







 本文总结了3D人体相关的研究,涵盖3D表示方法,如voxel、point cloud和polygon mesh,以及3D人体模型SMPL和SMPL-X。3D人体姿态估计和重建任务,包括单张图像、视频和RGBD输入的挑战与进展。同时探讨了3D衣服建模和人体动作驱动技术,涉及数据获取、动作合成和驱动的现状与挑战。
本文总结了3D人体相关的研究,涵盖3D表示方法,如voxel、point cloud和polygon mesh,以及3D人体模型SMPL和SMPL-X。3D人体姿态估计和重建任务,包括单张图像、视频和RGBD输入的挑战与进展。同时探讨了3D衣服建模和人体动作驱动技术,涉及数据获取、动作合成和驱动的现状与挑战。

©PaperWeekly 原创 · 作者|张莹
单位|腾讯
本文简要介绍与 3D 数字人相关的研究,包括常用 3D 表示、常用 3D 人体模型、3D 人体姿态估计,带衣服 3D 人体重建,3D 衣服建模,以及人体动作驱动等。

常用3D表示
目前 3D 学习中,物体或场景的表示包括显式表示与隐式表示两种,主流的显式表示包括基于 voxel、基于 point cloud、和基于 polygon mesh 三种,隐式表示包括基于 Occupancy Function [1]、和基于 Signed Distance Functions [2] 两种。下表简要总结了各种表示方法的原理及其相应优缺点。

1.1 Voxel
表示图像:

表示原理:体素用规则的立方体表示 3D 物体,体素是数据在三维空间中的最小分割单位,类似于 2D 图像中的像素。
优缺点:
+ 规则表示,容易送入网络学习
+ 可以处理任意拓扑结构
- 随着分辨率增加,内存呈立方级增长
- 物体表示不够精细
- 纹理不友好
1.2 Point Cloud
表示图像:

表示原理:点云将多面体表示为三维空间中点的集合,一般用激光雷达或深度相机扫描后得到点云数据。
优缺点:
+ 容易获取
+ 可以处理任意拓扑结构
- 缺少点与点之间连接关系
- 物体表示不够精细
- 纹理不友好
1.3 Polygon Mesh
表示图像:

表示原理:多边形网格将多面体表示为顶点与面片的集合,包含了物体表面的拓扑信息。
优缺点:
+ 高质量描述 3D 几何结构
+ 内存占有较少
+ 纹理友好
- 不同物体类别需要不同的 mesh 模版
- 网络较难学习
1.4 Occupancy Function
表示图像:
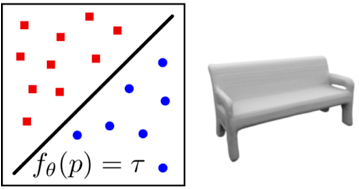
表示原理:occupancy function 将物体表示为一个占有函数,即空间中每个点是否在表面上。
优缺点:
+ 可以精细建模细节,理论上分辨率无穷
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构
1.5 Signed Distance Function
表示图像:

表示原理:SDF 将物体表示为符号距离函数,即空间中每个点距离表面的距离。
优缺点:
+ 可以精细建模细节,理论上分辨率无穷
+ 内存占有少
+ 网络较易学习
- 需后处理得到显式几何结构

常用3D人体模型
目前常用的人体参数化表示模型为德国马克斯•普朗克研究所提出的 SMPL [3],该模型采用 6890 个顶点(vertices), 和 13776 个面片(faces)定义人体 template mesh,并采用 10 维参数向量控制人体 shape,24 个关节点旋转参数控制人体 pose,其中每个关节点旋转参数采用 3 维向量来表示该关节相对其父关节分别沿着 x, y, z 轴的旋转角。
该研究所在 CVPR 2019 上提出 SMPL-X [4],采用了更多顶点来精细建模人体,并加入了面部表情和手部姿态的参数化控制。这两篇工作给出了规范的、通用的、可以与工业 3D 软件如 Maya 和 Unity 相通的人体参数化表示,并提出了一套简单有效的蒙皮策略,使得人体表面的顶点跟随关节旋转运动时不会产生明显瑕疵。
近年来也有不少改进的人体模型,如 SoftSMPL [5],STAR [6],BLSM [7],GHUM [8] 等。

2.1 SMPL
基本表示:
mesh 表示:6890 vertices, 13776 faces
pose 控制:24 个关节点,24*3 维旋转向量
shape 控制:10 维向量
示意图:
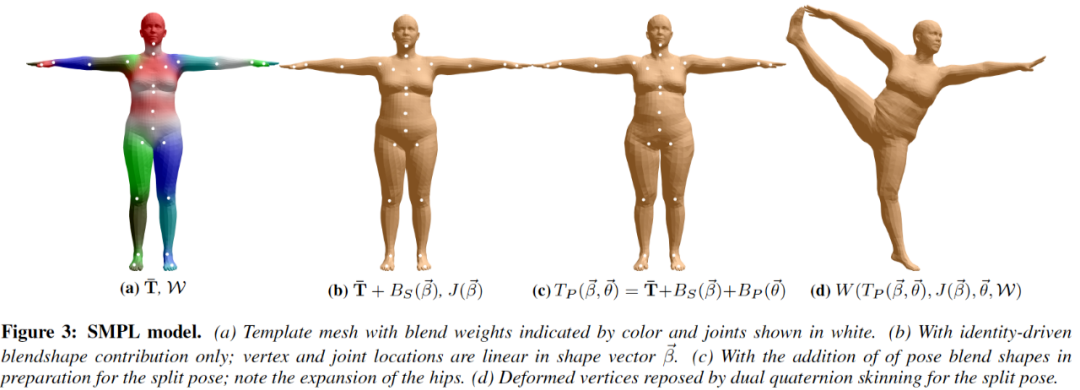
2.2 SMPL-X
基本表示:
mesh 表示:10475 vertices, 20908 faces
pose 控制:身体 54 个关节点,75 维 PCA
手部控制:24 维 PCA
表情控制:10 维向量
shape 控制:10 维向量
示意图:
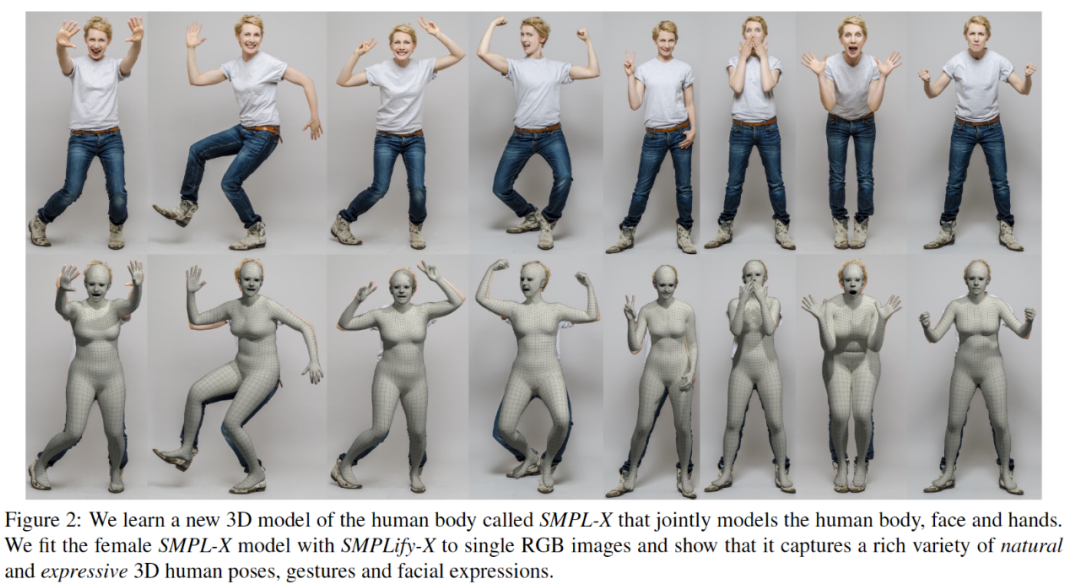

3D人体姿态估计
3D 人体姿态估计是指从图像、视频、或点云中估计人物目标的体型(shape)和姿态(pose),是围绕人体 3D 研究中的一项基本任务。3D 人体姿态估计是 3D 人体重建的重要前提,也可以是人体动作驱动中动作的重要来源。目前很多 3D 姿态估计算法主要是估计场景中人体的 SMPL 参数。
根据场景不同,可以分为针对单张图像和针对动态视频的人体 3D 姿态估计。下表简要总结了目前两种场景下的一些代表工作,并给出了一些简要原理介绍和评价。

3.1 单张图像
代表工作:
Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image. In ECCV, 2016.
End-to-end Recovery of Human Shape and Pose. In CVPR, 2018.
Learning to Estimate 3D Human Pose and Shape from a Single Color Image. In CVPR, 2018.
Delving Deep into Hybrid Annotations for 3D Human Recovery in the Wild. In ICCV, 2019.
SPIN: Learning to reconstruct 3d human pose and shape via model-fitting in the loop. In ICCV, 2019.
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh E
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8313
8313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









