









EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention

需要注意的是,EfficientViT这个模型名字与另一篇语义分割的工作 https://arxiv.org/pdf/2205.14756.pdf 重名了。
核心动机
核心就是针对Vision Transformer的推理效率的优化。
主要内容
在针对两类主流的Vision Transformer的分析中给出了三点有意思的结论。

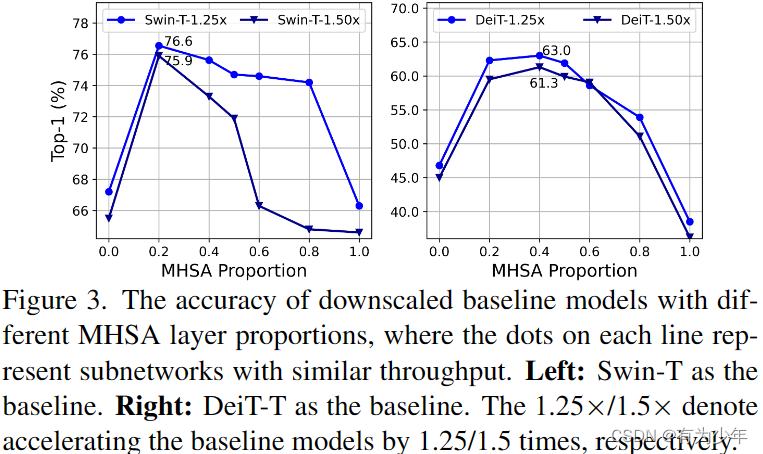
- 内存访问开销是影响模型速度的关键因素。Vision Transformer的许多操作,如频繁的reshape、元素加法和归一化操作,都是内存效率低下的,需要跨不同存储单元进行耗时的访问,如图2所示。虽然有一些方法可以通过简化标准softmax自注意的计算来解决这个问题,例如稀疏注意和低秩近似,但它们往往以精度下降和有限的加速为代价。从图3中的实验可以看出,对于Vision Transformer而言,适当减少MHSA的使用率可以提升模型的内存效率,同时甚至可能提升性能。
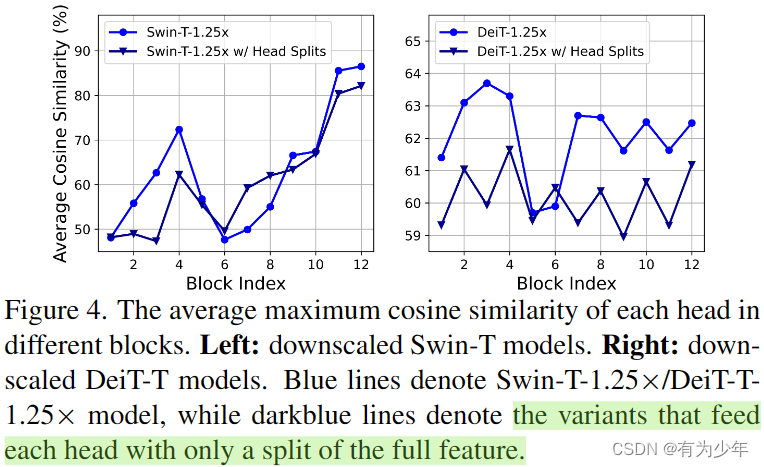
- MHSA中,不同的head使用不同的输入通道组,能比所有头使用所有输入通道可以有效强化不同的头学习不同的模式,缓解注意力计算的冗余性,即对应图中,可以降低头之间的相似性。
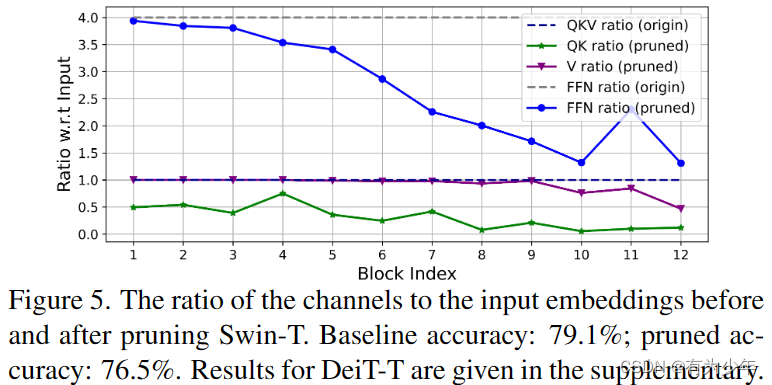
- 通过Taylor结构化剪枝技术的分析可以看出,传统Vision Transformer中的通道配置策略可能会让深层块产生更多的冗余性。在设定相同维度的情况下,Q和K的冗余性要大于V,而且V更偏好相对大的通道数量。
方法细节
综合前面的分析,作者们设计了一种更加高效的ViT变体:
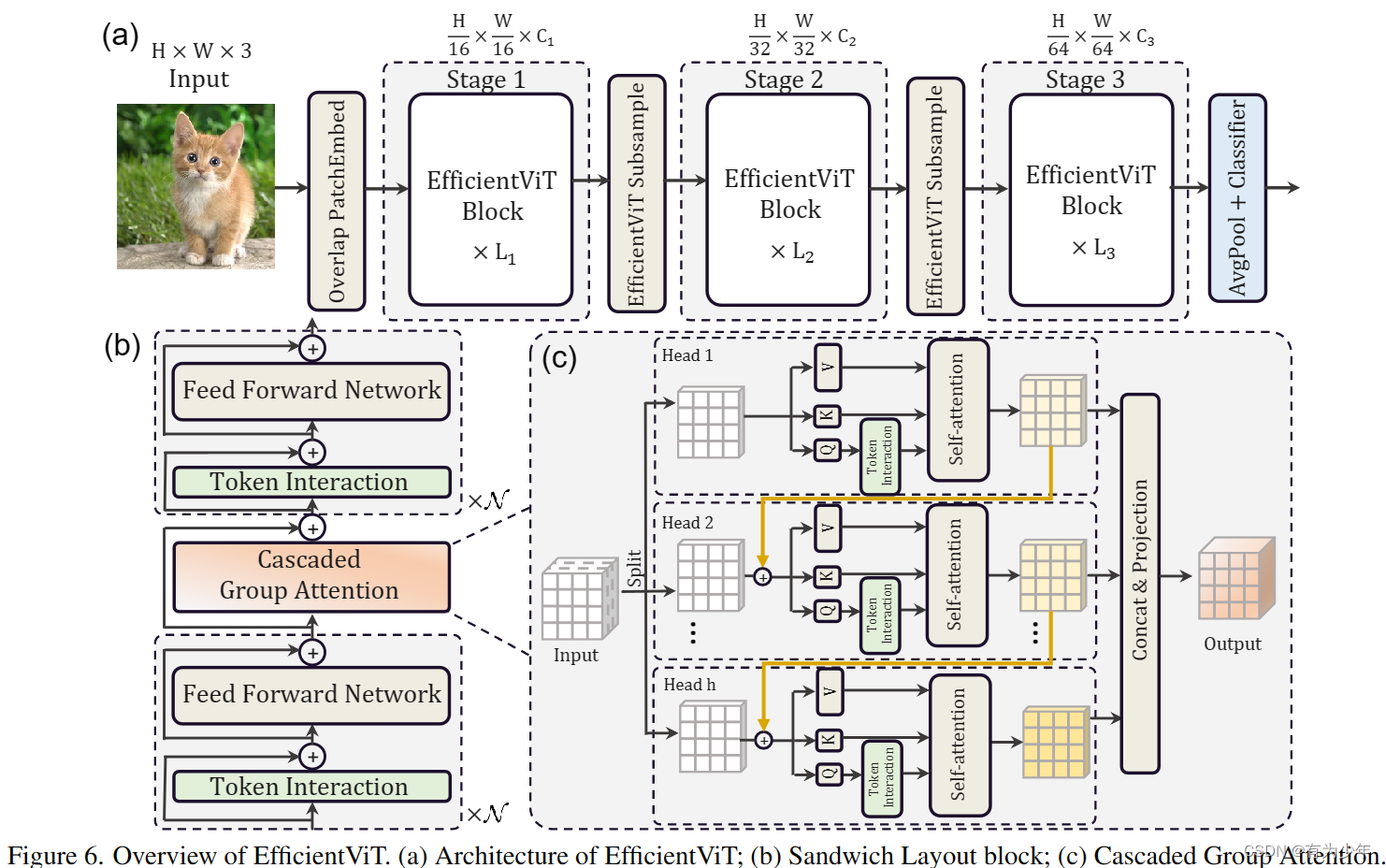
- 输入时,直接使用重叠的块嵌入层下采样16倍。
- 模型中仅使用三个尺度的阶段。
- 不同stage之间的下采样层使用线性层和逆残差模块构成的sandwich布局实现,来减少信息的损失。
- 模型中统一使用BN和ReLU,提升推理效率。
- 使用更多的内存有效的FFN,减少内存受限的MHSA的使用。这里基于“基于深度卷积的Token Interaction+线性FFN+GroupAttention+基于深度卷积的Token Interaction+线性FFN”构造了一种sandwich类型的结构作为基础构建块。使用Token Interaction引入更多的局部归纳偏置。
- 受启发于分组卷积,这里直接对Attention的头设计成分split处理,设计了新的Attention变体。
- 这里的split指代的是计算Q,K,V之前就开始分组了,而Q,K,V内部计算时不再分头。而标准MHSA中,QKV的获取是使用了全部的输入特征通道。
- 值得注意的是,这里的分头设计实现的时候,不同分组是级联形式,即上图中所示的橙色连线。每个子头的输出会被加到下一个头的输入上,从而进一步提提升模型的容量,鼓励特征的多样性。
- Q在参与Attention计算之前会先通过一个独立的token Interaction增强局部表征。
- 每个头所有阶段的Q和K的投影矩阵使用更少的通道。V的投影矩阵与输入的嵌入具有相同维数。由于FFN的参数冗余,其通道扩展比也从4降低到2。利用该策略,重要模块在高维空间中有更多的通道来学习表征,避免了特征信息的丢失。同时去除不重要模块中的冗余参数,加快推理速度,提高模型效率。
CGA的实现
# https://github.com/microsoft/Cream/blob/ef68993c764f241a768cd69a087ed567dec6cb40/EfficientViT/classification/model/efficientvit.py#L104-L181
class CascadedGroupAttention(torch.nn.Module):
r""" Cascaded Group Attention.
Args:
dim (int): Number of input channels.
key_dim (int): The dimension for query and key.
num_heads (int): Number of attention heads.
attn_ratio (int): Multiplier for the query dim for value dimension.
resolution (int): Input resolution, correspond to the window size.
kernels (List[int]): The kernel size of the dw conv on query.
"""
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
resolution=14,
kernels=[5, 5, 5, 5],):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.d = int(attn_ratio * key_dim)
self.attn_ratio = attn_ratio
qkvs = []
dws = []
for i in range(num_heads):
qkvs.append(Conv2d_BN(dim // (num_heads), self.key_dim * 2 + self.d, resolution=resolution))
dws.append(Conv2d_BN(self.key_dim, self.key_dim, kernels[i], 1, kernels[i]//2, groups=self.key_dim, resolution=resolution))
self.qkvs = torch.nn.ModuleList(qkvs)
self.dws = torch.nn.ModuleList(dws)
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
self.d * num_heads, dim, bn_weight_init=0, resolution=resolution))
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,C,H,W)
B, C, H, W = x.shape
trainingab = self.attention_biases[:, self.attention_bias_idxs]
feats_in = x.chunk(len(self.qkvs), dim=1)
feats_out = []
feat = feats_in[0]
for i, qkv in enumerate(self.qkvs):
if i > 0: # add the previous output to the input
feat = feat + feats_in[i]
feat = qkv(feat)
q, k, v = feat.view(B, -1, H, W).split([self.key_dim, self.key_dim, self.d], dim=1) # B, C/h, H, W
q = self.dws[i](q)
q, k, v = q.flatten(2), k.flatten(2), v.flatten(2) # B, C/h, N
attn = (
(q.transpose(-2, -1) @ k) * self.scale
+
(trainingab[i] if self.training else self.ab[i])
)
attn = attn.softmax(dim=-1) # BNN
feat = (v @ attn.transpose(-2, -1)).view(B, self.d, H, W) # BCHW
feats_out.append(feat)
x = self.proj(torch.cat(feats_out, 1))
return x
实验细节
性能对比

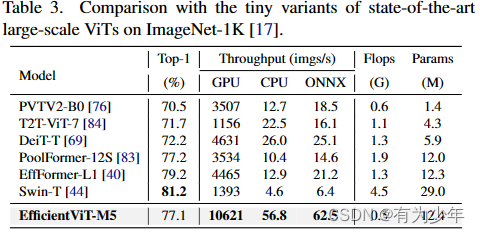
消融实验
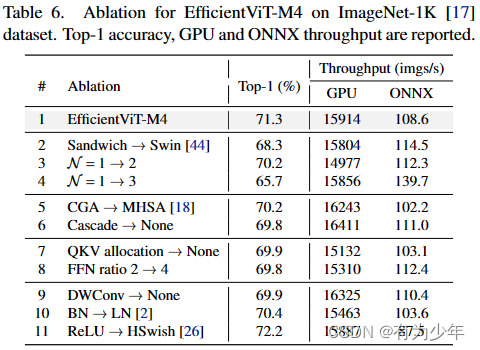
不同组件的性能:
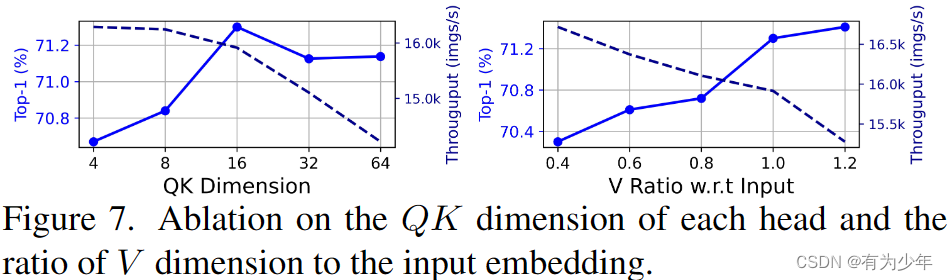
对QK和V的维度的消融:














 2321
2321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









