









我的博客已全部迁往个人博客站点:oukohou.wang,敬请前往~~
- paper: RAR:Retrieving And Ranking Augmented MLLMs for Visual Recognition
- codes: https://github.com/Liuziyu77/RAR
一、闲言碎语
RAR,整体动机总结一下:clip知道吧?Multimodal Large Language Models (MLLMs)知道吧?作者把它们俩整合到一起,
先用clip基于相似度找出外部知识库中最相近的几个候选项,然后用MLLM来选出最终的结果,这就是retrieving-and-ranking(RAR)的由来。
怎么样,是不是感觉好像有点意思?再给你张概览图爽一下:
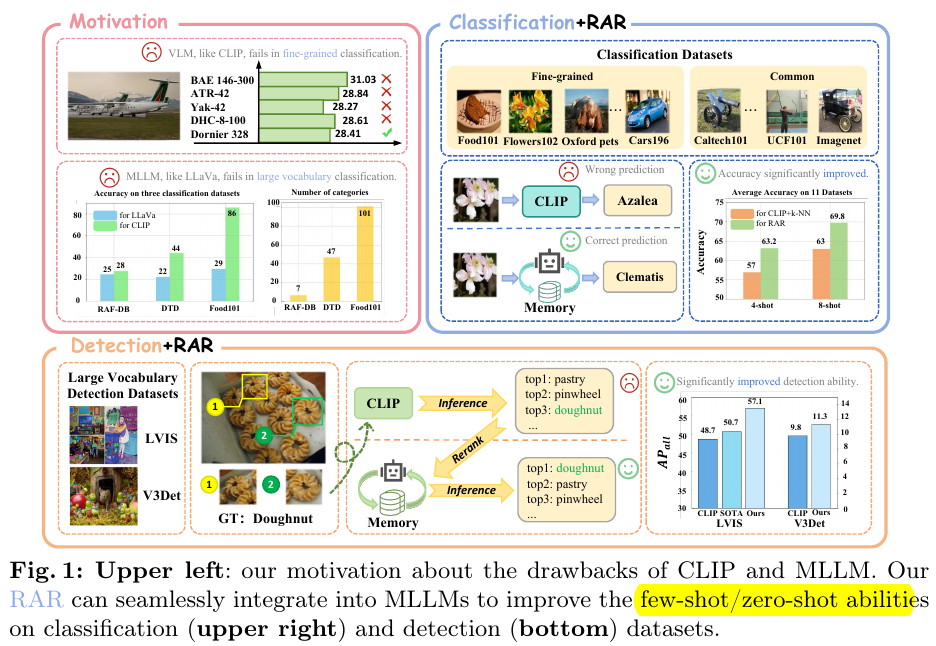
是不是已经有点恍然大明白了?那等我再详细介绍下这篇论文的实现细节,我的天,你对这篇论文的理解会有多高,我都不敢想!
二、历历在目
2.1. Multimodal Retriever
就是如何更好更快地实现从外部知识库retrieve到准确的图像或者文本的embedding.
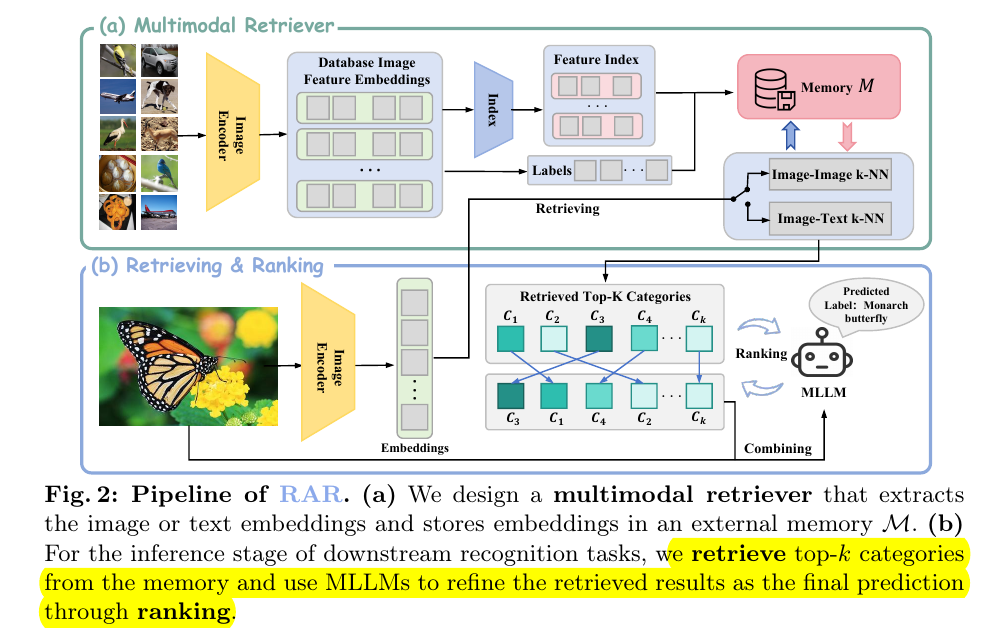
看图说话,以图像分类为例,图像和对应的标签都是用clip的对应模块给encode成embedding,然后保存到外部知识库。
这就是文中所谓的few-shot了;当有时候没有图像只有类别标签时,那就是所谓的zero-shot。
为了加速embedding匹配的速度,使用了 HNSW(Hierarchical Navigable Small World)来将embedding降低到初始维度的1/9。
对于检测来说,就是基于proposal的bounding box进行了固定比例的resize,然后将非目标区域进行了模糊化,从而让MLLM
能够聚焦于待检测目标,不被冗余信息干扰:
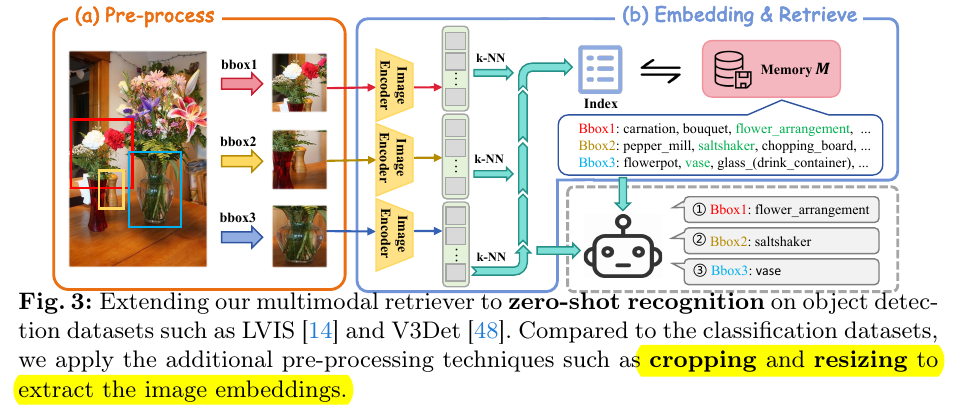
2.2. inference
预测的时候就很简单了,分类任务就直接匹配top-k个最相近的图像,然后用MLLM排序选出最像的;检测任务因为目标框
一般都比较小,特征embedding没啥大用,但是硬着头皮也得上啊,就改为匹配图像和文本的相似度。
然后得到的结果就拿来给MLLM来排序,prompt示意图如下:

2.3. Fine-tuning for Ranking
最后可能是担心论文内容不够丰富吧,还锦上添花地多加了个MLLM的微调任务,就是构造了个小数据集,然后训练MLLM
来更好地排序最终结果,就是这样。
三、完结撒花
最后就是试验结果了,无非就是对比一下,效果更好了,懒得贴图了。就这样。
微信公众号:璇珠杂俎(也可搜索[oukohou](https://mp.weixin.qq.com/s/dCxGcuv5ngyR6U-uBYVI9Q)),提供本站优质非技术博文~~
















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









