






在关键安全应用中部署深度学习模型仍然是一个非常具有挑战性的任务,需要为这些模型的可靠运行提供保证。不确定性量化(UQ)方法估计了每个预测的模型置信度,通过考虑随机性和模型设定错误的影响来指导决策。尽管最先进的UQ方法取得了进步,但它们计算成本高昂或产生过于保守的预测集合/区间。我们介绍了一种新的混合UQ方法MC-CP,该方法结合了一种新的自适应蒙特卡洛(MC)Dropout方法与共形预测(CP)。MC-CP在运行时自适应地调整传统的MC Dropout,以节省内存和计算资源,使得预测可以被CP使用,从而生成稳健的预测集合/区间。通过全面的实验,我们展示了MC-CP在分类和回归基准测试上相比其他可比的UQ方法如MC Dropout、RAPS和CQR有着显著的改进。MC-CP能够轻松地添加到现有模型中,使其部署变得简单。MC-CP的代码及复制包可以在https://github.com/team-daniel/MC-CP。
一、引言
深度学习 (DL) 的进步使其能够应用于各种具有挑战性的任务,包括语音识别(Kumar 等人,2020 年)和图像注释(Barnard 等人,2003 年)。 尽管其潜在应用众多,但在安全关键型应用(例如医学成像/诊断)中使用深度学习需要确保其可靠且稳健的运行(Pereira 和 Thomas 2020;Gerasimou 等人 2020)。 不确定性量化 (UQ) 对于评估 DL 模型对输入预测对的置信度以及确定 DL 模型中噪声、稀疏或低质量输入和错误指定的潜在影响至关重要(Kendall、Badrinarayanan 和 Cipolla,2016 年)。 最终,UQ能够理解模型特别不确定的情况,从而实现不确定性感知决策(Calinescu et al. 2018)。
以 DL 为重点的 UQ 方法旨在评估 DL 模型的模型和数据不确定性(Abdar 等人,2021 年)。其中,蒙特卡罗(Monte Carlo,MC)dropout(Gal 和 Ghahramani,2016 年)通过输出使用dropout层的网络集合预测的标准偏差,优雅地量化了 DL 模型中的不确定性。然而,运行无数次前向传递的计算成本很高。同样,贝叶斯神经网络(BNNs)(MacKay,1992 年)是一种更自然的 UQ 方法,可以估计认识不确定性和估计不确定性。不过,贝叶斯神经网络在训练和推理过程中都需要大量计算,而且需要进行大量微调。最后,保形预测(CP)(Vovk、Gammerman 和 Shafer,2005 年)产生的是预测集/区间,而不是单子。集合/区间越大,模型对其预测的不确定性就越大,而单子预测/窄区间通常表示置信度高。尽管 CP 方法有其优点,但它过于保守,产生的集合/区间大于需要(Fan、Ge 和 Mukherjee,2023 年)。
基于这些进展,我们引入了蒙特卡洛共形预测(MC-CP),这是一种新颖的混合方法,它结合了自适应蒙特卡洛Dropout与共形预测技术,既继承了前者统计上的效率,又保持了共形预测分布无关覆盖保证的优势。MC-CP通过收敛性评估动态调整传统的蒙特卡洛Dropout,在可能的情况下节省推理过程中的内存和计算资源。随后,这些预测结果被先进的共形预测技术处理,以生成稳健的预测集合/区间。我们的实验评估表明,这种混合MC-CP方法相比常规的共形预测方法更少出现过估计的情况。尽管其结构简单,但在分类和回归基准测试中,它优于当前最先进的基于共形预测(CP)和蒙特卡洛(MC)的方法,比如传统的蒙特卡洛Dropout、RAPS (Angelopoulos等, 2022) 和CQR (Romano, Patterson, and Candes, 2019)。当RAPS和CQR通过增加预测集合/区间的大小来量化不确定性时,MC-CP不仅做到了这一点,还输出了预测分布形式下的精确量化——即方差。我们的MC-CP方法设计为在推理时实现,这与证据深度学习和贝叶斯神经网络不同。虽然这些方法提供了显著且信息丰富的不确定性量化估计,但MC-CP是在训练后实现的。
我们的贡献是
- 自适应 MC dropout方法,与原始方法相比可节省计算资源;
- 混合 MC-CP 方法解决了 CP 方法常见的主要问题,在多个指标和数据集上都有显著改进。
- 在各种基准(包括 CIFAR-10、CIFAR100、MNIST、Fashion-MNIST 和 Tiny ImageNet)上与最先进的 UQ 方法(MC Dropout、RAPS、CQR)进行了全面的 MC-CP 实证评估。
论文结构: 讨论 UQ 的相关工作和背景材料。部分介绍 MC-CP 及其实证评估。部分总结本文。
二、相关工作
深度学习中的不确定性量化 (UQ) 表明模型对其预测的不确定性。 最常见的不确定性类型是任意的和认知的。 前者围绕数据中不可减少的不确定性(例如随机噪声)。 后者是模型缺乏知识或训练不佳,可以通过更多数据或更好的训练来减少。 MC-CP 专注于量化认知不确定性。
深度集成是量化深度学习不确定性的一种直接方法(Lakshminarayanan、Pritzel 和 Blundell 2017)。 该方法涉及训练具有相同或相似架构的网络集合,并使用不同的权重进行初始化。 训练后,集成使用其预测的平均值作为最终预测,使用方差作为不确定性,对相同的输入数据进行预测。
Monte Carlo (MC) dropout (Gal and Ghahramani 2016) 是一种简单有效的方法,通过利用 dropout (Srivastava et al. 2014) 来计算 DL 模型中的认知不确定性,dropout 是一种随机丢弃神经网络单元以防止依赖的正则化技术 在某些重量上。 尽管 dropout 通常在训练期间使用,但 MC dropout 在推理期间保持此功能处于活动状态,并执行多次前向传递以设计预测分布。 最终的预测是分布的均值,方差表示不确定性。 高斯 dropout(Kingma、Salimans 和 Welling 2015)通过使用高斯分布添加噪声而不是将单位值设置为零来补充常规 dropout。
贝叶斯神经网络 (BNN)(Kendall、Badrinarayanan 和 Cipolla 2016)直接在模型架构中实现 UQ。 在传统的深度学习网络中,权重是单个变量,而在 BNN 中,权重表示为分布。 尽管 BNN 产生的概率预测可以自然地捕获不确定性,但它们的计算量很大,并且需要比标准网络更多的训练,并采用变分推理等近似贝叶斯计算技术。
保形预测 (CP)(Vovk、Gammerman 和 Shafer 2005)是一个使用有效性来量化模型预测置信度的框架。 有效性表示,平均而言,模型的预测在保证的置信水平内(例如 90% 的时间)是正确的。 然后,该方法将预测从单个/点更改为指示模型置信水平的集合/区间。 集合/间隔越大,模型的不确定性越大,反之亦然。 CP 涉及将测试数据分为两组:校准集和测试集。 校准集用于估计达到所需置信水平所需的阈值。 CP 已应用于多种应用(例如图像分类(Angelopoulos 等人,2022 年)、回归(Romano、Patterson 和 Candes,2019 年)、目标检测(de Grancey 等人,2022 年))。
正交方法是测试时间增强(Wang et al. 2019;Moshkov et al. 2020),它在推理时改变数据而不是模型或预测。 给定输入,该方法使用各种增强技术创建多个增强输入。 然后深度学习模型对增强输入进行预测; 它们的分布和方差代表了模型的不确定性。 还提出使用生成式 AI 进行数据增强,以增强 DL 模型的推理能力(Missaoui、Gerasimou 和 Matragkas 2023)。
三、Preliminaries

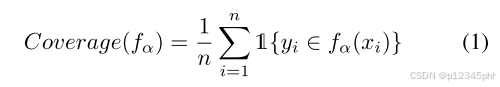 其中 α 是用户定义的覆盖范围,n 是验证集的大小,yi 是真实标签/值,fα(x) 是模型对输入 xi 所做的预测区间/集。 该方程反映了各个预测集/区间捕获的真实标签/值的百分比。
其中 α 是用户定义的覆盖范围,n 是验证集的大小,yi 是真实标签/值,fα(x) 是模型对输入 xi 所做的预测区间/集。 该方程反映了各个预测集/区间捕获的真实标签/值的百分比。
效率是另一个重要的 CP 指标。 虽然默认情况下将所有可能的类别包含在预测集中会产生完美的准确度分数,但这是不切实际的。 因此,能够有效实现所需覆盖范围的深度学习模型是首选。 效率计算为组/间隔的平均预期大小,由下式给出:
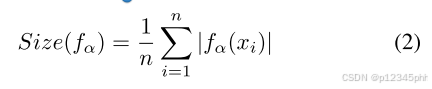
四、MC-CP
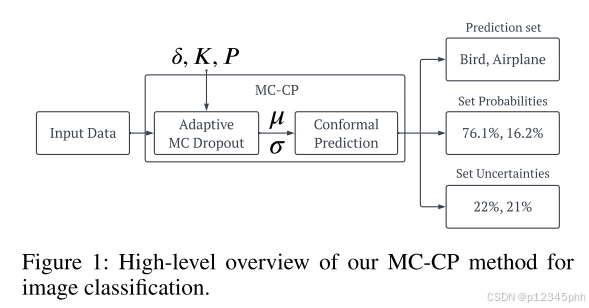
我们针对 UQ 的蒙特卡罗保形预测 (MC-CP) 方法结合了自适应 MC dropout 和保形预测,分别利用了它们的低计算成本和有限样本无分布覆盖保证。 图 1 显示了我们的 MC-CP 图像分类方法的高级概述。 我们讨论下一个自适应 MC dropout,然后阐述用于分类和回归的 MC-CP。 这种自适应 MC dropout 和 CP 的新颖组合虽然简单,但产生了一种混合 MC-CP 方法,与最先进的 UQ 技术相比,该方法产生了显着的改进。
4.1 Adaptive Monte Carlo Dropout
MC dropout 的竞争性预测性能很大程度上取决于推理时每个输入通过 DL 模型的多次随机前向传递的执行。 模型应执行的前向传递次数 K 是先验定义的并且是固定的。 由于对于任何新输入,深度学习模型的 dropout 层在推理过程中都会保持打开状态,因此这 K 个前向传递的集合会产生预测分布。 这种分布可以通过计算预期(平均)值、标准差和熵等指标来量化不确定性。
支持自适应 MC dropout 的动机源于这样的观察:每个前向传递对应于特定的 DL 模型实例化,该实例化为预测分布添加了独特的方差。 其中一些 DL 模型实例化由 MC dropout 前向传播通知,可以产生类似甚至完全相同的预测。 因此,虽然预测方差最初可能很大,但随着前向传递次数的增加,方差值变小,表明推理过程已经收敛。 如果当该事件发生时当前的前向传递次数远小于最大前向传递次数K,则剩余的前向传递仅产生额外的开销,但几乎没有增加任何价值。 一旦诊断出收敛,自适应 MC Dropout 利用这一观察结果来减少浪费的前向传递次数,从而在不影响预测有效性的情况下节省大量计算量。
算法 1 显示了我们的自适应 MC dropout 方法。 给定新的输入 x,该方法对模型 f 执行最多 K 次前向传递,以生成预测后验均值作为最终预测,并生成预测后验方差作为预测不确定性。 与传统的 MC dropout 不同,我们的算法使用超参数阈值 δ 和耐心 P 来检测收敛并提前终止。 阈值参数 δ 表示触发类别/分位数预测可能已收敛所需的最大方差差。 耐心 P 表示所有类别/分位数都低于 δ 以便提前停止执行的连续前向传递的数量。 执行满足阈值 δ 的 P 个连续前向传递的标准对于确定收敛性和减轻随机性的潜在影响非常重要。
-
δ(阈值):这是用来判断类/分位数预测是否已经收敛的最大方差变化量。当连续几次前向传递后,所有类或分位数的方差变化都小于 δ时,算法认为预测已经足够稳定,即达到了收敛状态。这里的“方差变化”指的是当前次前向传递得到的方差与上一次前向传递得到的方差之间的差异。如果这种差异小到可以忽略不计,则表明进一步增加前向传递次数对提高预测稳定性帮助不大。
-
P(耐心):这表示需要连续多少次前向传递满足上述条件(即所有类或分位数的方差变化均小于 δ)才能停止执行。例如,如果 P=3,那么必须有连续三次前向传递的结果都显示方差变化小于 δ,算法才会停止额外的计算。这个参数有助于确保不是因为偶然因素导致的一次性波动而过早地停止计算,而是基于一个更稳定的趋势做出决策。

自适应 MC dropout 的工作原理如下。 虽然当前前向传递计数器小于 K 并且当前耐心计数器小于 P(第 3 行),但模型在打开 dropout 层的情况下预测输入数据(第 4 行)。 预测将添加到列表中,并估计该列表的方差(第 5-6 行)。 从第二次前向传递开始,计算当前方差 σ 和最后估计方差 σi−1 之间的差(第 8 行)。 如果所有类别/分位数的差异低于阈值 δ,则当前耐心计数器增加(第 9-10 行); 否则,它被重置(第 12 行)。 一旦所有类/分位数在 P 次连续前向传递后收敛到 δ 以下,预测后验均值和方差将分别作为预测及其测量的不确定性输出(第 14 行)。

4.2 MC-CP for Image Classification
对于图像分类,我们将自适应蒙特卡洛Dropout方法与共形预测结合,形成MC-CP,如算法2所示。MC-CP分为两个步骤:共形校准和预测。首先,测试数据集被分为校准集和验证集。然后在预训练模型上使用校准集进行Platt缩放。接下来,我们计算校验集中每个输入图像的共形分数,这些分数可以用来计算分位数阈值 q^。
在MC-CP的预测阶段,我们为每个新的输入图像调用自适应MC Dropout方法,使用选定的超参数。该调用返回图像可能类别的均值预测和方差。最终的预测集可以通过计算所有类别的累积softmax输出来确定,然后包括从最可能到最不可能的类别,直到不超出分位数阈值。在第XX节中,我们展示了MC-CP如何在适度的计算开销下优于其他最先进的共形预测技术。

4.3 MC-CP for Regression
我们还开发了用于深度分位数回归的 MC-CP 扩展,如算法 3 所示。这也分为校准和预测步骤。 为了计算保形分数,需要估计所需分位数的误差大小。 接下来,可以使用校准数据集计算阈值。 对于深度分位数回归的 MC-CP 预测阶段,对于验证数据集中的每个数据点,再次使用所需的超参数调用自适应 MC Dropout 方法。 最后,使用计算出的阈值计算验证集中未见过的数据点上的两个分位数的预测区间。 在第 x 节中,我们展示了 MC-CP 如何优于常规深度分位数回归和 CQR 方法。

五、Evaluation
5.1实验装置
基准为了进行分类,我们在五个图像数据集上评估 MC-CP:CIFAR-10 和 CIFAR-100 (Krizhevsky 2009)、MNIST (LeCun et al. 1998)、Fashion-MNIST (Xiao、Rasul 和 Vollgraf 2017) 以及 Tiny ImageNet (吴、张和徐,2017)。 CIFAR-10 和 CIFAR-100 分别包含 60、000 个 32x32 彩色图像,分别具有 10 和 100 个类别。 MNIST 和 Fashion-MNIST 包含 60, 000 个 28x28 灰度图像,每个图像有 10 个类别。 Tiny ImageNet 是著名 ImageNet 数据集的小型版本,包含 100, 000 个 64x64 彩色图像,200 个类别。
对于回归,我们使用以下五个基准:Boston Housing (Harrison and Rubinfield 1978)、Abalone (Nash et al. 1995)、博客反馈 (Buza 2014)、混凝土抗压强度 (Yeh 2007) 和蛋白质三级结构的理化性质 数据集(Rana 2013)。 Boston Housing 数据集包含 506 个数据点,14 个属性;Abalone 数据集包含 4180 个数据点,9 个属性;Blog Feedback 数据集包含 60,021 个数据点,281 个属性;Concrete 数据集包含 1,030 个数据点,9 个属性;Physicochemical Properties 数据集包含 1,030 个数据点,9 个属性。 蛋白质三级结构数据集包含 45,730 个数据点,具有 9 个属性。
UQ 方法配置。
在我们的分类实验中,所有方法都使用基本的卷积神经网络 (CNN) 架构,包括两个隐藏层、两个池化层和两个频率为 50% 的 dropout 层。 所有模型均以 128 的批量大小进行 10 轮训练。 分类交叉熵损失函数和随机梯度下降优化器的学习率和动量分别为 0.1 和 0.9。 每个实验重复五次以考虑随机性。 对于 CP 方法,校准集大小为测试集的 25%,α = 0.05。 我们的实验中不考虑深度集成或贝叶斯神经网络。 这些技术需要在数据集之间进行大量微调,不允许我们建立清晰的基线。 性能差异是否是由于超参数调整或方法本身造成的并不明显。 为了进行公平比较,我们对所有基于分类的 UQ 方法使用相同的网络架构和超参数,即标准 CNN、具有 MC dropout 的 CNN、Naive CP、RAPS 和 MC-CP(使用 RAPS 进行检测)。
在我们的回归实验中,所有方法都使用包含两个隐藏层和两个频率为 25% 的 dropout 层的深度分位数回归模型。 Adam 优化器的学习率为 0.001,使用自定义多分位数损失函数,分位数为 0.05 和 0.95。 每个模型都在批量大小为 32 的情况下训练 100 个周期,并重复实验五次以考虑随机性。 对于 CP 方法,校准集大小为测试集的 2%,且 α = 0.1。 与之前一样,相同的 DL 模型用于比较以下基于回归的 UQ 方法:深度分位数回归器、具有 MC dropout 的深度分位数回归器、CQR 以及使用 CQR 检测的 MC-CP。
5.2 图像分类结果
分类准确度。 表 1 显示了针对每个数据集的五种不同方法的准确性结果。针对 MC-CP 测试的方法是基线 CNN、应用了 MC dropout 的相同 CNN、朴素保形预测(Angelopoulos 和 Bates 2022)和 RAPS 。 结果表明,与基线和最先进的共形预测方法相比,MC-CP 不仅提高了准确性,而且运行之间的偏差也更小。 我们特别强调,我们的方法始终如一地提高了准确性,并在 CIFAR-10、CIFAR-100 和 Tiny ImageNet 等困难数据集上产生了较低的标准偏差。 此外,正如预期的那样,与基线方法(例如常规 CNN 和 MC dropout)相比,保形预测方法可以极大地提高准确性。 然而,MC-CP 大大提高了准确性,运行之间的偏差更小,突出了它与 Naive CP 和 RAPS 的一致性。
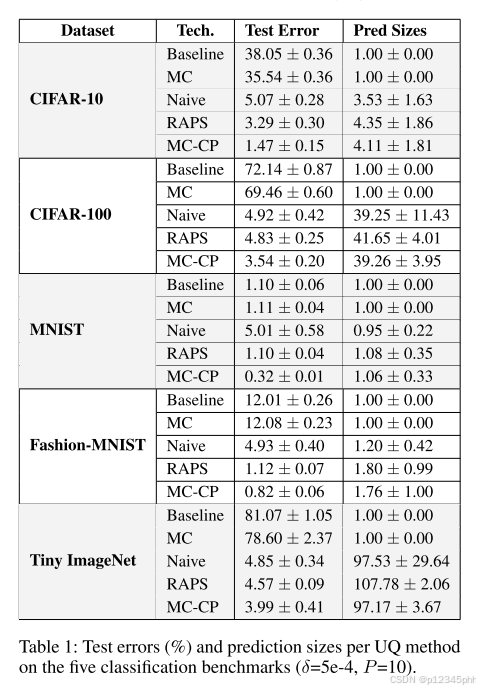
单例和混合预测。 接下来,我们比较 CIFAR-10 上所有三种共形预测方法的单例和非单例(混合)预测的百分比和准确性(图 2)。 Naive CP 更有可能预测单例值,而我们的方法则可能性最小。 当模型对其预测没有信心时,基于 CP 的方法应适当增加预测集大小以解决这种不确定性,并希望在较大的预测集中包含正确的类别。 图 2 中单例和非单例结果的比较提供了证据,证明我们的方法正确地增加了集合大小以提高准确性。 事实上,对于单例和非单例集大小,我们的方法以最高的准确度执行,也表现出一致的行为,如运行之间的少量方差所示。
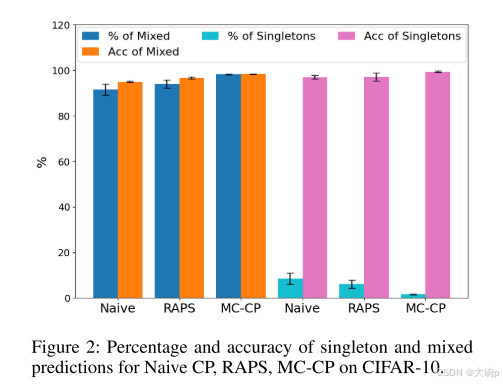
可以认为,使集合大小足够大可以覆盖几乎所有类别,并且这种行为可以反映更高的准确性。 将这些结果与表 1 中的平均集大小进行比较,我们可以看到所有方法仅覆盖其平均集大小中的一部分类。
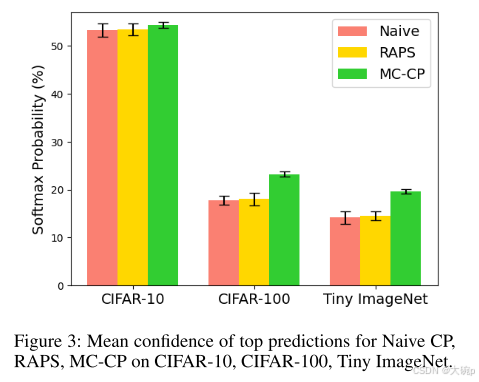
预测的置信度。 我们评估了 MC-CP 是否可以产生比传统共形预测方法更可信的模型,从而提供更高的准确性。 图 3 显示了 CIFAR-10、CIFAR-100 和 Tiny ImageNet 的每种 CP 方法的平均最高 softmax 输出。 与 Naive CP 和 RAPS 相比,我们的方法显示所有基准的置信度都有所提高。 仔细观察更大规模的数据集,例如 CIFAR-100 和 Tiny ImageNet,MC-CP 对其预测更加自信。 在图 3 中我们还观察到,MC-CP 运行之间的标准偏差始终比其他方法更小。
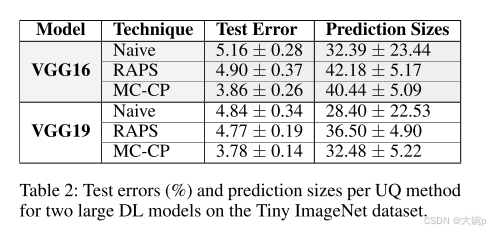
预测集大小。 我们已经展示了如何使用 CIFAR100 大规模测试每种方法的准确性。 然而,这仅反映了每种方法大规模性能的一部分,并没有突出其任何弱点。 表 1 中的“预测大小”列显示了五个数据集上 Naive CP、RAPS 和 MCCP 的平均集大小和方差。 CIFAR-10 上的结果表明 Naive CP 具有最小的平均集大小,但这并不能反映其准确性。 查看 CIFAR-100 结果,我们可以看到 Naive CP 再次具有最小均值,但其方差明显大于其他结果。 事实上,我们观察到 Naive CP 的集合大小范围为 1 到 86,这表明该方法无法有效应对具有许多(潜在)类别的大规模数据集。 对于这两个数据集,MC-CP 实现的均值比 RAPS 更小,并且与均值的偏差更小。 对于 CIFAR-100,RAPS 的设置大小范围为 33 到 59,而 MC-CP 的设置大小范围为 30 到 52。这些结果表明 MC-CP 如何提高保形预测算法的置信度并获得更好的结果。 总体而言,我们观察到先进的 CP 算法(如 RAPS)往往会高估其预测,而 MC-CP 可以减少这种高估。 我们还通过在 Tiny ImageNet 数据集上使用 VGG16 和 VGG19 模型评估其功能,证明我们的 MC-CP 方法与大规模模型配合良好。 表 2 显示了这些模型的减少的预测集大小。 较大 DL 模型的结果与表 1 中显示的结果一致,除了较小的幅度之外。
class的准确性。 接下来我们验证了 MC-CP 不仅在一两个类中比其他方法表现得更好,而且在几乎所有类中确实表现得更好。 表 3 显示了 CIFAR-10 数据集中每个类别的所有方法的平均准确度。 我们再次看到与其他方法相比,MC-CP 提高了准确性的趋势,并且运行之间的偏差也减少了。 MC-CP 始终达到约 97-99% 的准确率,这表明它确实提高了总体准确率,而不仅仅是少数类别的准确率。 Frog 类是 Naive CP 实现更高准确度的唯一异常值,但这似乎是该模型的异常值; MC-CP 仍然实现了 99.02% ± 0.59 的高平均精度。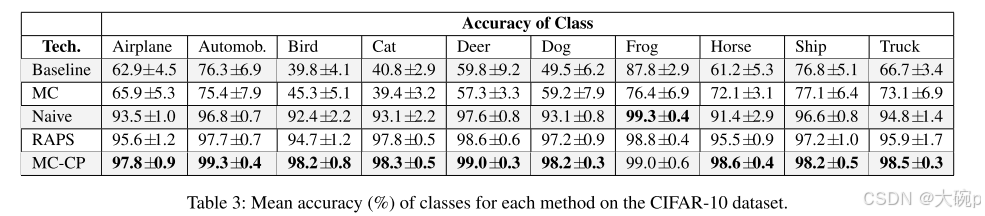
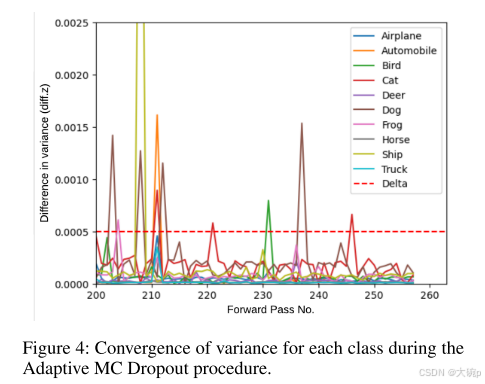
自适应 MC Dropout。 图 4 显示了 CIFAR 10 数据集中示例图像的每个类方差的收敛情况。 我们观察到,在大约 200 次前向传递时,所有类的方差差异低于 δ 阈值,并且耐心计数器开始随着每次新迭代而增加。 然而,在大约 205 次前向传递时,船舶和汽车类别的方差差异峰值超过阈值; 这是由于 MC dropout 的随机性造成的。 经过 246 次前向传递后,所有类别均降至阈值以下,并且 MC-CP 过程会在十次迭代后完成早期。
我们还对自适应 MC dropout 进行了敏感性分析,以评估阈值 δ 和耐心 P 对其性能的影响。 表 4 显示了这些实验中使用的 δ 和 P 值的各种组合。 随着 P 的增加和 δ 的减少(从左上到右下),我们注意到前向传递的平均数量增加,从而导致测试误差(即准确性增加)和预测集大小相应减少。 正如预期的那样,当 δ = 0.00001、P = 100(右下)时,我们得到传统的 MC dropout,其中前向传递等于 K=1000。
最后,我们通过将 K= 1000、δ=5e-4、P=10 的情况下的执行开销与传统 MC Dropout 进行比较,证明自适应 MC Dropout 可以节省资源。 传统的 MC dropout 在 CIFAR-10 上执行了全部 1000 次前向传递,每个图像推理平均花费 35.52 ± 0.42 秒。 自适应 MC Dropout 在所有图像上平均通过 500.21±196.37 次,平均耗时 17.99±7.09 秒。 我们的方法诊断收敛的能力使执行速度提高了约 50%,这意味着不需要其他约 500 次前向传递。 考虑到内存消耗,正如预期的那样,在训练完整模型以及数据集推理时,两种方法都使用相同的内存(常规/自适应 MC Dropout 为 1.07GB/1.08GB)。

















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









