






黑箱机器学习模型现在经常用于高风险环境,如医疗诊断,这需要量化不确定性以避免相应的模型故障。共形预测(Conformal prediction)保形推理)是一种用户友好的范例,用于为这种模型的预测创建统计上严格的不确定性集/区间。重要的是,这些集合在无分布意义上是有效的:即使没有分布假设或模型假设,它们也具有明确的非渐近保证。我们可以使用任何预先训练的模型(如神经网络)进行共形预测,以产生保证包含用户指定概率(如90%)的地面真值的集合。它易于理解,易于使用和通用,自然适用于计算机视觉,自然语言处理,深度强化学习等领域出现的问题。
这本实践性介绍旨在通过一篇自成一体的文章,让读者对共形预测和相关的无分布不确定性量化技术有一个工作上的了解。我们将带领读者学习共形预测的实用理论和示例,并介绍其在复杂机器学习任务中的扩展,包括结构化输出、分布偏移、时间序列、异常值、弃权模型等。全书使用 Python 编写了大量解释性插图、示例和代码示例。每个代码示例都附有一个在真实数据示例中实现该方法的 Jupyter 笔记本;点击以下图标即可访问并轻松运行这些笔记本: .
1 Conformal Prediction
共形预测[1-3](又称保形推理)是为任何模型生成预测集的直接方式。我们将通过一个简短的实用图像分类示例介绍它,并在后面的段落中进行一般性解释。共形预测的高级概述如下。首先,我们开始一个拟合的预测模型(如神经网络分类器),我们称之为。然后,我们将使用少量额外的校准数据为这个分类器创建预测集(一组可能的标签)-我们有时称之为校准步骤。

为了从和校准数据构造C,我们将执行一个简单的校准步骤,只需要几行代码;参见图2的右侧面板。现在我们将更详细地描述校准步骤,并介绍一些稍后会有所帮助的术语。首先,我们设定conformal score
,1减去true类的softmax输出。当true类的softmax输出较低时,得分较高,即,当模型严重错误的时候。


每一个测试图片都会生成自己的预测集C
1.1共形预测说明
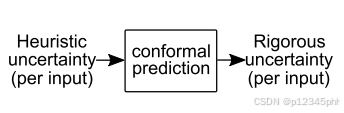
正如我们在总结中所说,保形预测并不特定于softmax输出或分类问题。事实上,共形预测可以被视为一种从任何模型中获取任何启发式不确定性概念并将其转换为严格概念的方法(见下图)。保形预测不关心潜在的预测问题是离散/连续还是分类/回归
接下来,我们概述一般输入x和输出y(不一定是离散的)的共形预测。

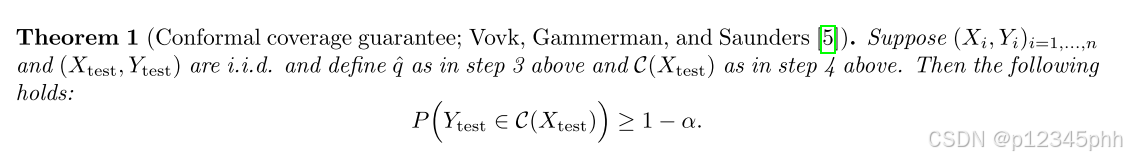
评分函数的选择
乍一看,这似乎好得令人难以置信,持怀疑态度的读者可能会问以下问题:即使基础模型的不确定性的启发式概念是任意糟糕的,如何可能构建一个统计上有效的预测集?
让我们通过一些直观的理解来补充附录D中证明的数学理解。大致来说,如果分数能够正确地将输入从模型误差的最低到最高进行排序,那么对于容易处理的输入,生成的预测集会较小;而对于难以处理的输入,预测集会较大。如果这些分数不好,即它们不能很好地近似这种排序,那么生成的预测集将是无用的。例如,如果分数是随机噪声,那么预测集将包含标签空间的一个随机样本,这个随机样本足够大以提供有效的边缘覆盖率。这说明了关于一致性预测的一个重要事实:尽管保证总是成立的,但预测集的实用性主要由评分函数决定。这应该不令人惊讶——评分函数几乎包含了我们对问题和数据的所有已知信息,包括基础模型本身。例如,在分类问题与回归问题上应用一致性预测的主要区别在于评分的选择。对于同一个基础模型,也有许多可能的评分函数,它们具有不同的属性。因此,构建合适的评分函数是一个重要的工程选择。接下来我们将展示几个好的评分函数的例子。
2 Examples of Conformal Procedures
在本节中,我们给出了在许多情况下应用的共形预测的例子,目的是为读者提供一个实际部署的技术库。请注意,在本节中我们将只关注一维Y,较小的conformal scores将对应于更高的模型置信度(此类分数称为nonconformity分数)。更丰富的设置,如高维Y,复杂(或多个)错误概念,或者不同的错误成本不同的金额,通常需要风险控制的语言,在A节中概述。
2.1 Classification with Adaptive Prediction Sets
让我们开始我们的例子序列,对第1节中的分类例子进行改进。以前的方法产生的预测集具有最小的平均大小[6],但它倾向于对困难子群体覆盖不足,而对容易子群体过度覆盖。在这里,我们开发了一种不同的方法,称为自适应预测集(APS),以避免这个问题。我们将遵循[7]和[4]。Adaptive Prediction Sets主要适用于多类别分类。

2.2 Conformalized Quantile Regression

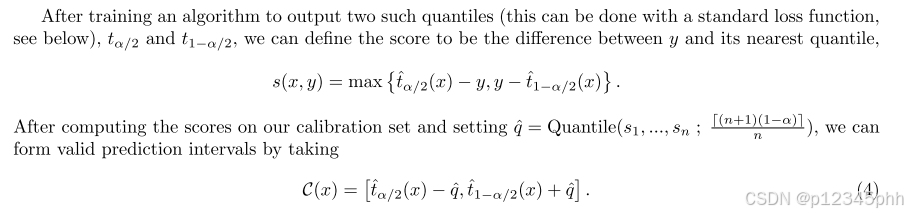

3 Evaluating Conformal Prediction
我们已经花了最后两节学习如何形成满足严格统计保证的有效预测集。现在我们将讨论如何评估它们。我们的评估将分为两类。
-
评估适应性。必须牢记,具有最小平均集大小的共形预测程序并不一定是最好的。一个好的共形预测程序会在简单的输入上给出较小的集合,在困难的输入上给出较大的集合,这种方式能够忠实地反映模型的不确定性。这种适应性不是由共形预测的覆盖率保证所隐含的,但在共形预测的实际部署中是必不可少的。我们将对适应性进行形式化定义,探讨其影响,并提出实际算法来评估它。
-
正确性检查。正确性检查帮助你测试是否已经正确地实现了共形预测。我们将通过实证检验覆盖率是否满足定理1。严格评估这一属性是否成立需要仔细考虑真实数据集中存在的有限样本变异性。我们开发了明确的公式来衡量良性波动的大小——如果观察到的覆盖率偏离1−α1−α的程度超过了这些公式所指示的范围,那么就说明实现存在问题。
我们建议的许多评估都是计算密集型的,需要在不同的数据分割上运行整个保形程序至少 100 次。当计算得分需要很长时间时,这些评估的直接实现可能会很慢。通过一些简单的计算技巧和策略性缓存,我们可以将这一过程的速度提高几个数量级。因此,为了帮助读者,我们在数学描述中穿插了有效实现这些计算的代码。
3.1 Evaluating Adaptivity
尽管任何保角预测程序都能得到满足(1)的预测区间,但这样的程序有很多,而且它们在其他重要方面也不尽相同。特别是,保角预测的一个关键设计考虑因素是适应性:我们希望程序在输入较难时返回较大的集合,在输入较易时返回较小的集合。虽然大多数合理的共形预测程序都能在一定程度上满足这一要求,但我们现在讨论的是适应性的精确指标,它能让用户检查共形预测程序,并比较多个可供选择的共形预测程序。
设定大小。第一步是绘制集合大小的直方图。这个直方图从两个方面帮助我们。首先,大的平均集合大小指示保形过程不是非常精确,指示分数或基础模型可能存在问题。其次,预测集大小的分布表明预测集是否适当地适应了示例的难度。一般来说,更宽的范围是可取的,因为这意味着该程序可以有效地区分易输入和难输入。
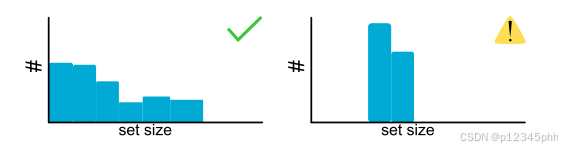
在绘制覆盖范围和集大小后,人们很容易停止评估,但某些重要问题仍然没有答案。集合大小的良好分布通常更好,但这并不一定表明集合适合X的难度。在看到集合大小具有动态范围之后,我们需要验证对于困难的示例是否会出现大集合。接下来,我们将形式化这个概念,并给出评估它的指标。
Conditional coverage.
自适应性通常是通过要求条件覆盖属性来实现的:![]()
也就是说,对于输入Xtest的每个值,我们都试图返回具有1 − α覆盖率的预测集。这是一个比(1)中的边际覆盖性质更强的性质,即保形预测保证是正确的-实际上,在最一般的情况下,条件覆盖是不可能实现的[14]。换句话说,保形过程不能保证满足(7),所以我们必须检查我们的过程有多接近它。
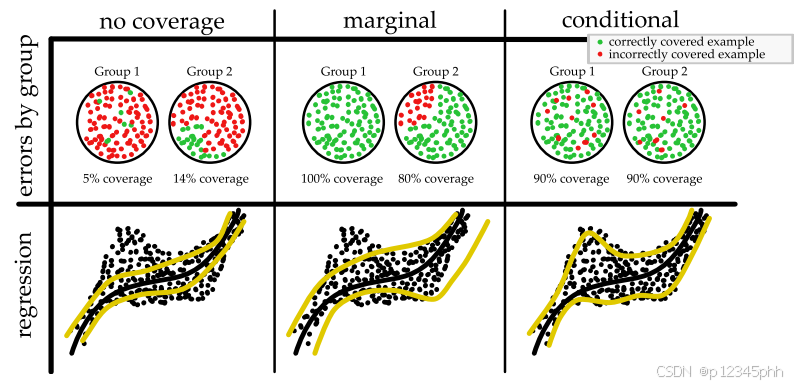
边际覆盖率和条件覆盖率之间的区别很微妙,但具有很大的实际重要性,因此我们将花一些时间来思考这里的区别。假设有两组人,A组和B组,频率分别为90%和10%。预测集总是覆盖A组中的人的Y,而当人来自B组时,从不覆盖Y。然后预测集有90%的覆盖率,但不是条件覆盖率。条件覆盖意味着预测集在两组中至少覆盖90%的时间。这是必要的,但不是充分的;条件覆盖是一个非常强的属性,它规定预测集的概率对于特定的人需要≥ 90%。换句话说,对于人群的任何子集,覆盖率应≥ 90%。图10显示了条件覆盖率和边缘覆盖率之间的差异。
3.2 The Effect of the Size of the Calibration Set
我们首先停下来讨论校准集的大小如何影响共形预测。我们考虑这个问题有两个原因。首先,用户必须为实际部署选择此选项。粗略地说,我们的结论是选择一个大小为n = 1000的校准集对于大多数目的来说是足够的。其次,校准集的大小是有限样本变异性的一个来源,我们需要分析它以正确检查覆盖率。我们将在下一节中以这里的结果为基础,在那里我们将完整地描述如何在实践中检查覆盖率。
校准集的大小n如何影响保形预测?(1)中的覆盖率保证对任何n都成立,因此我们可以看到,即使校准集非常小,我们的预测集的覆盖率也至少为1 − α。然而,直觉上,似乎更大的n更好,并导致更稳定的程序。这种直觉是正确的,它解释了为什么使用更大的校准集在实践中是有益的。细节是微妙的,所以我们仔细地通过他们在这里工作。其关键思想是,条件共形预测的覆盖率的校准集是一个随机量。也就是说,如果我们运行共形预测算法两次,每次采样一个新的校准数据集,然后检查无限数量的验证点的覆盖率,这两个数字将不相等。公式(1)中的覆盖率属性表明,在校准集中随机性的平均覆盖率至少为1−α,但对于任何一个固定的校准集,无限验证集上的覆盖率将是某个不完全是1 − α的数字。尽管如此,我们可以选择足够大的n,通过分析其分布来控制覆盖率的波动。
特别地,覆盖率的分布具有解析形式,该解析形式首先由弗拉基米尔·沃夫克在[14]中引入,即,
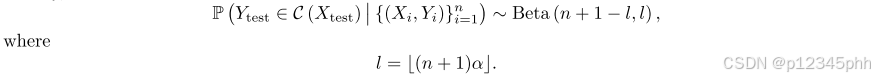
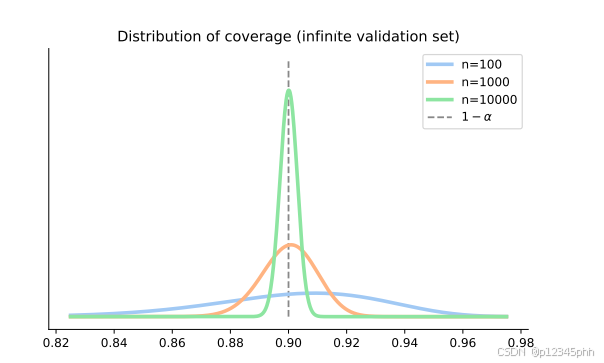
请注意,上面的条件期望是无限验证数据集的覆盖率,保持校准数据固定。这一事实的一个简单证明可在[14]中找到。我们在图11中绘制了几个n值的覆盖率分布。

3.3 Checking for Correct Coverage
作为一个明显的诊断,用户将希望评估conformal procedure是否具有正确的覆盖范围。这可以通过用新的校准和验证集在R个试验上运行该过程来实现,然后计算每个试验的经验覆盖率,
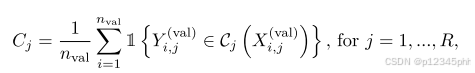
Cj的直方图应该以大约1 − α为中心,如图11所示。同样,平均值应该是1-α。
对于真实的数据集,我们总共只有n + nval个数据点来评估我们的保形算法,因此不能为每个R轮绘制新数据。因此,我们通过将n + nval数据点随机拆分R次到校准和验证数据集,然后运行保形来计算覆盖率值。请注意,与其多次拆分数据点本身,我们可以首先缓存所有保形分数,然后计算许多随机拆分的覆盖率值,如图12中的代码示例所示。
如果实施得当,保形预测保证满足(1)中的不等式。然而,如果读者在观察到的覆盖率中看到微小的波动,他们可能不需要担心:n,nval和R的有限性可以导致覆盖率的良性波动,这会给图11中的Beta分布增加一些宽度。附录C给出了分析C的平均值和标准差的精确理论。由此,我们将能够判断任何偏离1-α的情况是否表明实现有问题,或者它是否是良性的。在图12的随附的Swyter笔记本中提供了用于检查所有不同n、nval和R值下的覆盖率的代码。


















 3782
3782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









