







Bike Flow Prediction with Multi-Graph Convolutional Networks(基于多图卷积网络的自行车流量预测)
2018年第26届ACM空间地理信息系统进展国际会议论文集
论文链接:见这里
作者: Di Chai, Leye Wang, Qiang Yang
出版:ACM
关键字:多卷积GCN,自行车流量预测
摘要
管理自行车共享系统的一个基本问题是自行车流量预测。由于单站流量预测的困难,最近的研究经常在集群水平上预测流量。但是,它们不能直接指导站点级别的细粒度系统管理问题。在本文中,我们回顾了车站级自行车流量预测的问题,旨在利用深度学习技术的突破来提高预测精度。我们提出了一个多图卷积神经网络模型来预测站点级别的流量,其中的关键新奇之处在于从图的角度观察自行车共享系统。更具体地说,我们构建了一个自行车共享系统的多个图来反映异构的站间关系。然后,我们融合多个图,并应用卷积层来预测车站级的未来自行车流量。在真实的自行车流量数据集上的结果验证了我们的多重图模型可以通过减少高达25.1%的预测误差来超越最先进的预测模型。
abstract
One fundamental issue in managing bike sharing systems is bike flow prediction. Due to the hardness of predicting flow for a single station, recent research often predicts flow at cluster-level. However, they cannot directly guide fine-grained system management issues at station-level. In this paper, we revisit the problem of the stationlevel bike flow prediction, aiming to boost the prediction accuracy using the breakthroughs of deep learning techniques. We propose a multi-graph convolutional neural network model to predict flow at station-level, where the key novelty is viewing the bike sharing system from the graph perspective. More specifically, we construct multiple graphs for a bike sharing system to reflect heterogeneous inter-station relationships. Afterward, we fuse multiple graphs and apply the convolutional layers to predict station-level future bike flow. The results on realistic bike flow datasets verify that our multigraph model can outperform state-of-the-art prediction models by reducing up to 25.1% prediction error.
1 INTRODUCTION
自行车共享系统作为一种提供灵活的交通方式和减少温室气体排放的方式,在城市交通中越来越受欢迎。在自行车共享系统中,用户可以在附近的站点结账,然后将自行车归还到目的地附近的站点。自行车流量预测是自行车共享系统的关键研究和实践问题之一,在自行车再平衡等多项任务中发挥着重要作用[3,8]。
现实中,单个站点的自行车流通常具有复杂的动态模式,使得[3]难以预测。因此,最近大多数研究人员试图在集群水平上解决自行车流量预测问题。即,他们首先对站点进行分组,然后预测每个集群的自行车流量[3,8]。虽然聚类级别的预测精度较好,但有两点限制:(1)输出聚类是否合适难以评价;(2)聚类级别的预测结果不能直接支持单站管理。
本文重新审视站点级自行车流量预测问题,为共享单车管理员决策过程提供细粒度信息,避免难以评估的聚类问题。为了实现这一目标,我们提出了一种新的多图卷积神经网络模型来捕捉异构的站间空间相关性。传统的单站级预测通常更注重台站的历史数据,如ARIMA[10]。然而,除了时间相关性外,站点间空间相关性也可能在自行车流量预测中发挥重要作用。在这项工作中,我们提出了一种新的多图卷积神经网络来捕获站点之间的异构空间关系,如距离和历史使用相关性。在多图卷积层之后,构建了包含LSTM (Long-Short Term Memory)单元[5]的编码器-解码器结构来捕获时间模式。因此,有效地捕捉了车站级自行车流的空间和时间模式。
据我们所知,这是第一个利用多图卷积神经网络来预测自行车共享系统中站级自行车流量的工作。对纽约市和芝加哥的真实自行车流量数据进行了评估,结果表明了该方法的有效性。与最先进的车站级自行车流量预测模型相比,我们的多图卷积神经网络模型可以降低高达25.1%的预测误差。
Preliminary:图卷积神经网络(Graph Convolutional Neural Networks)是由Bruna等人[1]首先提出的,它将卷积层应用到图数据上。之后Defferrard等人利用快速本地化卷积对其进行了扩展。与我们的工作相关的两篇论文是[7,11],都使用了图卷积神经网络来预测路段的交通速度。注意[7,11]只使用距离来创建图形;然而,由于一个图可能无法全面描述站间关系,我们提出了新的方法(除了距离)来构建站间图,并进一步设计了一个多图卷积网络结构。
2 DEFINITIONS AND PROBLEM
在本节中,我们首先定义几个关键概念,然后阐明问题。
- 定义1:Bike-Sharing System Graph共享单车系统图:共享单车系统表示为一个加权图,节点为站点,边为站点间关系。边的权重表示站与站之间的关系强度。通常情况下,权重越大,两站相关性越高。如何构造图形是该方法的关键部分。
- 定义2:Bike Flow自行车流量:有两种类型的自行车流量:流入和流出( inflow and outflow)。假设有 N N N个自行车站点,时间间隔t(例如,1小时)的流入记为 I t = [ c i 1 t , c i 2 t , … , c i N t ] I t = [ci^t_1,ci^t_2,…,ci^t_N] It=[ci1t,ci2t,…,ciNt],流出量表示为 O t = [ c o 1 t , c o 2 t , … , c o N t ] Ot = [co^t_1,co^t_2,…, co^t_N] Ot=[co1t,co2t,…,coNt]。
- 问题:假设当前时间为t−1,我们有历史数据
[
(
I
0
,
O
0
)
,
(
I
1
,
O
1
)
,
…
,
(
I
t
−
1
,
O
t
−
1
)
]
[(I^0,O^0), (I^1,O^1),…,(I^{t−1},O^{t−1})]
[(I0,O0),(I1,O1),…,(It−1,Ot−1)]。问题是预测下一次的自行车流量
(
I
^
t
,
O
^
t
)
(\hat{I}^t,\hat{O}^t)
(I^t,O^t),旨在:
min ∣ ∣ I ^ t − I t ∣ ∣ 2 2 , min ∣ ∣ O ^ t − O t ∣ ∣ 2 2 \min ||\hat{I}^ t − I t ||^2_2, \min || \hat{O}t − Ot ||^2_2 min∣∣I^t−It∣∣22,min∣∣O^t−Ot∣∣22
其中 ( I t , O t ) (I^t,O^t) (It,Ot)为下一次t的地面真理自行车流。
3 MULTI-GRAPH CONVOLUTIONAL NEURAL NETWORK MODEL
我们提出了一种新的多图卷积神经网络模型(图1),包括图生成graph generation,、多图卷积multi-graph convolution和预测网络prediction network三个步骤:
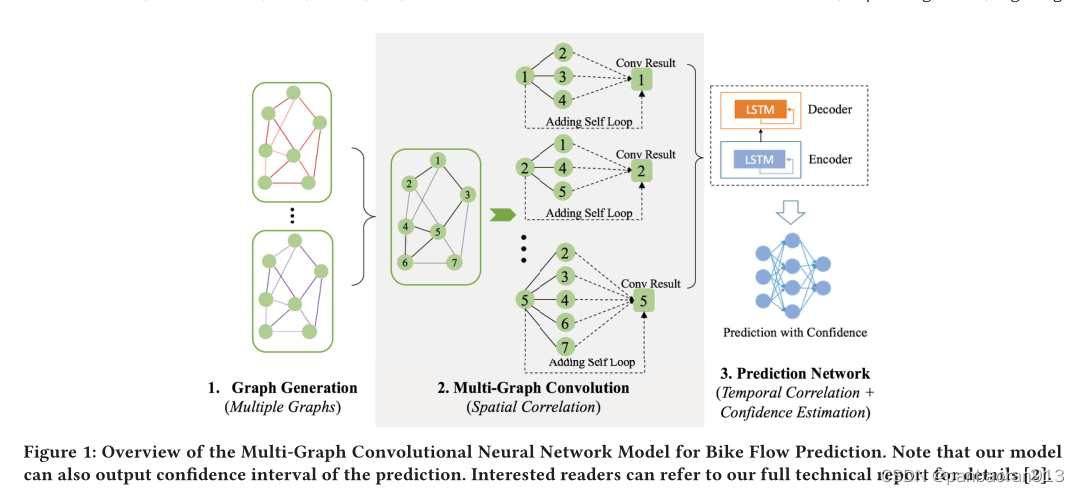
3.1 Graph Generation
图的生成是图卷积模型成功的关键。如果构造的图不能对站间的有效关系进行编码,将不利于网络参数学习,甚至会降低预测性能。一般来说,我们希望将较大的权重分配给具有相似动态流模式的站点之间的边缘。在此基础上,我们提出了三种建立站间图的方法:距离图distance graph, 交互图interaction graph和相关图correlation graph。
- Distance Graph:托布勒的第一地理定律指出:“一切事物都与其他事物相关,但近的事物比远的事物联系更密切(Tobler’s first law of geography has pointed out that ‘everything is related to everything else, but near things are more related than distant things’. )。在自行车共享系统中,对于相邻的两个站点(例如地铁站周围),它们可能共享相似的使用模式。按照这个思路,我们用距离来构造站间图。更具体地说,我们使用距离的倒数来标记两个站点之间的权重,这样更近的站点将与更高的权重相关联。
G d ( V , E ) w e i g h t = D i s t a n c e − 1 Gd (V , E) \quad weight = Distance^{−1} Gd(V,E)weight=Distance−1 - Interaction Graph:历史乘车记录也可以提供大量的信息来构建站间图。例如,如果
i
i
i站和
j
j
j站之间存在很多骑行记录,那么在动态自行车流模式上,
i
i
i站和
j
j
j站之间往往会相互影响。基于这一思想,我们根据历史乘车记录构建了一个交互图来表示两个站点之间是否频繁交互。记
d
i
,
j
d_{i, j}
di,j为i和j之间的骑行记录数,我们建立的交互图为:
G i ( V , E ) w e i g h t = # R i d i n g R e c o r d N u m b e r Gi (V , E) \quad weight = \#RidingRecordNumber Gi(V,E)weight=#RidingRecordNumber - Correlation Graph:利用乘车记录,我们还尝试了另一种方法,利用车站历史使用的相关性来构建车站间图。即我们计算每个站点在每个时隙(如1小时)的历史使用量(流入或流出),然后计算每两个站点之间的相关性,作为图中的站间链路权值。在这项工作中,我们使用流行的皮尔逊系数来计算相关性。记ri, j为i站与j站之间的Pearson相关关系,表示相关图如下:
G c ( V , E ) w e i g h t = C o r r e l a t i o n Gc (V , E) \quad weight = Correlation Gc(V,E)weight=Correlation
3.2 Multi-graph Convolution
为了充分利用包含异构有用空间相关信息的不同站间图(different inter-station graphs that contain hetero-geneous useful spatial correlation information),我们在神经网络模型中提出了一种新的多图卷积层。它是能够对不同类型的图进行图卷积,首先将其合并在一起。多图卷积有两个主要步骤:图融合Graph fusion和图卷积Graph convolution。
- Graph fusion:图融合步骤将不同的图合并成一个融合图。我们在元素级通过加权和邻接矩阵来组合不同的图。由于不同图的邻接矩阵的值可能落在不同的范围内,我们首先对每个图归一化邻接矩阵A, A ′ = D − 1 A + I A' = D^{−1}A +I A′=D−1A+I

A’是含自环的归一化邻接矩阵。自环可以在卷积部分维护目标站本身的信息,这是图卷积神经网络所需要的设计策略。
为了使加权和运算后的融合结果保持归一化,我们进一步在权值矩阵中加入softmax运算。
假设我们有N个图要融合在一起,我们可以将图融合过程表示为:
W
′
1
,
W
′
2
,
.
.
.
,
W
′
N
=
S
o
f
t
m
a
x
(
W
1
,
W
2
,
.
.
.
,
W
N
)
W '1 ,W '2 , ...,W 'N = Sof tmax (W1,W2, ...,WN )
W′1,W′2,...,W′N=Softmax(W1,W2,...,WN)
F
=
∑
i
=
1
N
W
i
′
⊙
A
′
F =\sum_{i=1}^N W'_i \odot A'
F=i=1∑NWi′⊙A′
where
⊙
\odot
⊙是逐元素乘法,
F
F
F是将用于图形卷积部分的图形融合结果
- Graph convolution:Graph convolution:根据图融合结果F,对图进行卷积运算为
H 0 t ′ = ( I t ′ , O t ′ , t ′ ∈ [ 0 , t − 1 ] ) H_0^{t'}=(I^{t'},O^{t'},t'\in [0,t-1]) H0t′=(It′,Ot′,t′∈[0,t−1])
H 1 t ′ = F × W c × H 0 t ′ H_1^{t'}=F\times W_c \times H_0^{t'} H1t′=F×Wc×H0t′
wherer W c W_c Wc是卷积权矩阵, H 0 t ′ H_0^{t'} H0t′是在时间 t ′ t' t′的bike flow. H 1 t ′ H_1^{t'} H1t′是卷积结果,之后作为预测网络的输入。
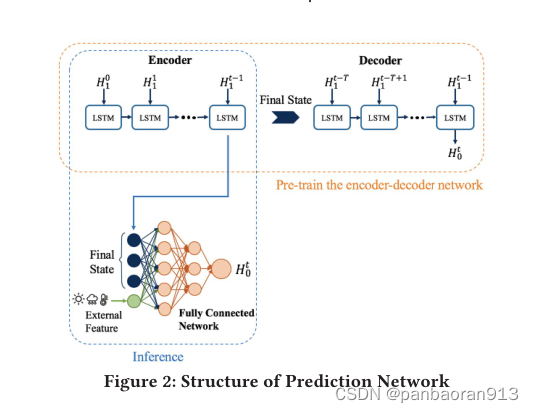
3.3 Prediction Network
如图2所示,采用编码器-解码器结构的预测网络细节如下。编码器网络采用多图卷积结果序列
[
H
1
0
,
H
1
1
,
…
,
H
1
t
−
1
]
[H ^0_1, H^1_1,…, H ^{t−1}_1]
[H10,H11,…,H1t−1]作为输入,将时间模式编码为滚动过程后的LSTM细胞的最终状态。解码器网络以编码器的终态为初始态,多图卷积结果序列
[
H
1
t
−
T
,
H
1
t
−
T
+
1
,
…
,
H
1
t
−
1
]
[H^{t−T}_1, H^{t−T +1}_1,…, H^{t−1}_1]
[H1t−T,H1t−T+1,…,H1t−1]作为输入。解码器的输出是我们的预测目标
H
0
t
H^t_0
H0t。我们可以将T设为一个较小的值(例如,T的一半),这意味着解码器可以根据短时间的历史数据和编码器的最终状态预测未来的自行车流量。这意味着编码器的最终状态为预测过程提供了重要的信息。在训练完编码器-解码器结构后,我们将编码器网络的最终状态,结合一些外部环境特征(如温度、风速、工作日/周末[12])输入到一个全连接网络(图2下半部分),用于预测下一次
H
0
t
H^t_0
H0t时间的自行车流量。
4 EV ALUATION
4.1实验设置
数据集:我们使用从纽约市和芝加哥(网站2, https://www.divvybikes.com/system-data)收集的自行车流量数据集。数据集涵盖了4年的时间段(20132017)。所有数据均为骑行记录形式,包含启动站、启动时间、停止站、停止时间等。天气数据来自NCEI(网站3,https://www.ncdc.noaa.gov/data-access)
设置训练-验证-测试数据分割,我们选择每个城市最后80天的数据作为测试数据,测试前40天的数据为验证数据,验证数据前的所有数据为训练数据。预测粒度设置为1小时。读者可以从https://github.com/Di-Chai/GraphCNN-Bike找到代码。
Network Implementation and Parameters : 实验中的编码器和解码器包含一层LSTM和64个隐藏单元。全连通预测网络包括输入层和输出层4层。我们选择优化算法ADAM,学习率设置为0.001%[6]。在预测网络的编码器-解码器结构中,我们在解码器中设T = 3(参见图2)。我们使用过去6小时的历史数据来预测未来1小时的自行车流量。
Baselines: 我们将我们的多图卷积网络模型与以下基线进行比较:
- HM[8]:历史平均值根据同一工作日、同一小时的历史平均值预测某时段的自行车流量。
- ARIMA[10]:自回归综合移动平均线是一个被广泛使用的时间序列预测模型。
- SARIMA [10]: ARIMA的季节性版本。
- GBRT [8]: Gradient Boosting Regression Tree在文献中也被广泛用于自行车流量预测。
- LSTM[9]:最近的交通流预测研究,如[9],采用了长短期记忆(LSTM)递归神经网络模型,并验证了其有效性。
4.2 Experiment Results
预测误差:我们使用均方根误差(RMSE)来测量预测误差。表1显示了结果。总的来说,我们的多图卷积方法在纽约市和芝加哥的平均预测误差分别降低了25.1%和15.8%,仍然可以显著地击败最佳基线。

除了平均站级预测误差之外,我们还研究了两个城市中使用率最高的站点的预测结果。这些繁忙的车站的预测准确性可能更重要,因为大多数过度需求的问题(“没有自行车使用”或“没有码头还自行车”)可能发生在这些车站[3]。因此,我们选择了最繁忙的5个和10个站点来研究这两个城市的结果。我们观察到,我们的多图方法对于繁忙的站点也能持续得到更好的结果。例如,对于纽约市最繁忙的5个和10个车站,我们的方法可以分别比LSTM高出30.2%和25.2%。这进一步验证了我们提出的方法在现实自行车共享系统管理中的实用性。
多图融合的有效性:现在我们验证我们的多图融合策略确实可以给预测模型带来好处。图3显示了我们仅使用一个图(距离、相互作用或相关图)来预测纽约市时的结果。与单图卷积方法相比,我们的多图卷积方法具有一致的更好的性能。例如,对于纽约市最繁忙的5个车站,多图模型可以比单图模型降低5.6-9.2%的误差。这种改善也被证实具有统计学意义(p值< 0.05)。

计算效率:我们的实验运行在Windows服务器上,CPU: Intel Xeon E5-2690,内存:56 GB, GPU: Nvidia Telsa K80。训练时间大约需要2到3个小时,而推断只需要几秒钟。由于训练过程是离线过程,这种运行效率对于现实生活中的自行车流量预测系统来说已经足够了。
5 CONCLUSION
本文提出了一种新的多图卷积神经网络模型来预测自行车共享系统站点级自行车流量。新颖的方面是多图卷积部分,它将图信息应用于流量预测。更具体地说,我们设计了三个异构站间图来表示一个自行车共享系统,即距离图、交互图和相关图;然后提出了一种融合方法,对三个图同时进行图卷积运算。未来,我们计划将多图模型扩展到更多的场景,如地铁站人流预测。
MGCN的搭建
第一种?
import torch
from torch.nn import Parameter
from torch_geometric.nn.inits import uniform, ones, glorot, normal
class MGConv(torch.nn.Module):
"""
Args:
in_channels (int): Size of each input sample.
out_channels (int): Size of each output sample.
K (int): Number of scales.
bias (bool, optional): If set to :obj:`False`, the layer will not learn
an additive bias. (default: :obj:`True`)
"""
def __init__(self, in_channels, out_channels, K, bias=True, number=0):
super(MGConv, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.weight = Parameter(torch.Tensor(K, in_channels, out_channels))
self.number = number
self.K = K
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
# normal(self.weight, 0, 0.1)
glorot(self.weight)
# ones(self.weight)
if self.bias is not None:
ones(self.bias)
def forward(self, x, Win):
for i in range(self.weight.size(0)):
if i == 0:
out = torch.matmul(x, self.weight[0])
else:
WWW = torch.matmul(torch.t(Win[i-1]), x)
out += torch.matmul(WWW, self.weight[i])
torch.cuda.empty_cache()
return out
def __repr__(self):
return '{}({}, {}, K={})'.format(self.__class__.__name__,
self.in_channels, self.out_channels,
self.weight.size(0))














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









