







一、基本概念
1.1 机器学习
机器学习:采用非显著式编程(不一步一步定义操作步骤的编程方式)的方式赋予计算机学习能力。
机器学习:一个计算机程序被称为可以学习,是指它能够针对某个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。(较之定义一更数学化)
1.2 机器学习分类
基于经验E:
机器学习可以分为监督学习(Supervised Learning)与强化学习(Reinforcement Learning)。
监督学习:输入计算机训练数据同时加上标签的机器学习;所有的经验E都是人工采集并输入计算机的。
强化学习:让计算机通过与环境的互动逐渐强化自己的行为模式;经验E由计算机和环境互动获得的。
(但划分方式也不绝对)
监督学习根据数据标签存在与否分类:
- 传统的监督学习(Traditional Supervised Learning);
每个训练数据都有对应的标签;例如:支持向量机(Support Vector Machine)、人工神经网络(Neural Networks)、深度神经网络(Deep Neural Network) - 非监督学习(Unsupervised Learning);
训练数据没有对应标签;例如:聚类(Clustering)、EM算法(Expectation-Maximization algorithm)、主成分分析(Principle Components Analysis) - 半监督学习(Semi-supervised Learning)。
一部分有标签、一部分没有标签。
基于标签的固有属性
监督学习可以分为分类(Classification)与回归(Regression)。
分类:标签是离散的值;
回归:标签是连续的值。
1.3 机器学习算法的过程
- 观察数据,总结规律;
- 特征提取(Feature Extraction):是指通过训练样本获得的对机器学习任务有帮助的多维度的特征数据;
- 特征选择(Feature Selection);
- 构建算法:划分不同的特征空间;
- 训练结果。
1.4 没有免费午餐原理
No Free Lunch Theorem:
任何一个预测函数,如果在一些训练样本上表现好,那么必然在另一些训练样本上表现不好,如果不对数据在特征空间的先验分布有一定的假设,那么表现好与表现不好的情况一样多。
二、支持向量机SVM
2.1 支持向量机的理论推导
线性可分(Linear Separable):
存在一条直线将两类分开;



问题描述
SVM是先解决线性可分的问题,然后将线性可分的结论推广到线性不可分中。
如果一个数据集是线性可分的,则存在无数超平面将数据集划分成不同特征空间;那么哪一个超平面最好?
最优化理论:在若干约束中找到解决问题的最优解。
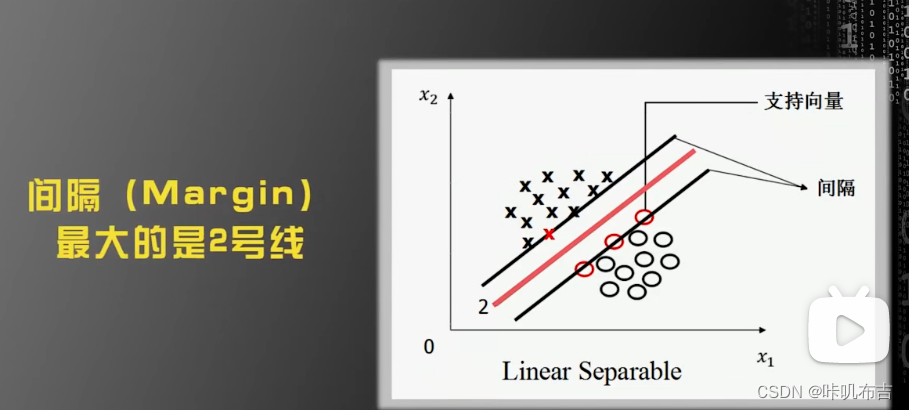
SVM就是要找出Margin最大的那一条线,但是使用Margin最大这个条件不能唯一确定一条直线。因此规定,这条线在上下两个平行线的中间。

最大化间隔=最大化1/ ||w||,即最小化||w||^2。

yi:协调超平面的左右,使一边大于1,一边小于1。

二次规划
1.目标函数是二次项;
2.限制函数是一次项;
3.要么无解,要么只有唯一的最小值
凸优化问题只有唯一一个全局极值。 一个优化问题是凸的,总能找到高效快速算法去解决它。
2.2 线性不可分情况
如果数据集为线性不可分,则不可以用上述解决办法求解。所以要放松限制条件:对每个训练样本及标签(Xi,Yi)设置一个松弛变量δi(slack variable )
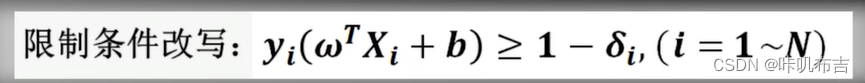
(因为它线性不可分,所以没办法用一个超平面把不同类别完全分开,所以我们允许一些变量不被分开,即松弛)
更改后:
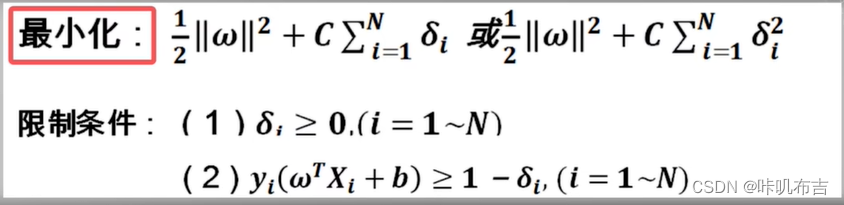
让|w|^2和所有δ和最小:比例因子C(超参数),平衡两项。
超参数hyper parameter:需要人为设定的参数。
2.3 扩大可选函数范围与核函数
其他:直接给出更多可选函数
但支持向量机:将特征空间从低维映射到高维再用线性超平面对数据进行分类
(如果原始空间是有限维,即属性有限,那么一定存在一个高维特征空间使样本可分)


φ(xi)形式?核函数(kernel function)
不需要知道φ(xi)的具体形式:
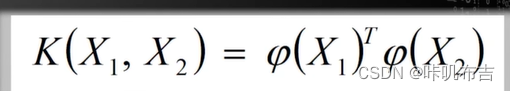
K(X1,X2)是实数


2.4 对偶问题
原问题:

定义函数L(ω,α,β):
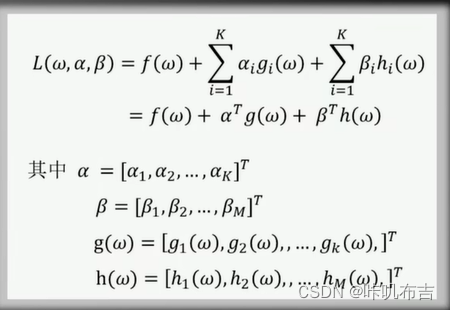
对偶函数(dual problem):

(inf表示最小值)



如果原问题的目标函数是凸函数,限制函数为线性函数,则f(ω*)=θ(α*,β*)


将原问题转为对偶问题:
- 将δi取反:


- 对偶问题:



2.5 支持向量机算法流程
求解对偶问题:
- 需要知道核函数:
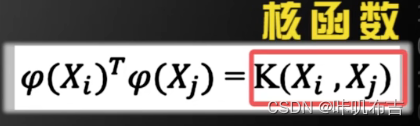
- 求解出

- 根据
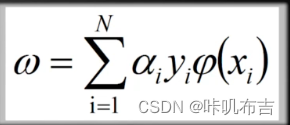
(ω不一定具有显示表达式) - 求解b:

根据KKT条件:



核函数戏法:

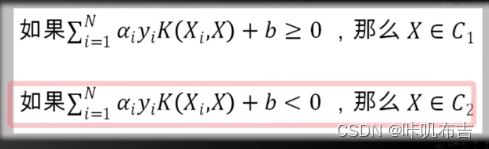
支持向量机训练与测试过程



2.6 评价系统好坏
不知道数据的先验分布,单纯用识别率来判断系统好坏无意义。
混淆矩阵:

TP+FN=C1
FP+TN=C2
如果把正样本识别成正样本的比例增加,则把负样本识别成正样本的比例也增加。

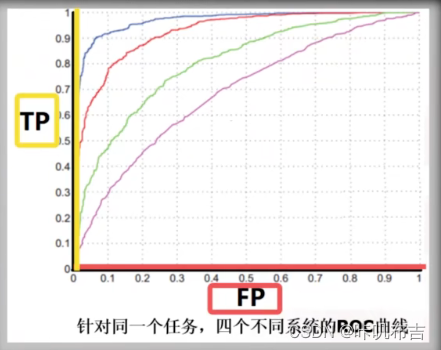
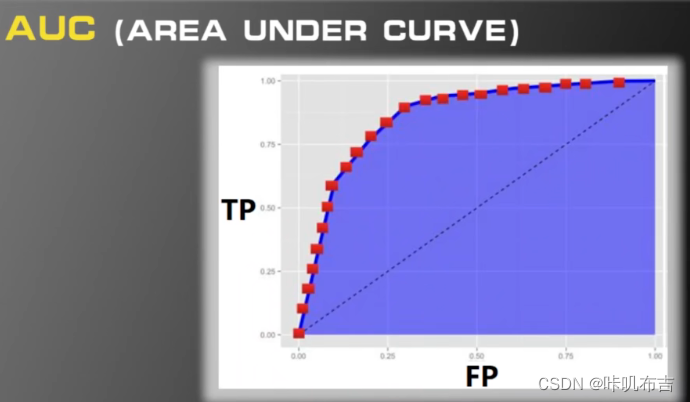
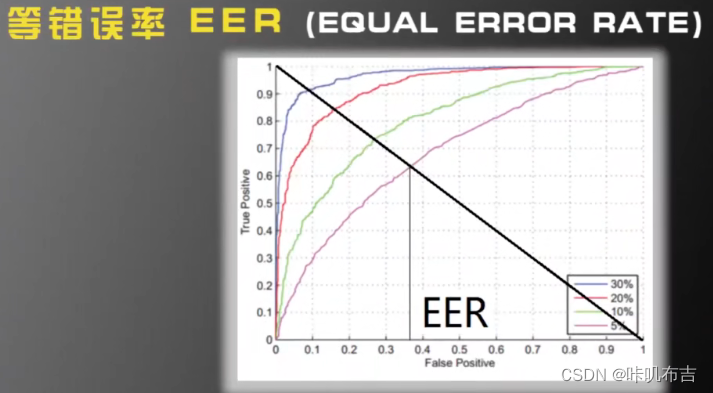
ROC:横坐标FP、纵坐标TP
越靠左上角性能越好。
2.7 多分类问题
**1类 vs K-1类 **
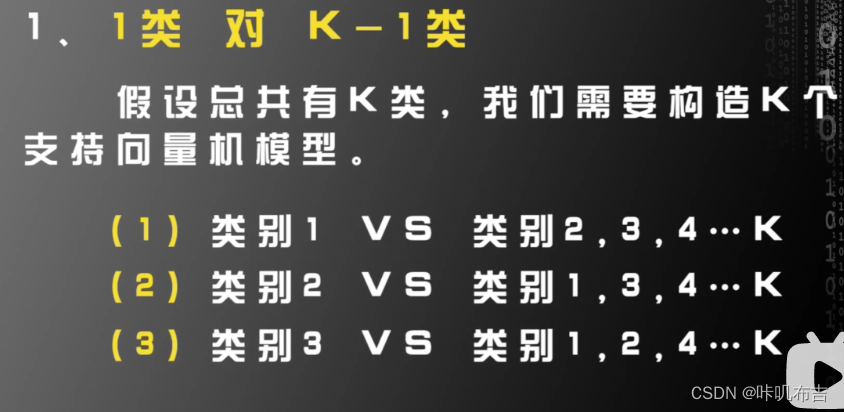


缺点:训练样本不平衡
1类 vs 另一类
训练k*(k-1)/2个向量机,分别为 1vs2 1vs3 1vsK 2vs 3 2vs k
但训练的向量机数目格外多。
所以综合两者,组成树状分类器。聚类或决策树算法
















 2149
2149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









