






人工智能 (AI) 在自动心电图 (ECG) 分类中的应用不断吸引着研究界的兴趣,其成果令人鼓舞。 尽管它们前景广阔,但对其结果的稳健性的关注却有限,而稳健性是其在临床实践中实施的关键因素。 不确定性量化(UQ)对于值得信赖和可靠的人工智能至关重要,特别是在医学等安全关键领域。 机器学习 (ML) 模型预测中的不确定性估计已广泛用于单标签任务下的分布外 (OOD) 检测。 然而,UQ 方法在多标签分类中的使用仍未得到充分探索。 这项研究超越了开发高精度模型,在各种验证场景中使用相同的深度神经网络 (DNN) 架构比较五种不确定性量化方法,包括内部和外部验证以及 OOD 检测,以多标签心电图分类作为示例域。 我们展示了外部验证的重要性及其对分类性能、不确定性估计质量和校准的影响。 基于集成的方法比单一网络或随机方法产生更稳健的不确定性估计。 尽管当前的方法在准确量化不确定性方面仍然存在局限性,特别是在数据集变化的情况下,但将不确定性估计与带有拒绝选项的分类相结合可以提高检测此类变化的能力。 此外,我们表明,与随机抽样相比,使用不确定性估计作为主动学习环境中样本选择的标准可以更大程度地提高分类性能。
一、引言
机器学习在包括医学在内的各种决策关键领域取得了重大进展。 然而,随着这些进步应用于现实世界的安全关键型应用程序,将机器学习过程中存在的固有不确定性视为通往值得信赖的人工智能的道路至关重要[1]。 尽管人工智能研究在各个领域取得了有希望的成果,但人工智能在医疗领域的采用仍然是一个挑战[2]。 这可以归因于多种因素,包括对人工智能决策缺乏信任。 在医疗人工智能中,当存在高度不确定性时,必须有能力放弃做出决定。 这反映了在不寻常或复杂的病例中寻求第二意见的临床实践。 然而,当前文献中并未常规地讨论不确定性的量化和沟通,但它们在医疗保健应用中至关重要[3]。
另一个重要主题是多标签分类,其中可以将多个非排他性标签分配给每个实例,这与将单个标签分配给每个实例的多类或二元分类相反。 多标签的应用包括许多现实世界的问题,例如文本分类、音乐信息检索、图像分类和时间序列分析问题(例如心电图分类)。 尽管应用范围广泛,但将 UQ 纳入分析的多标签研究主要与图像识别 [4] 或文本分类 [5] 相关。 尽管如此,即使在上述应用中,UQ 的多标签分类仍然没有得到充分探索,并且使用的是基本技术 [6]。
先前在不确定性量化(UQ)领域的研究引入了众多技术,每种技术都针对特定的评估任务进行了定制。然而,由于缺乏标准化的评估不确定性估计的方法,这给不同应用中最合适技术的选择和比较带来了挑战。通过这项工作,我们旨在填补自动心电图(ECG)诊断领域中的这一空白。具体来说,我们在多标签分类设置中建立了各种UQ方法的比较,选择ECG分析作为我们的研究领域。专注于ECG分类的动机来自于大量公开可获取的多标签数据集的可用性,这使我们能够同时解决UQ和多标签分类的挑战。为了评估不确定性量化措施的稳健性,我们在内部、外部和分布外(OOD)验证集上对UQ方法进行了评估。此外,我们还考虑了不确定性估计的校准问题,这对于评估不确定性估计的可靠性至关重要。校准分析使我们能够定义基于阈值的可靠方法来拒绝具有高不确定性的样本,从而促进基于AI的方法在临床实践中的集成。
在这一背景下,除了比较不同的不确定性量化(UQ)方法外,我们在研究中还包括了一个临床模拟场景,以评估将AI不确定性估计方法整合到心脏病学实践中的益处,如图1所示。该系统基于一个具备不确定性感知能力的AI模型,该模型经过训练,能够根据12导联心电图(ECG)信号检测心脏病理状况。除了对心脏病理进行分类外,该模型还提供了其对给定样本预测的整体置信度,当存在大量不确定性时,模型会选择不提供诊断。对于低不确定性的预测,每个预测诊断会提供一个独立的置信度评分。通过这种能力,可以在那些被拒绝的样本上寻求额外的人类专家意见,这些样本后来可以用于重新训练模型,从而提升其性能。模型部署后的持续训练非常重要,因为环境不断变化,概念漂移很可能发生。在这种情况下,由于数据标注的成本较高,不确定性估计在选择最具信息量的样本进行标注方面发挥了重要作用。
贡献。 我们对多标签设置中的 UQ 方法进行了全面比较,重点关注 ECG 分类场景。 我们对各种验证场景中UQ方法的评估强调了外部验证的重要性及其对性能、不确定性估计质量和校准的影响。 此外,我们提供的经验证据表明,将 UQ 纳入整个机器学习流程可以在拒绝选项分类、数据集移位检测和主动学习方面带来优势。 这些贡献源于涵盖以下研究问题的研究路径:
• RQ1:内部验证的表现是否一致地再现于外部验证中?
• RQ2:外部验证如何影响模型预测的校准?
• RQ3:在不同验证策略下的多标签环境中,不确定性方法的可靠性如何?
• RQ4:使用样本拒绝对ECG 分类性能有何影响?
• RQ5:不确定性测量是否适合作为主动学习的选择标准?
本文其余部分的组织如下:第 2.1 节介绍了心电图分类的背景,第 2.2 节介绍了不确定性估计方法的背景以及相关工作。 第 4 节介绍了所用方法,第 5 节介绍了实验结果。 第 6 节和第 7 节讨论我们的发现并提出最终评论和结论。
二、相关工作
2.1心电图分类
这里不多介绍,就是有关机器学习深度学习的那些
2.2不确定性估计方法
不同的研究团体以不同的方式对不确定性进行分类。 然而,在机器学习和统计学文献中,人们通常区分不确定性的两种基本来源和类型,即任意不确定性和认知不确定性[1]。 任意不确定性是指因数据的复杂性、多模态和噪声而产生的随机性概念。 任意不确定性,也称为数据不确定性,无法减少或完全消除,因为它是生成数据的基础分布的属性,而不是模型的属性。 另一方面,认知不确定性表示由于缺乏对所建模的基础过程的了解而导致的不确定性,要么是由于与模型相关的不确定性,要么是由于缺乏数据。 原则上,可以通过提供更多知识来减少这种不确定性,即扩展训练数据、更好的建模或更好的数据分析。
虽然不同类型的不确定性应该以不同的方式测量,但机器学习中的这种区别最近才引起人们的关注 [1]。 例如,单独量化不确定性的能力已在主动学习中用作不确定性抽样的选择标准[29-31]。 在医学领域,Senge 等人的工作强调了这种区别。 [32],作者证明了他们的方法在医疗决策背景下的有用性。 各种不确定性量化方法已应用于不同的医疗应用,例如皮肤癌检测[33,34]、COVID-19检测[35,36]、癌症图像检测[37,38]等。
近年来,由于神经网络对其自身置信度的认识有限,人们开发了多种方法来使 DNN 具有纳入不确定性的能力 [39-42]。 贝叶斯神经网络(BNN)已被广泛使用,根据后验的推断方式,它们可以分为变分推断(VI)、采样方法或拉普拉斯近似[43]。 Bayes-by-Backprop [44] 是变分推理文献中广泛使用的算法的一个例子。 另一个重要的例子是 Gal 等人提出的 Monte Carlo (MC) Dropout。 [45],它用伯努利分布的乘积来近似后验。 这种方法已被应用于文献[46-48]的各种研究中,并且在其基础上建立了不同的扩展,例如drop connect方法[49],它被发现在不确定性表示方面更加鲁棒[43] ,50]。 另一方面,采样方法具有不受分布类型限制的优点,并且已经在文献中进行了研究,包括粒子滤波、拒绝采样、重要性采样和马尔可夫链蒙特卡罗采样(MCMC)等流行算法 [51,52]。 拉普拉斯近似首先由 Denker 和 LeCun [53] 提出,可以作为事后方法应用于已经训练的神经网络。 在文献中,最近的研究包括 Kristiadi 等人的工作。 [54] 或邓等人。 [55]。
除了随机近似之外,近似贝叶斯方法的另一种常见方法是通过集成[56,57]。 特别是,Lakshminarayanan 等人提出了一种流行的方法。 [56]其中在整个数据集上使用不同的参数初始化对同一网络进行独立训练。 奥斯班德等人。 [58] 和何等人。 [59]提出通过使用随机但固定的加性先验函数扰动每个模型的损失函数来训练集成。 德瓦拉切拉等人。 [60]利用先验函数和自举来改进不确定性估计。
单一确定性方法在深度学习文献中也很常见[61-64],其中单个前向传递生成通过使用附加(外部)方法导出或由网络直接预测的不确定性估计。 在 Malinin 等人的作品中。 [61]或Sensoy等人。 [65],所提出的神经网络经过明确建模和训练,以量化任意和认知不确定性。 在这些方法中,随着不确定性的量化,训练过程和网络的预测都会受到影响。 另一方面,一些研究认为不确定性量化和预测任务应该是两个独立的任务,以使不确定性量化保持公正[66]。 在这种背景下,Raghu 等人。 [66]和Ramalho等人。 [67],训练一个神经网络用于预测任务,另一个神经网络用于不确定性估计。 其他方法包括使用梯度度量来量化 OOD 检测的不确定性[68]。 此外,该领域一些更流行的方法包括隔离森林[69]、自动编码器[70]和局部离群值因子[71]。 在异常或异常值检测领域,我们重点介绍了一些代表性的工作,例如最大 Logit 分数 [72]、基于 Mahalanobis 距离的置信度分数 [73] 和能量 [74] 或用于多标签设置的联合能量 [ 6]。 尽管这些方法并不是为了明确量化不确定性而开发的,但它们可以被视为知识不确定性的衡量标准。
最近的工作对深度学习背景下的不确定性量化主题进行了全面的综述,例如 Abdar 等人的综述。 [75] 和 Gawlikowski 等人。 [43]。
2.3. 不确定性量化下的心电图分类
先前的心电图分类研究经常忽视与其估计相关的不确定性的评估和管理,主要关注分类性能,而不考虑实际应用中的实际实施。 洪等人。 对 PhysioNet/CinC Challenge 2020 [76] 进行了系统回顾,强调了处理未知类别和可解释性对于现实世界实施的重要性。 令人惊讶的是,2020 年挑战赛中排名前 10 的方法都没有解决这些关键主题。
虽然不确定性量化下的心电图分类的研究仍然有限,但最近的一些工作已经解决了这一领域,并总结在表 1 中。Belen 等人。 [77]采用变分编码器网络使用 MITBIH 心房颤动数据库对心房颤动进行分类。 他们的方法使用 KL 散度作为损失函数,通过多次在网络中运行输入并计算 softmax 概率的标准差来估计不确定性。 弗兰肯等人。 [78]探索了各种不确定性估计方法,包括蒙特卡洛丢失、变分推理、集成和快照集成。 他们使用基于排名的指标、校准评估和 OOD 检测来评估不确定性估计的质量。
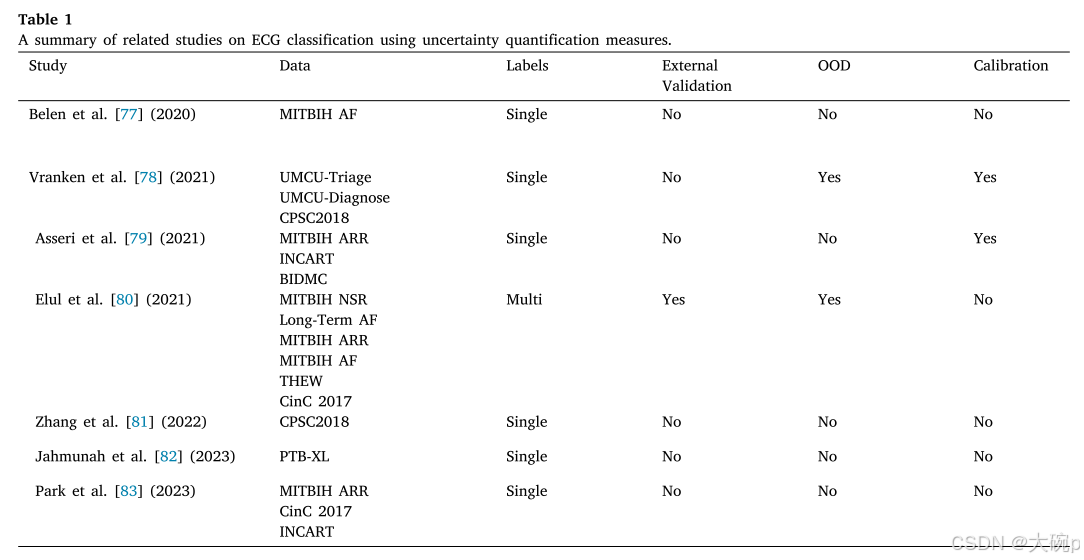
他们的结果显示,变分推理结合贝叶斯分解和带有辅助输出的集成方法在数据集上的排名和校准方面优于其他方法,无论是在分布内(in-distribution)还是分布外(OOD)设置中。Aseeri等人[79]开发了一个使用三种不同类型数据集训练的门控循环神经网络,并使用蒙特卡洛dropout和深度集成方法来估计不确定性。他们还评估了这些方法的不确定性校准,展示了所提出的网络在拒绝低置信度样本方面具有强大的能力,同时达到了与最先进方法相当的结果。Elul等人[80]进行了一项关于将AI整合到临床实践中的综合研究,强调了不确定性估计在处理OOD样本或多标签诊断中的重要性。他们开发了一个由10个二元分类器组成的深度学习模型,每个分类器针对一种训练的心电图病理状况,使模型能够输出任何已知节律的组合,并在模型对所有二元类别的预测均为负时处理未知类别。他们使用蒙特卡洛dropout方法来评估预测的置信度。Zhang等人[81]则采用带有蒙特卡洛dropout的贝叶斯神经网络进行心律失常分类,并引入了拒绝选项。他们使用基于熵的数据和模型不确定性分解来计算总不确定性,并探索不同的不确定性阈值,以通过拒绝高不确定性样本来提高分类性能。 贾穆纳等人。 [82]训练了具有反向 KL 散度的 Dirichlet DenseNet,以计算多类分类任务中模型不确定性的预测熵。 作者认为,与之前的不确定性量化方法相比,他们的方法速度更快,计算量也更轻。 此外,他们还在分析中加入了嘈杂的心电图。 最近,帕克等人。 [83]提出了一种基于自注意力的 LSTM-FCN 深度学习架构,使用深度集成方法来量化不确定性。 他们的结果达到了最先进的性能,表明认知不确定性对于对六种心律失常类型进行分类是可靠的。
尽管之前提出的研究中使用了一些多标签数据集,但除了 Elul 等人之外,所有这些数据集都采用了单标签分类方法。 [80]。 据我们所知,Elul等人的工作[80]是唯一在心电图分类中应用多标签方法下的UQ方法的工作。 虽然这项研究对处理混合类别的重要性进行了全面的解释,并表明他们的模型已准备好处理多标签设置,但没有对多标签数据集进行性能评估,因此很难彻底评估 他们的模型在这种情况下的表现。 此外,本研究仅使用蒙特卡洛Dropout方法作为不确定性量化方法。
此外,一些研究侧重于校准指标,其他研究侧重于 OOD 检测,还有一些研究侧重于外部验证。 然而,我们认为一个好的不确定性量化措施应该符合所有三个验证程序。 从这个意义上说,我们的工作重点是多标签数据集,不仅评估内部验证集,还评估外部集、OOD 和校准。
三、背景

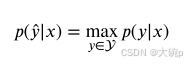
此外,预测后验分布的熵是最著名的单个概率分布的不确定性度量 [1]。对于离散类标签,熵由公式 (2) 给出:
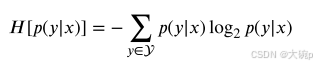
预测后验分布的最大概率和熵都可以被视为预测中总体不确定性的度量[61]。 这些概率分布不确定性的度量主要捕获分布的形状,因此主要关注总体不确定性的任意部分。
对于贝叶斯方法,预测后验分布由一组有限的蒙特卡罗样本或单个集合成员的预测来近似。 在这两种方法中,𝑀 预测的预测方差是各种研究中使用的认知不确定性的度量[77,78,80],并由方程式给出。 (3)。
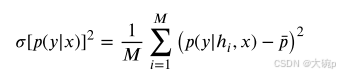
![]()
此外,除了考虑预测的概率方差,还可以考虑变异比率(variation ratios),这是一种衡量预测变化性的方法,通过计算具有正确输出样本的比例来实现 [86, 87]。这种启发式方法是测量预测围绕其众数的分散程度。对于给定的实例 x,有 M个输出预测,变异比率计算如下:
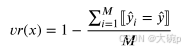
其中 y^对应于采样得到的多数类别,而 [y^i=y^] 是一个指示函数,当表达式为真时取值为 1,否则为 0。 此外,Depeweg 等人 [88] 明确尝试测量和分离随机不确定性(aleatoric uncertainty)和知识不确定性(epistemic uncertainty)。他们提出了一种使用经典信息论熵度量的方法来量化和分离不确定性。更详细地说,总不确定性(total uncertainty)是通过预测后验分布的熵来测量的,该分布由以下近似表示:

随机不确定性是通过考虑每个单独预测的平均熵来测量的,这些熵是分布的期望。固定假设 h 后,知识不确定性基本上被消除了。其近似值由 Eq. (6) 给出:
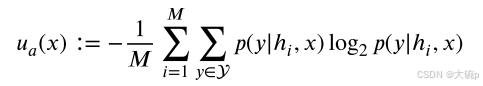
然后,知识不确定性是通过假设与结果之间的互信息来测量的,可以表示为总不确定性与预期数据不确定性的差异,后者由每个单独预测的预期熵捕获 [61]。
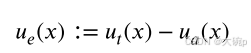
因此,如果对于具有高概率的不同假设 h,分布 p(y∣h)变化很大但导致相当不同的预测,则知识不确定性很高。这种方法在不同的研究中被使用,例如 [81, 89, 90]。
四. 方法
我们按照图2所示的步骤对各种不确定性量化方法进行了分析,并相应地划分了本节。 我们首先讨论所使用的数据集和数据预处理的注意事项。 随后,我们提供了有关神经网络架构及其不确定性估计变体的详细信息。 本节最后解释了验证,其中涉及三个不同的集合(内部、外部和 OOD)来评估方法、实施的评估措施以及不确定性方法的特定应用(带有拒绝选项的分类、数据集移位和主动 学习)。
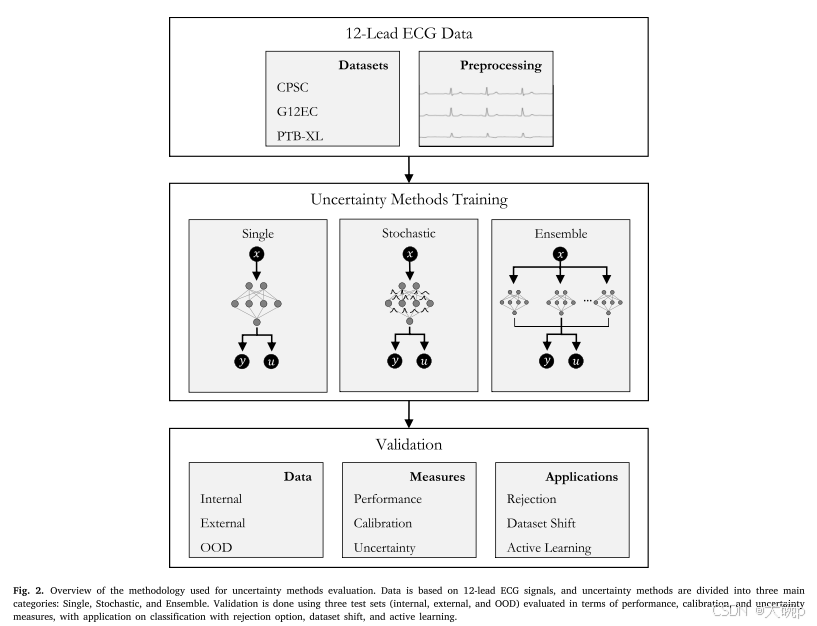
4.1. 数据集和预处理
对于数据集选择,我们的主要标准是选择包含 12 导联心电图数据的数据集。 2020 年 PhysioNet/CinC 挑战赛提供了来自四个不同数据源的 12 导联多标签心电图数据集。 然而,由于我们的验证程序涉及使用不同数据源的内部和外部验证,因此我们无法使用 PhysioNet/CinC Challenge 2020 选择的标准 27 个类别(共 111 个类别),因为并非所有类别都存在于每个数据集中 。
因此,我们决定仅利用数据集中常见的类。 这种方法产生了在整个 CPSC 数据集中表示的九个类别(NSR、AF、IAVB、LBBB、RBBB、PAC、VEB、STD 和 STE),使我们能够在不同的数据集中进行一致的验证。 此外,这九个类可在三个不同的数据源中使用。 第一个来源是2018年中国生理信号挑战赛(CPSC)[19],第二个来源是来自德国不伦瑞克的Physikalisch Technische Bundesanstalt XL(PTB-XL)[22],第三个来源是乔治亚州12导联心电图挑战赛( G12EC)[91] 数据库,埃默里大学,亚特兰大,佐治亚州,美国。 这三个数据集包含来自 12 导联心电图信号、人口统计信息(年龄和性别)和多标签注释的数据。 数据库之间的注释之前已由 PhysioNet/CinC Challenge 2020 标准化。但是,按照 PhysioNet/CinC Challenge 2020 的评估程序,我们将 G12EC 和 PTB-XL 数据集中的 CRBBB 类重新标记为 RBBB。
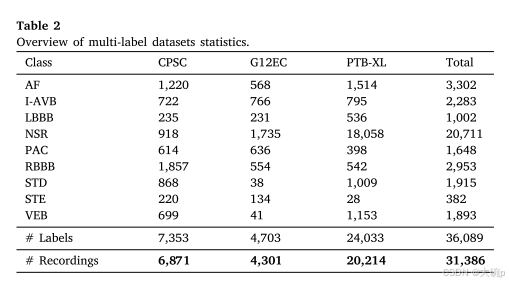
对于心电信号预处理,由于每个数据集的不同特征,预处理包括250 Hz的重采样机制和10 s长的截断。 对于超过 10 s 的心电信号,选择窗口中心的 10 s。 选择在窗口中心使用 10 秒是因为某些心电图信号开始和结束时的信号质量较差。 此外,每个 ECG 信号均使用 1 至 40 Hz 之间的二阶带通巴特沃斯滤波器进行滤波,并通过整个数据集的 z 归一化进行归一化。 表 2 总结了每个类别和数据集使用的 ECG 数据。 该表包含有关每个数据集的标签和记录数量的信息。
4.2. 不确定测量方法
如前所述,这项工作的主要目标不是探索更好的模型架构或提高已开发方法的准确性。 相反,我们的目标是了解不确定性测量作为实际心电图分类领域中的安全机制的潜在用途。 因此,作为基线架构,我们决定使用所提出的神经网络架构,该架构在中国生理信号挑战赛中排名第一[13]。 该模型是五个 CNN 块的组合架构,后面是双向门控循环单元 (GRU)、注意力层和最后的密集层。 欲了解更多详细信息,请参阅陈等人。 [13]。 训练是使用 Adam 优化器完成的,学习率为 0.001。 为了抵消数据中的类别不平衡,使用二元焦点损失作为损失函数,并将聚焦参数设置为 1。使用大小为 64 的小批量进行 100 个 epoch 的训练。最好的模型是具有选择验证集上的最小损失作为不确定性方法的基线。
对于随机方法,我们实现了 MC Dropout 和拉普拉斯近似,以使其易于实现,并在训练逻辑上略有改变。 对于 MC Dropout,使用相同的经过训练的网络而无需重新训练,因为基线架构包含 dropout 层。 在测试中,dropout层保持活跃,并使用了15个MC样本。 对于拉普拉斯近似,还使用了相同的训练网络,因为该方法可以事后应用于使用指数族损失函数和分段线性激活函数的训练神经网络[4]。 因此,为了近似神经网络参数上棘手的后验分布,我们使用了 Rewicki 等人的实现。 [4]在多标签场景下开发并公开。与MC Dropout类似,使用15个样本进行测试。
对于集成方法,Lakshminarayanan 等人引入的流行方法。 [56]选择使用不同的参数初始化对同一网络进行独立训练。 我们将这种方法称为 DeepEnsemble。 此外,还训练了基于引导方法的集成。 两种方法均由 15 名单独的集成成员组成。
关于用于量化随机不确定性和/或知识不确定性所采用的措施,我们根据是否使用单个网络或贝叶斯近似而选择了不同的方法。对于单一模型,随机不确定性估计基于最大概率和(Shannon)熵来计算。对于知识不确定性,我们选择了旨在改进异常检测(OOD, Out-of-Distribution)不确定性估计的基础方法,具体包括联合能量(Joint Energy)、最大Logit、孤立森林(Isolation Forest)、局部异常因子(Local Outlier Factor),以及基于马氏距离的置信度评分。对于贝叶斯近似,我们则使用了最大概率、预测方差、变异率,以及将基于熵的措施分解为随机不确定性和知识不确定性。
图3展示了应用于这些方法之上的不确定性估计方法及相应的不确定性度量的总结。需要注意的是,在计算直接依赖于类别概率的不确定性度量时,我们假设标签之间是独立的。例如,熵度量是在每个标签的二元场景中应用的,这导致每个标签都有一个对应的不确定性度量。为了考虑跨标签的联合不确定性,我们将各个标签的不确定性度量相加。
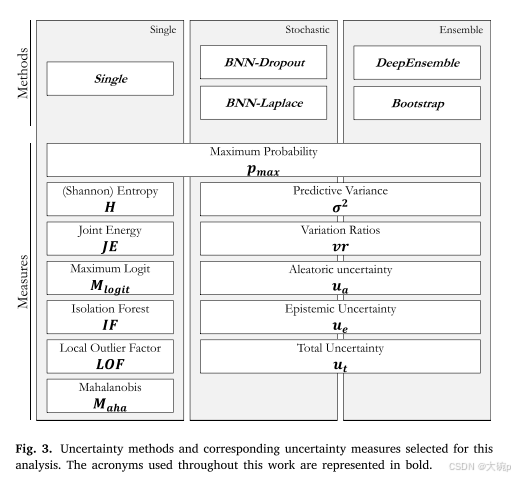
对于单一模型:
- 最大概率和熵:
- 最大概率:选择模型最有信心的那个答案。比如,如果模型认为某个东西是猫的概率为90%,那么它就很有信心这是个猫。
- 熵:用来衡量模型的“混乱度”。如果模型对所有选项都不是很确定,那么熵值就会比较高。
对于贝叶斯近似:
- 预测方差、变异率等:
- 预测方差:类似于看不同专家的意见有多大差异。
- 变异率:查看不同预测之间的分歧比例。
- 分解熵:将总的不确定性拆分为随机不确定性和知识不确定性两部分。
其他方法:
- 联合能量、最大Logit、孤立森林、局部异常因子、马氏距离:
- 这些都是用来检测异常数据点的方法,帮助识别模型不太熟悉的数据类型。比如,如果你给一个只见过猫和狗的模型展示了一只鸟的照片,这些方法可以帮助判断模型是否遇到了陌生的东西。
标签独立性假设
在计算某些不确定性度量时,我们会假设每个标签(分类结果)之间是相互独立的。这意味着我们在评估每个类别时不会考虑其他类别的影响。例如,在一个多标签分类问题中,如果我们有“猫”、“狗”和“鱼”三个标签,我们会分别计算每个标签的不确定性,然后再把这些单独的不确定性加起来得到总的结果。
4.3. 验证方法
4.3.1. 训练、验证和测试集
为了评估训练模型的泛化能力,我们对三个不同的测试集进行了评估,重点关注分类性能、校准和不确定性度量的质量。 对于模型训练和内部验证,我们使用 CPSC 数据集,采用 80-10%-10% 的训练-验证-测试分割。 为了确保每组中的类别标签、性别和年龄信息的均匀分布,我们使用这些标准作为分割因子。 对于外部验证集,我们使用 G12EC 和 PTB-XL 数据集。
此外,为了评估不确定性量化,我们还考虑了两个异常检测(OOD, Out-of-Distribution)数据集。由于我们并没有使用所有数据集中可用的类别进行模型训练,因此我们选择了一组未知类别作为异常检测类别。为此,我们利用了PTB-XL数据集[22]提供的诊断标签的层次结构,这些标签分为粗略的超级类别(superclasses)和子类别(subclasses)。为了减少诊断标签之间的相似性,我们选择了心肌梗死(Myocardial Infarction, MI)超级类别和肥厚(Hypertrophy, HYP)超级类别作为异常检测数据集。由于在这个标签集合中可能存在已知类别和未知类别的混合,我们移除了所有包含已知类别与这些未知类别混合的记录,以确保异常检测数据集仅包含未知类别。
-
选择异常检测数据集:
- 目的:为了测试模型在遇到未曾见过的数据时的表现,研究人员需要一些“异常”的数据集。这些数据应该不同于模型训练时使用的常规数据。
- 方法:他们从PTB-XL数据集中选择了两个特定的超级类别——心肌梗死(MI)和肥厚(HYP),作为异常检测数据集。这两个类别之所以被选中,是因为它们与其他训练数据中的类别差异较大,从而可以更好地检验模型的泛化能力。
-
去除混合类别:
- 问题:有时候,一个病人的记录可能同时包含已知类别和未知类别。例如,某个病人既有心肌梗死(未知类别),也有其他模型训练过的疾病(已知类别)。
- 解决办法:为了避免混淆,研究人员决定移除所有那些既包含已知类别又包含未知类别的记录。这样做是为了确保异常检测数据集只包含完全未知的类别,这样可以更准确地评估模型对真正未知数据的反应。
-
为什么这样做?
- 提高评估准确性:通过确保异常检测数据集仅包含未知类别,研究人员可以更精确地评估模型在面对完全陌生数据时的性能。
- 模拟真实世界情况:在实际应用中,医疗诊断模型可能会遇到它从未见过的病症。这种设置可以帮助研究人员了解模型在这种情况下会表现如何,并找出改进的方法。
因此,以下测试集用于评估目的:
- IN (CPSC):用于内部验证的测试集,即来自与训练集相同的数据源的独立测试。 该集合总共包含 687 个录音,其类别标签比例与表 2 中确定的相同;
- EXT (G12EC):G12EC 数据集中的整个数据集用于外部验证,总共包含 4301 个记录;
- EXT (PTB-XL):PTB-XL 数据集中的整个数据集用于外部验证,总共包含 20,214 个记录;
- OOD-MI:OOD 数据集,包含 PTB-XL 数据集中的 IMI、AMI、LMI 和 PMI 诊断标签,总计 2214 条记录。
- OOD-HYP:OOD 数据集,包含 PTB-XL 数据集中的 LVH、LAO/LAE、RVH、RAO/RAE 和 SEHYP 诊断标签,总计 1553 条记录。
提供的缩写将指实验分析期间的每个测试集。
4.3.2. 评价措施
量化不确定性方法的经验评估是一个复杂的问题,因为缺乏真实的不确定性信息。一种常见的间接评估预测不确定性度量的方法是评估这些度量在提高分类性能方面的有用性。在这个意义上,可以使用基于排序的方法来评估不确定性度量是否能够根据自身的不确定性估计对预测进行排序。其思路是评估随着拒绝比例增加,分类性能如何变化。如果某个度量能很好地量化自身的不确定性,那么分类性能应该随着拒绝比例的增加而提升。这种方法只能直接应用于比较使用相同预测模型的不同不确定性度量,因为分类性能曲线不仅取决于不确定性排序,还取决于预测模型本身的性能。尽管应用的不确定性方法基于相同的模型架构,但由于每种方法的具体细节不同,分类性能会略有差异。因此,为了公平地比较不同的不确定性度量,我们将使用“置信-Oracle曲线下面积”(AUCO, Area Under the Confidence-Oracle error)[92],它计算的是理论上的完美排序与每个不确定性度量所做排序之间的区域。
-
背景问题:
- 评估机器学习模型输出的不确定性是非常重要的,但这是一个复杂的问题,因为我们通常没有关于真实不确定性的“地面实况”数据。
-
间接评估方法:
- 一种间接评估不确定性度量的方法是看这些度量能否提高分类性能。例如,一个好的不确定性度量应该能够在高不确定性的情况下建议拒绝(即不作出预测),从而提高剩余预测的准确性。
-
基于排序的评估方法:
- 这种方法关注的是不确定性度量是否能正确地按照预测的不确定性大小对预测结果进行排序。理想情况下,最不确定的预测应该排在最前面,被最先拒绝。
-
拒绝百分比的影响:
- 随着我们选择更高比例的预测进行拒绝(即只保留那些我们认为最确定的预测),我们应该看到整体分类性能的提升。这是因为我们去除了那些我们不太确定的预测,而这些预测可能是错误的。
-
公平比较的重要性:
- 如果要公平地比较不同的不确定性度量,我们需要确保所有度量都是基于相同的预测模型。否则,任何性能上的差异都可能归因于模型本身而不是不确定性度量。
-
AUCO(置信-Oracle曲线下面积)错误率:
- AUCO是一种用来衡量不确定性度量排序质量的指标。它计算的是理想的、完美的排序(Oracle,即总是正确的排序)与实际的不确定性度量给出的排序之间的差距。
- 理想的排序意味着所有的错误预测都被正确地标记为高不确定性,并且会被首先拒绝。AUCO越小,表示不确定性度量越接近这种理想的排序能力。
oracle置信曲线代表了根据预测的置信度进行排序的最佳可能顺序,其中真正的错误决定了排序。AUCO值是通过计算给定不确定性估计与oracle置信曲线之间的差异曲线下的面积来得出的。更小的AUCO值表明给定的不确定性估计更接近oracle 置信曲线,因此是一个更好的不确定性预测器。AUCO的公式如下:
![]()

基于模型给出的不确定性估计所做出的排序
这种方法依赖于模型提供的置信度或不确定性估计来对预测进行排序。机器学习模型通常会输出一个概率分布或者直接提供一个置信分数,表示它对自己预测的信心程度。基于这个信息,我们可以将所有预测按照置信度从低到高或从高到低排列。例如:
- 如果一个分类器认为某个预测有95%的概率正确,那么这个预测就会被排在那些置信度较低的预测之前。
- 对于回归问题,模型可能会提供一个预测值及其相关的方差,方差越大意味着不确定性越高。
基于真实错误率的理想排序(神谕置信曲线)
理想排序是指如果知道每个预测的真实标签后,根据这些标签计算出的实际错误率来进行的排序。在这种情况下,“神谕”意味着我们拥有完美的知识,可以准确地知道哪些预测是正确的,哪些是错误的。然后,我们可以根据预测是否正确以及错误的程度来排序预测结果。例如:
- 所有错误的预测应该排在最前面,因为它们是最不可信的。
- 正确的预测则根据它们与真实值的接近程度进一步排序,越接近真实的预测置信度越高。
在我们的研究中,我们也采用了阈值依赖的度量方法,采用的是最近研究中用于评估不确定性估计的方法,该方法基于二元混淆矩阵的概念 [35,93]。在这种情况下,预测被分类为正确或不正确,并且根据一个设定的阈值,预测还被分类为确定或不确定。因此,可以识别出四种组合:(i) 真正确定(True Certainty, TC):正确且确定;(ii) 真正不确定(True Uncertainty, TU):不正确且不确定;(iii) 假不确定(False Uncertainty, FU):正确但不确定;以及 (iv) 假确定(False Certainty, FC):不正确但确定。基于这些组合,我们使用以下公式计算了不确定性准确率(Uncertainty Accuracy, UAcc)、不确定性敏感性(Uncertainty Sensitivity, USens)、不确定性特异性(Uncertainty Specificity, USpec),以及不确定性精度(Uncertainty Precision, UPrec):

基于排序的方法是比较不同不确定性估计的重要度量,但它们不考虑不确定性所表达的实际值。在这种意义上,可以使用校准度量来评估观察到的经验频率是否与输出的概率分布一致。因此,为了测量校准,使用了可靠性图(reliability diagram)和预期校准误差(Expected Calibration Error, ECE)作为校准度量。可靠性图在𝑦轴上表示准确性,在𝑥轴上表示平均置信度。一个完全校准的模型输出的概率应该与准确性相匹配,产生一条对角线,其中置信度等于准确性。此外,还计算了ECE以衡量置信度和准确性之间期望差异。
常见的校准度量
-
可靠性图(Reliability Diagram):
- 可视化工具,显示了模型的平均置信度(x轴)与其实际准确性(y轴)之间的关系。
- 一个完全校准的模型会在图表上形成一条45度角的线,表示每个置信度级别的预测准确性等于该置信度。
- 如果曲线偏离这条对角线,说明模型存在校准问题:位于对角线下方表明过度自信(overconfident),而位于上方则表明不够自信(underconfident)。
-
预期校准误差(Expected Calibration Error, ECE):
- 数值指标,量化了模型在整个预测范围内的平均非校准程度。
- 计算方法是将所有预测按置信度分组(通常称为“桶”或“bins”),然后计算每个桶内置信度与准确性的差异,并对这些差异取加权平均。
- ECE越低,表示模型的校准越好;理想情况下,ECE应接近于0。
-
最大校准误差(Maximum Calibration Error, MCE):
- 表示最差情况下的非校准程度,即所有置信度区间中置信度与准确性之间最大差异。
- MCE提供了模型最极端非校准行为的信息,对于了解模型在极端情况下的表现很有用。
4.3.3. 应用
对于带有拒绝选项的分类,不确定性度量被用作拒绝的度量。 拒绝阈值是使用训练数据获得的,其中选择给定的不确定性训练百分位数来拒绝测试数据上的样本。 因此,对于每个测试样本,计算不确定性并与定义的阈值进行比较。 如果获得的不确定性值大于阈值,则拒绝样本并且不进行预测。 另一方面,如果不确定性低于阈值,则模型接受预测,并且还会返回置信水平。
对于数据集移位验证,应用统计散度度量 Wasserstein 距离 [94] 来测量内部和外部数据集之间的数据集相似性。 使用 Wasserstein 距离 [94] 的 Wasserstein-1 版本,由下式给出:

假设你有两个图像数据集 A 和 B,都包含猫和狗的图片。你可以这样做:
- 特征提取:使用预训练的 CNN 提取每张图像的特征向量。
- 构建分布:对每个数据集,使用 KDE 或 GMM 来构建特征空间中的概率分布。
- 计算 Wasserstein 距离:根据两个数据集的概率分布,计算 Wasserstein 距离,评估它们之间的相似性。
对于主动学习(Active Learning)验证,样本是根据它们的不确定性值进行排序的,并且选择不确定性最高的n个样本用于重新训练模型。这个过程使用不同的不确定性来源进行,并与随机抽样方法进行比较。评估是基于分类性能指标的改进来进行的。
五. 实验结果
实验结果的组织是为了解决前面介绍的五个研究问题。
5.1. 外部验证
RQ1:内部验证的性能是否能够在外部验证上得到一致再现?
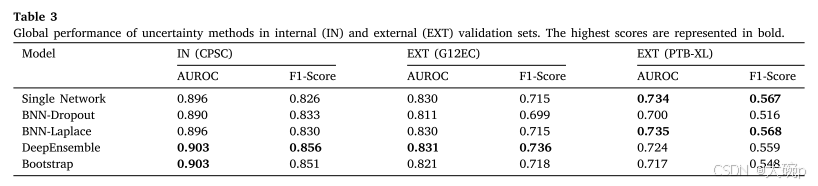
尽管所有不确定性方法都共享相同的深度学习架构,但它们之间的训练或测试程序的差异可能不仅会影响不确定性估计,还会影响预测性能。 为了正确评估这些不确定性方法,我们首先在内部和外部验证中展示每种方法的分类性能。 表 3 比较了内部和外部验证期间每种方法的 AUROC 和 F1 分数。 比较表明 DeepEnsemble 方法的性能略优于其他方法。 然而,所有方法在同一测试集中实现的性能相似。 表 3 还显示了外部验证期间性能的显着下降,特别是在 PTB-XL 数据集中。
为了分析数据集之间的类级别性能,使用 PhysioNet/CinC Challenge 2020 提供的实现计算每个数据集的二元多类、多标签混淆矩阵。由于所有方法都展示了可比较的性能测量,因此我们仅呈现混淆情况 图 4 中 DeepEnsemble 方法的矩阵。这些混淆矩阵表明,在两个外部数据集中,STE 和 STD 诊断都被准确识别。 相比之下,捆绑分支块(LBBB 和 RBBB)在内部和外部数据集上保持一致的性能。
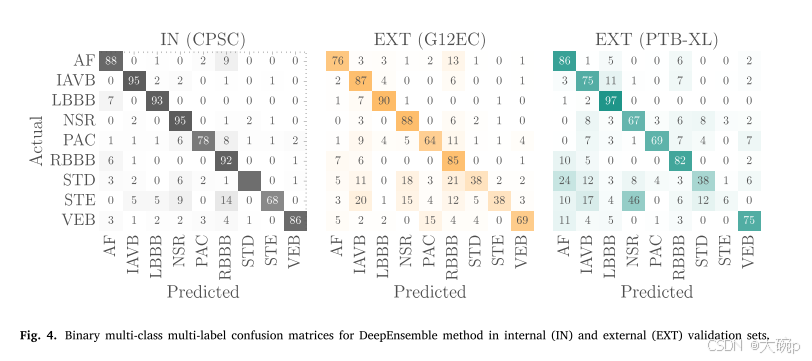
数据相似性与跨数据集泛化性能之间的相关性已被确认为一个强有力的指标,表明这些数据集可能源自不同的分布。因此,关于相似性的信息可以提供宝贵的见解,帮助理解为什么机器学习模型在外部数据集上表现出较差的性能 [95]。图5展示了性能下降与Wasserstein距离之间的相关性,使用了三个数据集进行说明。在混淆矩阵(图4)中观察到的最差类别性能也对应于具有较高Wasserstein距离的情况。计算出的皮尔逊相关系数(r=−0.92)表明,在外部数据集中可能存在潜在的偏移(依赖于标签),并且Wasserstein距离在检测这种偏移方面非常有用。除了STE和STD类别外,来自PTB-XL数据集的NSR(正常窦性心律)类别相较于CPSC和G12EC数据集中的同一类别,也表现出更高的距离和显著的性能下降。
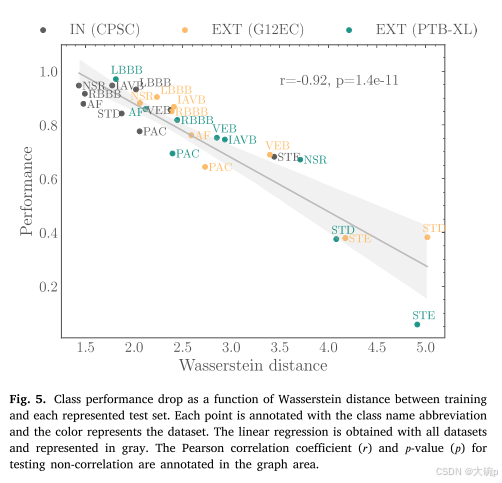
基于这一观察,我们对 NSR 类标签进行了彻底检查,发现三个数据集的 NSR 注释存在显着差异。 为了与训练数据集的注释保持一致,只有 PTB-XL 数据集中的 NSR 类的子集将用于其余的分析。 我们将此子集称为 PTB-XL*。 全面的解释和获得的结果可以在附录 A 中找到。
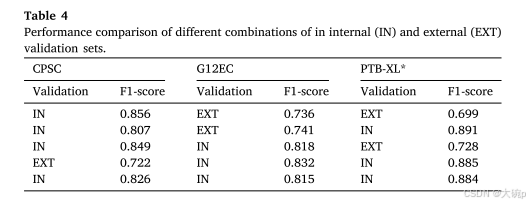
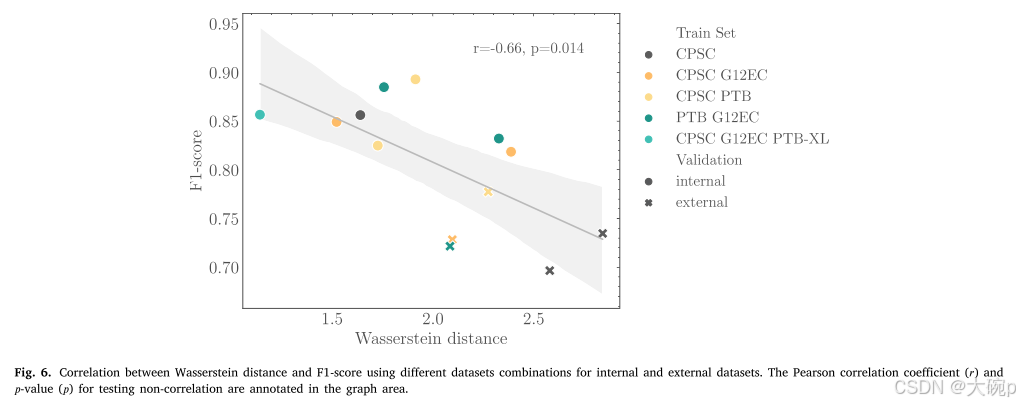
表 4 展示了内部和外部集合的各种组合的性能结果,图 6 展示了 Wasserstein 距离与不同组合的全局模型性能之间的相关性。 所有模型都遵循相同的训练程序,如第 4.2 节所述。 使用独立的验证集进行内部验证,使用公开的数据分区或 80-10%-10% 的训练-验证-测试分割,以类别标签、性别和年龄作为分割标准。 无论组合如何,内部验证集的性能始终高于 0.80,而外部验证集的性能低于 0.75。 尽管如此,纳入额外的数据集进行训练可以提高外部数据集的性能。
5.2. 校准
RQ2:外部验证如何影响模型预测的校准?
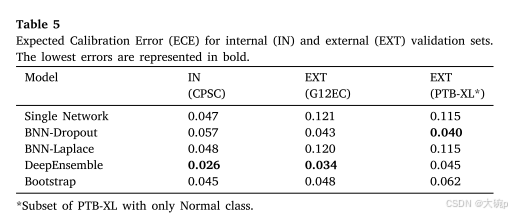
表 5 显示了所有不确定性方法和数据集的 ECE。 可靠性图如图 7 所示。对于这两种测量,都使用了 10 个容器。 与单一网络相比,所有不确定性方法都实现了相同或更低的 ECE,内部验证中的 BNN-Dropout 是唯一的例外。 DeepEnsemble模型在CPSC和G12EC数据集中获得了最低的ECE,而BNN-Dropout在PTB-XL中获得了最低的ECE。 BNN-Laplace 是效率最低的不确定性方法,表现出与单一网络类似的结果。 从可靠性图中,我们可以观察到单一网络和 BNN-Laplace 表现出类似的行为,它们的估计在所有数据集上都过于自信。 两种集成方法在所有数据集中都显示出相似的行为,其中 DeepEnsemble 在各种数据集中似乎更加稳健。
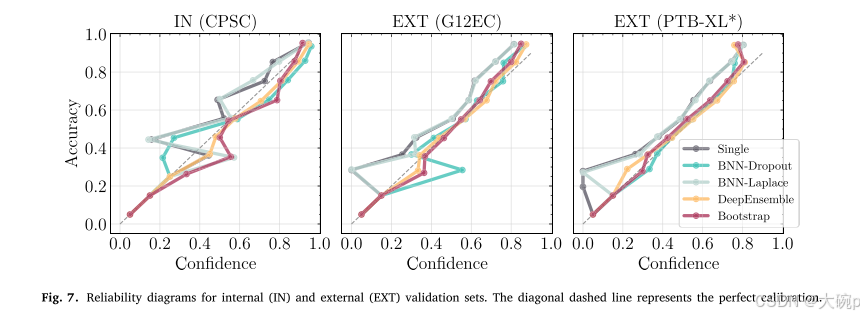 5.3. 不确定度评估
5.3. 不确定度评估
RQ3:在不同验证策略下的多标签环境中,不确定性方法的可靠性如何?
作为最初的说明性可视化,我们使用图 8 中的 DeepEnsemble 方法呈现了内部、外部和 OOD 数据集的总体不确定性。不确定性值已标准化为其最大理论值,确保所有不确定性测量都限制在以下范围内: 0 和 1。值得注意的是,无论采用何种不确定性度量,所有度量都会持续增加总体不确定性。 理想情况下,我们希望不确定性值的增加与之前观察到的分类性能的下降相一致。 换句话说,我们期望不确定性值在不同的外部验证(以及 OOD 数据)下尽可能保持一致,以表明模型在预测给定输入时是不确定的。
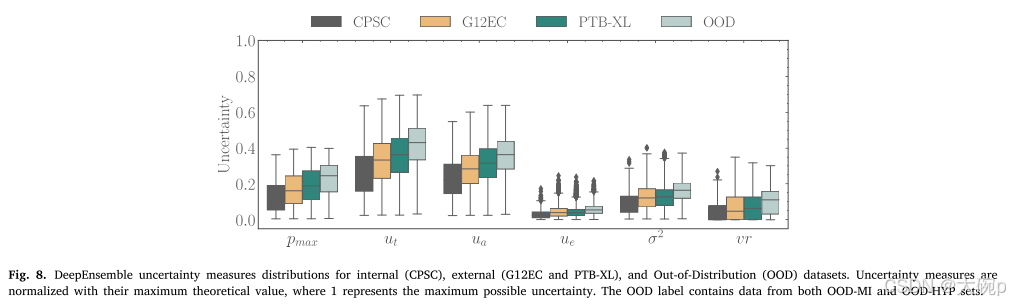
除了评估数据集之间的不确定性之外,还可以统计评估正确和错误分类样本的不确定性值分布之间的关系。 在多标签设置中,我们可以考虑两种场景:(1)标签依赖场景,其中整个标签组合被视为正确或不正确,以及(2)标签独立场景,其中每个类都被处理 作为一个单独的二元分类问题。 图 9 以 DeepEnsemble 为例说明了这两种场景的分布。 与标签依赖场景相比,标签独立场景的不确定性分布显示出正确分类样本和错误分类样本之间更明显的区别。 当对未配对组应用非参数 Mann–Whitney U 统计检验 [96] 时,发现两种方法在 0.05 显着性水平上均具有统计显着性(即使经过 Benjamini–Hochberg p 值校正 [97])。 除了使用 Cohen 的 d 效应大小 [98] 评估实际意义之外,我们还计算了每种方法的效应大小。 发现标签独立方法可以产生更大的效应量。 完整的结果可以在附录 B 中找到。 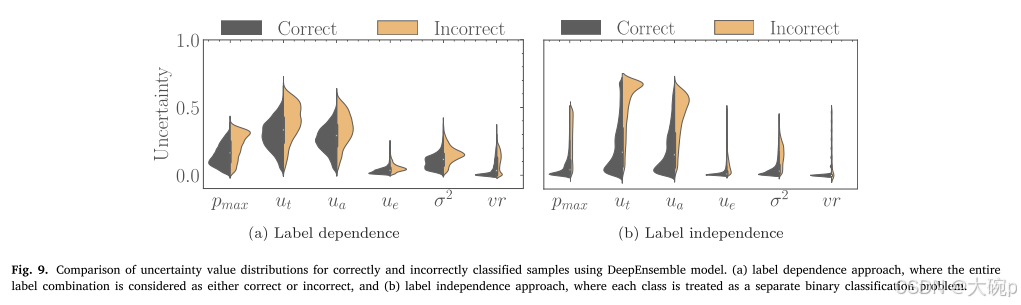
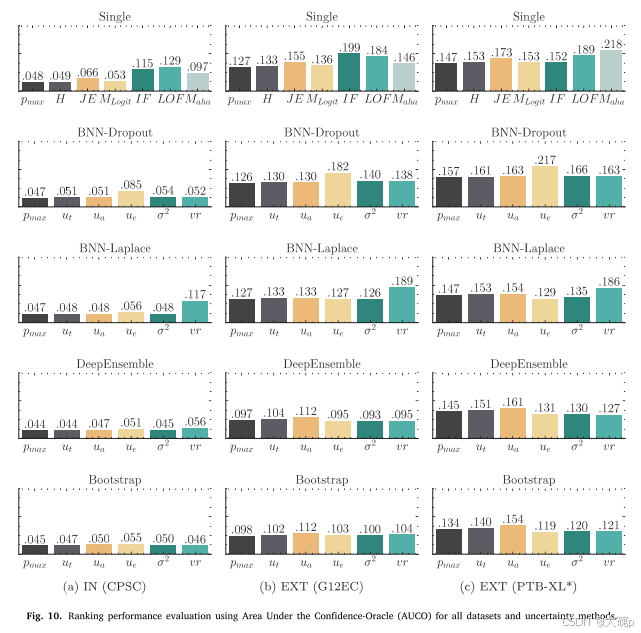
为了能够公平比较所有不确定性方法及其相应的度量,针对内部和外部测试集计算了 AUCO 指标。 AUCO 值越小表示性能越好。 图 10 显示了结果,相同的颜色代表不同方法的相同不确定性测量。 除了内部和外部验证之间的性能差异之外,图10还清楚地说明了不确定性估计措施在外部验证中受到影响。 一般来说,与其他方法相比,基于集合的不确定性度量在保留正确的不确定性排序方面显得更加稳健,并且认知不确定性度量在外部验证中优于任意不确定性度量。 在内部验证中,最大概率 (𝑝𝑚𝑎𝑥) 在所有方法中实现了最低的 AUCO。 这在某种程度上是预料之中的,因为内部数据集表现出较低的认知不确定性,与外部验证数据集不同。 还值得注意的是,在基于排名的分析中,OOD 检测措施(𝐽𝐸、𝑀𝐿𝑜𝑔𝑖𝑡、𝐼𝐹、𝐿𝑂𝐹、𝑀𝑎ℎ𝑎)的表现不如其他方法。 尽管不确定性估计和 OOD 检测之间存在密切关系,但排序不确定性值和检测 OOD 不是同一个问题,这可能解释了这些方法的性能较低。
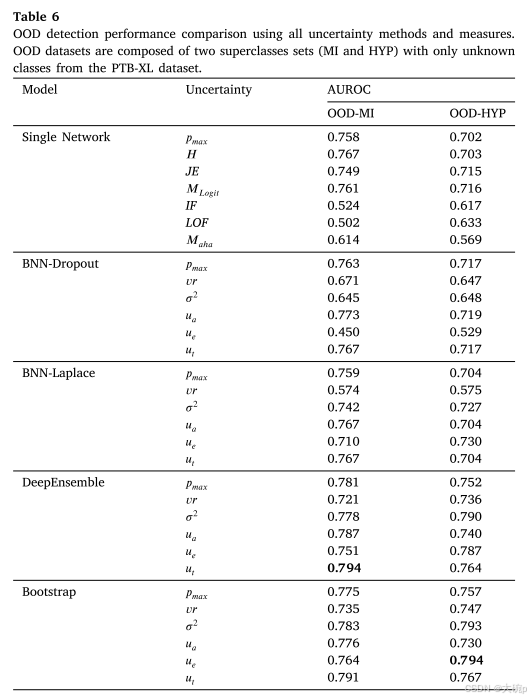
关于 OOD 检测,来自 PTB-XL 数据集的两个超类集(MI 和 HYP)仅由未知类组成,被用作 OOD 样本。 AUROC 是用 OOD 样品作为正实例、内部 CPSC 测试样品作为负实例来计算的。 获得的结果如表 6 所示。与之前的分析一致,集成方法在 AUROC 方面优于其他方法。 对于 MI 集,总不确定性 𝑢𝑡(或单一方法的熵 𝐻)在所有方法中实现了最高的 AUROC。 相反,对于 HYP 集,认知不确定性 𝑢𝑒 为集成方法和 BNN-Laplace 产生了更高的 AUROC 值。 至于专为 OOD 检测而设计的方法(JE、IF、LOF),其区分 OOD 样本的性能却出奇的差。
虽然 OOD 问题通常指的是异常和/或异常值检测,其中 OOD 样本来自完全不同的分布,但在我们的设置中,OOD 样本由来自相同数据集的类组成,因此与与开放集相关的新颖性检测更相关 识别 (OSR) 场景。 尽管 OSR 与 OOD 检测类似,但解决起来可能更具挑战性,因为新类的统计数据通常类似于数据集中现有类的统计数据 [99]。
5.4. 带有拒绝选项的分类
RQ4:使用样本拒绝对 ECG 分类性能有何影响?
在前面的部分中,我们比较了使用与阈值无关的度量的各种不确定性估计方法。 然而,为了评估整合人工智能不确定性估计方法在支持心脏病学医疗决策方面的好处,必须建立一个置信阈值。 该阈值使分类器能够在高度不确定的情况下放弃。 阈值的选择限制了方法之间的比较,因为每种方法可能具有不同的最佳阈值。
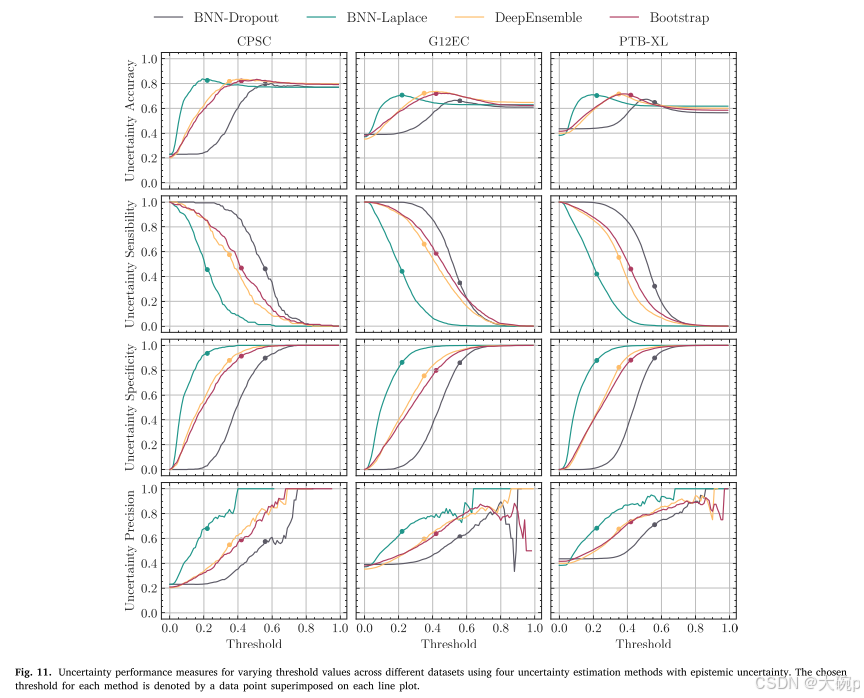
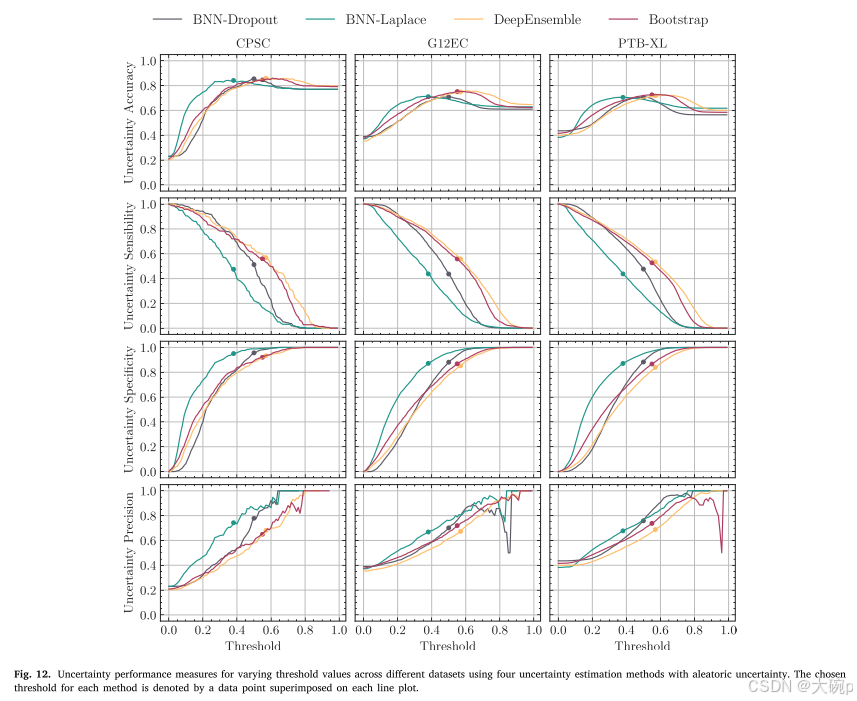
图11和图12描述了三个数据集的预测不确定性性能评估指标,使用不确定性估计方法同时改变不确定性阈值。 图 11 采用认知不确定性 (𝜎2) 作为不确定性测度,而图 12 使用任意不确定性(最大概率 𝑝𝑚𝑎𝑥)作为不确定性测度。 尽管在使用认知不确定性时这些差异更加明显,但任意不确定性也呈现出方法之间的一些差异。 无论选择的阈值如何,我们都可以从图中观察到外部数据集中的性能指标有所下降。 例如,内部验证中的不确定性精度最高可达0.8以上,而在外部数据集中,最高约为0.70。 由于不确定性阈值的正确定义超出了本工作的范围,因此我们选择基于训练中获得的给定拒绝率进行分析。 因此,我们在训练集上定义了 15% 的拒绝率,并使用相应的不确定性值来拒绝测试集上的样本。 每个阈值由放置在图 11 中每个线图顶部的数据点表示,强调每种方法的阈值不同,并且为所有方法选择相同的阈值并不能提供方法之间的公平比较。
1. 认识不确定性 (Epistemic Uncertainty)
定义:
- 认识不确定性指的是由于模型缺乏知识或训练数据不足而导致的不确定性。它反映了模型对输入数据的理解程度以及模型参数的不确定性。
- 这种不确定性可以通过获取更多的数据或改进模型结构来减少。
为什么 σ2可以作为认识不确定性的度量?
- 在贝叶斯神经网络和其他概率模型中,σ2 或方差通常用来表示模型权重的不确定性。
- 当使用变分推断或其他贝叶斯方法时,模型参数被视为随机变量,而不是固定的值。因此,σ2 描述了这些参数分布的宽度,从而量化了模型对参数的不确定性。
- 较大的 σ2 表示模型对参数值不太确定,这可能是由于训练数据不足或模型复杂度过高导致过拟合等原因引起的。
- 通过多次前向传播(例如,在蒙特卡洛dropout中),可以估计出预测分布的方差,这进一步帮助捕捉模型对特定输入的不确定性。
2. 数据不确定性 (Aleatoric Uncertainty)
定义:
- 数据不确定性指的是由数据本身的噪声、模糊性或随机性引起的不确定性。它是固有的,无法通过增加数据量或改进模型来减少。
- 这种不确定性可能来源于测量误差、自然变化或其他不可控因素。
为什么 pmax 可以作为数据不确定性的度量?
- pmaxpmax 是指模型给出的最大预测概率,即模型对某个类别最自信的程度。
- 对于一个给定的输入样本,如果 pmaxpmax 接近1,则表明模型对该样本属于某一类别的置信度很高;反之,如果 pmaxpmax 接近0或较低,则表明模型对该样本分类的不确定性较高。
- 在存在数据不确定性的情况下,即使模型非常确定其预测结果(即 pmaxpmax 很高),实际标签仍可能存在一定的随机性或噪声。这意味着,尽管模型对其预测很有信心,但真实世界中的情况可能会有所不同。
- 因此,低 pmaxpmax 值可以间接反映出数据本身的不确定性或复杂性,特别是在面对有噪声或模棱两可的数据时。
总结
- σ2:用于衡量模型参数的不确定性,反映的是模型对数据和自身结构的知识不足,因此适合用作认识不确定性的度量。
- pmax:用于衡量模型对单个预测结果的信心程度,能够间接反映数据本身的噪声和随机性,因此适合用作数据不确定性的度量。
为了简化使用拒绝选项进行分类的实验结果的分析,表 7 总结了最佳不确定性方法 DeepEnsemble 的拒绝选项的完整性能结果。 使用的不确定性拒绝度量是集合成员概率的方差𝜎2,因为它在之前的分析中实现了更好的性能度量。
表 7 中的第一个观察结果是,拒绝高度不确定的样本可以提高所有数据集的分类性能。 对于相同的阈值,不同数据集的拒绝率差异很大。 正如预期的那样,内部数据集 CPSC 表现出较低的拒绝率(类似于训练中应用的 15%),但对于外部数据集,拒绝率增加了一倍以上,G12EC 和 PTB-XL 数据集分别达到 0.385 和 0.317。 这一观察结果与迄今为止获得的结果一致,其中外部测试集包含更多不确定的样本。 对 OOD 数据集应用相同的阈值会导致 OOD-MI 和 OODHYP 的拒绝率分别为 0.634 和 0.666。 虽然未拒绝样本的性能可以被认为是可接受的(至少与内部验证相当),但超过 30% 的 OOD 样本没有被拒绝,这可能是 OOD 样本的很大一部分。 当然,降低不确定性阈值会拒绝更多的 OOD 样本。 然而,这是以拒绝来自已知类别的更多样本为代价的。

表 7 还强调了可接受的不确定性精度。 然而,在选定的阈值下,所有模型都表现出比敏感性更高的特异性。 这意味着如果我们想提高灵敏度(同时降低特异性),拒绝率也会增加。
5.5. 主动学习
RQ5:不确定性度量是否适合作为主动学习的选择标准?
除了使用拒绝选项进行分类之外,在临床实践中部署模型后的一个重要程序是持续培训以响应数据的变化并防止模型变得不可靠和不准确。 对于模型再训练,需要对需要专业知识的数据进行标记。 在临床实践中获得大量标记数据可能是不可行的。 减少这种努力的一种可能方法是依靠主动学习来选择哪些未标记的数据对模型来说信息量最大,并要求专家注释者仅在这些选定的样本上添加标签。
按照这个推理,我们使用 PTB-XL 和 G12EC 数据集的数据重新训练 DeepEnsemble 方法。 再训练过程包括从数据集中选择不确定性较高的被拒绝样本,并使用这些新样本重新训练模型。 出于比较目的,我们使用不同的不确定性测量和随机抽样重复此过程 5 次。 该过程包括使用 400 个新样本重新训练模型,并以 400 个新样本为一步重复该过程八次,在该过程结束时总共使用了 3200 个新样本。 对于此分析,我们将外部数据集分为训练集和测试集,并始终使用测试集呈现结果以进行公平比较。 由于 PTB-XL 具有 PhysioNet 提供的可用 10 倍分割,因此我们使用 PhysioNet 提出的最后一个倍数作为测试集,使用其他倍数进行训练。 对于 G12EC 数据集,由于没有建议的分割,我们使用 90%–10% 的训练测试分割,使用类别、性别和性别作为平衡数据分割的组标准。 这些测试集中获得的性能与使用整个数据集的性能相似,并代表图 13 图中的第一个点(0 个样本)。
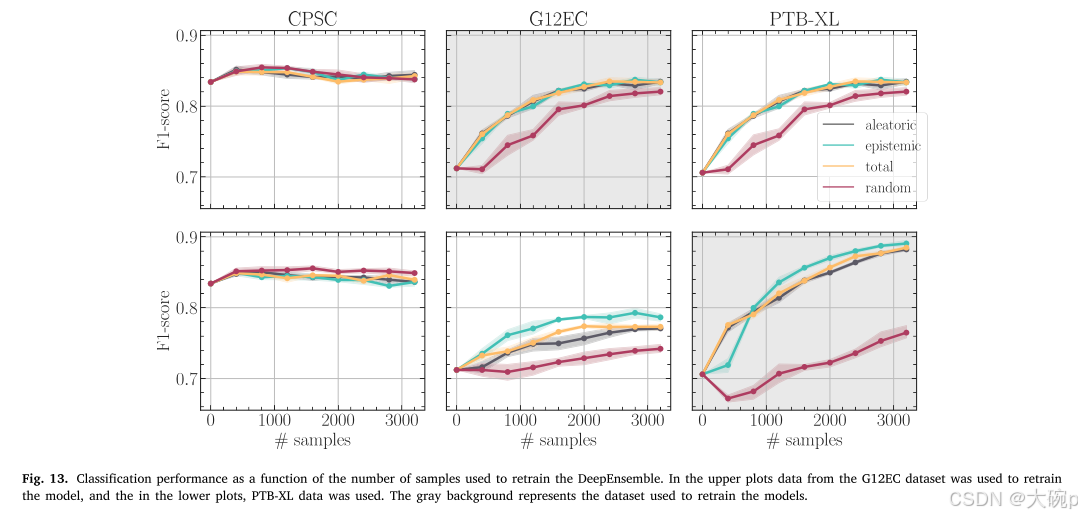
图 13 显示了随着用于重新训练模型的样本数量增加,分类性能的演变。 在第一行中,使用 G12EC 数据集的数据重新训练模型,在第二行中,使用 PTB-XL 数据。 灰色背景代表用于重新训练模型的数据集。 除了用于再训练的数据集中的性能演变之外,我们还显示其他数据集中的分类性能,以确保一个数据集中性能的提高并不代表其他数据集中性能的下降。 观察图 13,我们注意到从外部数据集中添加新样本不会影响内部 CPSC 数据集的性能。 相反,从一个外部数据集添加新样本不仅提高了该数据集的性能,还提高了其他外部数据集的性能。 将随机抽样与不同的不确定性度量进行比较,我们得出结论,每个不确定性度量的性能都比使用随机样本重新训练模型要好。 尽管随机采样也提高了分类性能,但速度较慢。 至于用于重新训练模型的不确定性度量,任意、认知和总体不确定性在 G12EC 数据集上获得了类似的结果。 除此之外,在 PTB-XL 数据集上,与任意不确定性和总体不确定性相比,认知不确定性获得了更高的改进,唯一的例外是 PTB-XL 数据集的前 400 个样本。

















 2820
2820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









