向量机就是要找出一个超平面。这个超平面满足:
- 这个超平面分开了训练样本集
- 该超平面有最大的间隔(margin)
- 课程里原话是这么说的。我觉得准确说应该是:由该超平面推出的两边两个支持向量之间有最大的距离。
- 该超平面处于间隔的中间,到所有支持向量的距离相等。
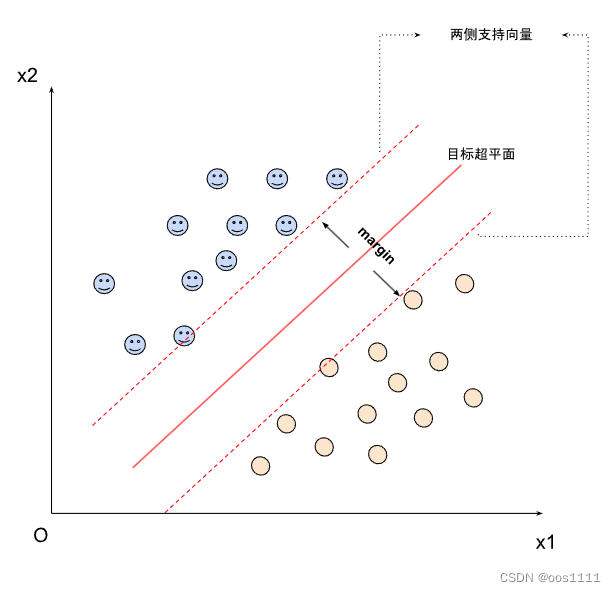
线性可分的定义
对于样本集 { ( X i , y i ) , i = 1... N } \{ (X_{i} ,y_{i}), i = 1 ... N \} {(Xi,yi),i=1...N},存在超平面 ω T ⋅ X + b = 0 \omega^{T} \cdot X + b = 0 ωT⋅X+b=0,使得:
-
y = -1 时, ω T ⋅ X + b < 0 \omega^{T} \cdot X + b < 0 ωT⋅X+b<0
-
y = 1 时, ω T ⋅ X + b > 0 \omega^{T} \cdot X + b > 0 ωT⋅X+b>0
转化为数学最优化问题
最小化 1 2 ∥ ω ∥ 2 \frac{1}{2} \left\| \omega \right \|^{2} 21∥ω∥2,使得 y i ( ω T ⋅ X i + b ) ≥ 1 y_{i} (\omega^{T} \cdot X_{i} + b) \ge 1 yi(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









