







 本文介绍了一个端到端模型,可从一张照片得到3D人体。模型包括四个子网络,分别预测2D pose、2D分割、3D pose和3D shape,采用多视角—重映射损失进行fine - tune,用相关信息监督训练。不过,该模型存在训练图片理想化、深度二义性等问题。
本文介绍了一个端到端模型,可从一张照片得到3D人体。模型包括四个子网络,分别预测2D pose、2D分割、3D pose和3D shape,采用多视角—重映射损失进行fine - tune,用相关信息监督训练。不过,该模型存在训练图片理想化、深度二义性等问题。
Research question:从一张照片得到3D人体
(本文是训练的是端到端模型,特意查了一下end-to-end的概念:与之对应的是多步骤解决问题,即一个问题拆分成多个步骤分布解决。而端到端的是由输入端的数据直接得到输出端的结果,即一端数据,一端结果。
对应本文就是输入一张图片(data),直接输出3D人体(result))
Contributions:
- 用体素表示来估计人体形态
- 用多视角—重映射损失来 fine-tune。用2D pose,2D分割以及3D pose信息来监督训练。
- 网络完全可微,并可做体素化人体分割
Empirics:
SURREAL、UP、MPII
Methods:
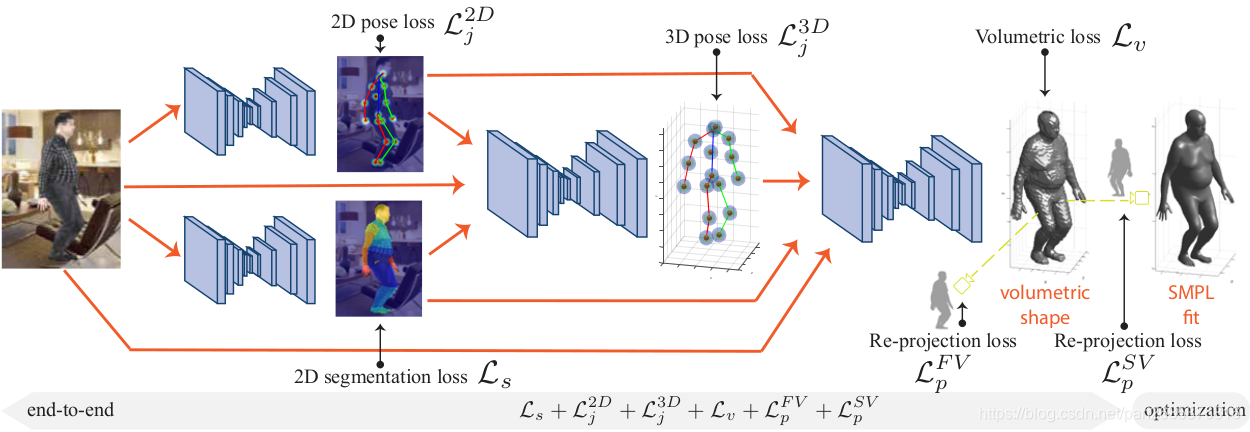
BodyNet结构如下:
包括四个子网络,分别预测2D pose、2D 分割、 3D pose 以及 3D shape。
- 输入图片,输出 2D pose 。
- 输入图片,输出 2D 分割。
- 输入图片 + 2D pose + 2D 分割结果,输出 3D pose。
- 输入图片 + 2D pose + 2D 分割结果 + 3D pose,输出 3D shape。
(1)2D pose 网络
用热图表示2D pose,对每个关节分别预测热图,每个二维高斯分布以关节点位置为中心,有固定偏差。最终关节点位置就是每个输出通道(这里的通道不是RGB通道,而是对应每个关节点的通道,有16个)的最大值的像素索引。用两个堆叠的hourglass网络,将3×256×256的RGB特征图像映射到热图16×64×64,预测16个身体关节。真值和热图的平方误差记为。
(2)2D part 分割网络
结构和2D pose 网络类似,也堆叠两个hourglass网络。输入RGB图片,为每个body part 输出一张热图,输出结果分辨率为15×64×64(15个body part)。空间交叉熵损失记为
(3)3D pose 网络
堆叠两个hourglass网络。
估计3D 关节点位置存在二义性问题。为缓解不确定性,假定相机内参已知,并在相机坐标系预测3D pos。将二维热图的概念扩展到三维,将3D高斯定义在体素网格上。
对于每个关节点,以它的位置为中心,用单独3D高斯分布定义固定分辨率的体积 。网格的xy轴和图片坐标对齐,z轴代表深度。
体素网格与3D人体配准,所以根关节点也对应3D体积的中心。定义人体深度范围,大概85cm,划分为19bins,即,三维网格分辨率为注意这里的3D pose分辨率是304×64×64(304=16×19,有16个关节点,每个关节点划分为19个bins),大小是输入图片的四分之一。每个关节点的平方误差为
该网络也堆叠两个hourglass网络,这里的输入是图片 + 2D pose + 2D 分割结果,即有三个输入,要将它们串联起来。
2D pose和2D 分割结果是热图,分辨率分别为16×64×64和15×64×64,比图片分辨率小,无法直接串联,所以对它们上采样,结果分辨率为16×256×256和15×256×256,串联它们,输入就是(3+16+15)×256×256。
加入2D 分割信息的意义:2D pose提供关节点xy坐标信息,2D 分割隐含关节点深度信息。因为不像剪影,body part的遮挡关系能提供很强的3D 线索。如手臂分割引起的躯干不连续,是因为手在身前。
(4)体素化推断 3D 人体——3D shape网络
堆叠两个hourglass网络。
本文用体素来表示人体。给定一个3D人体,以根关节点(臀部)为中心,所有在体内的体元标记为占用。缩放3D体素,使3D人体的xy平面与2D 分割配准,保证与输入图片空间对应。在缩放之后,body以z轴为中心,剩下的区域用0做padding。
网络得到输出,经过sigmoid函数后,最小化交叉熵损失:
其中 和
分别表示真值和预测体素。这里W=128,H=128,D=128,即人体的空间分别率是128*128*128,文章认为这能表示足够的细节。损失
用于前景—背景分割,即区分该体素是否在人体内部,即是否被占用。子网络结构如下:
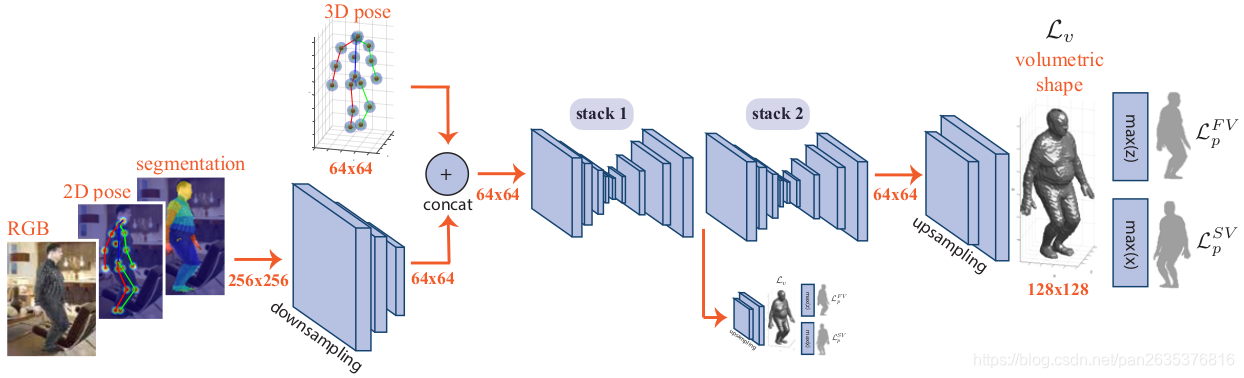
RGB、2D pose、2D segmentation的空间分辨率都是256×256,四分之一下采样后得到与3D pose 分辨率相同的64×64,即可将四个信息直接串联,输出结果分辨率为64×64,经过双线性插值,ReLU、3×3卷积,得到最终3D shape的分辨率128×128×128。
另外,本文还有另一个应用,即3D人体分割,将扩展到多类交叉熵损失,定义人体为6个部分(头、躯干、左/右腿、左/右手臂),第7类为背景。该扩展能使网路直接推断3D part,而不需要经过难算的SMPL模型。
(5)fine-tuning过程
肢体的置信度一般比躯干低,为解决这个问题,用2D 重投影(re-projection loss)损失,增加边界体素的重要性。是沿着z轴投影体素网格到平面上,可看作体素的主视图。
则是沿着x轴投影,可看作体素的左视图。
,
由数据集2D真值的part分割提供。而体素表示左视图的真值由3D网格真值计算而得:
因为只要体元和表面有交叉,它就会被标记为占用,所以最终的体素化表示比原始网格大。按视角定义二元交叉熵损失如下:
,
一开始训练shape网络用的是(4)中的,之后fine-tuning该网络,使用二者结合的损失函数:
(6)总体损失函数和训练细节
子网络开始都由各自loss函数分开训练,再用总体损失函数,联合fine-tuned:
权重系数定为,保证在fine-tuning之前,每个loss平均梯度在同一尺度上,并保证
。
一开始在SURREAL上设定权重,之后的实验都应用它们。文章发现这样很有必要,保证网络不遗忘中间task,并同时提高所有工作的performance。
网络整体训练过程如下:
- 训练2D pose和分割网络
- 固定2D pose和分割网络权重,训练3D pose网络
- 固定前三个子网络的权重,训练3D shape网络
- 用额外的重投影损失继续训练3D shape网络
- 用总体loss fine-tuning整个网络
(7)
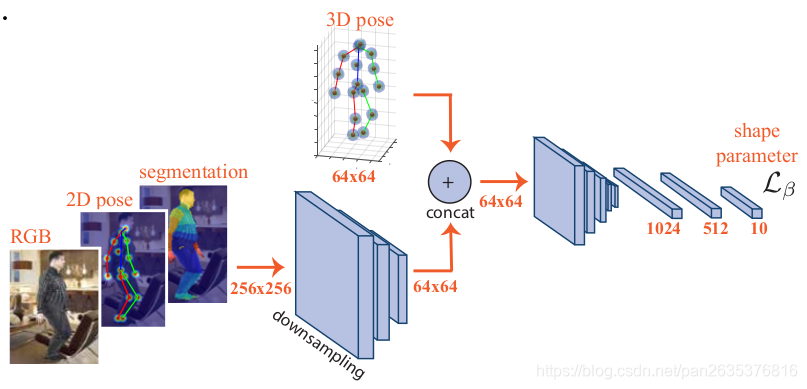
在一些应用中,仍需要人体的3D表面网格,或是参数化模型,便于认为修改。所以得到体素化人体后,需要代入SMPL模型,得到SMPL的形状参数,pose参数。损失函数是权重chamfer distance加上3D关节点的2-范数距离。步骤如下:
- 提取预测体素的等值面
- 拟合SMPL模型参数
输出的分辨率为128*4*4,经过三个全连接层得到一个10维向量,该向量即为SMPL模型的形状参数。
Constructive critiques:
首先本文用的训练和测试图片,基本都是沿着人的bounding box裁剪过的,便于网络识别,现实照片不会这么理想。在支撑材料就提到了一些 failure case ,如果图片里有多人干扰,恢复出的人体也是畸形的。
除此之外,深度二义性也无法避免。预测的 3D 人体从图片视角看上去是准确的,但把人体转换了角度再观察,发现完全不是那么回事,这个人体的 pose 没有从原视角看起来那么准确了。

















 1800
1800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









