







《Efficient Convolutional Neural Networks for Mobile Vision Applications》
1.亮点
MobileNet是为手机等移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构,使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。介绍了两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。
深度学习在图像分类,目标检测和图像分割等任务表现出了巨大的优越性。但是伴随着模型精度的提升是计算量,存储空间以及能耗方面的巨大开销,对于移动或车载应用都是难以接受的。传统的CNN模型首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快。所以,研究小而高效的CNN模型在这些场景至关重要。
目前的研究总结来看分为两个方向:
一是对训练好的复杂模型进行压缩得到小模型;
二是直接设计小模型并进行训练。
不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。本文的主角MobileNet属于后者,是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
2.Depthwise separable convolution(深度可分离卷积)
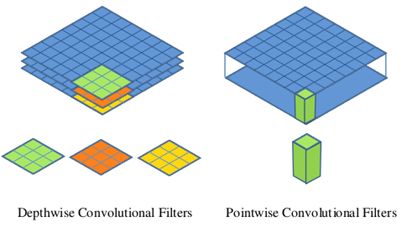
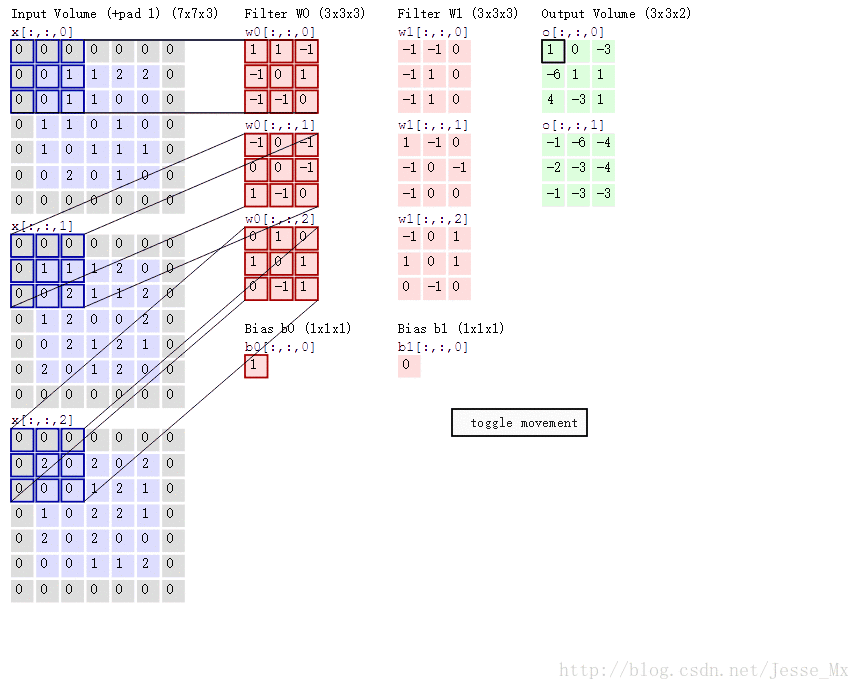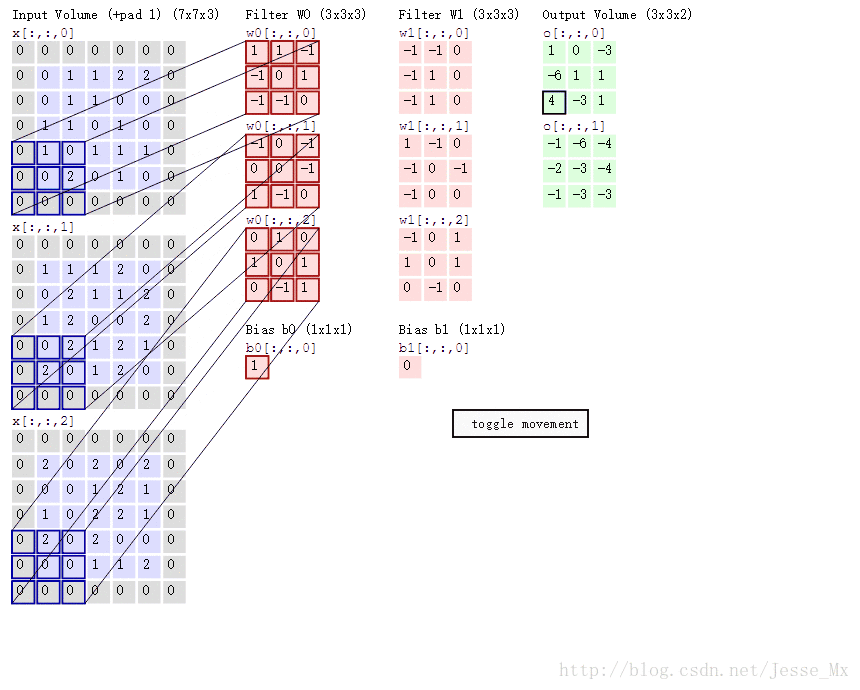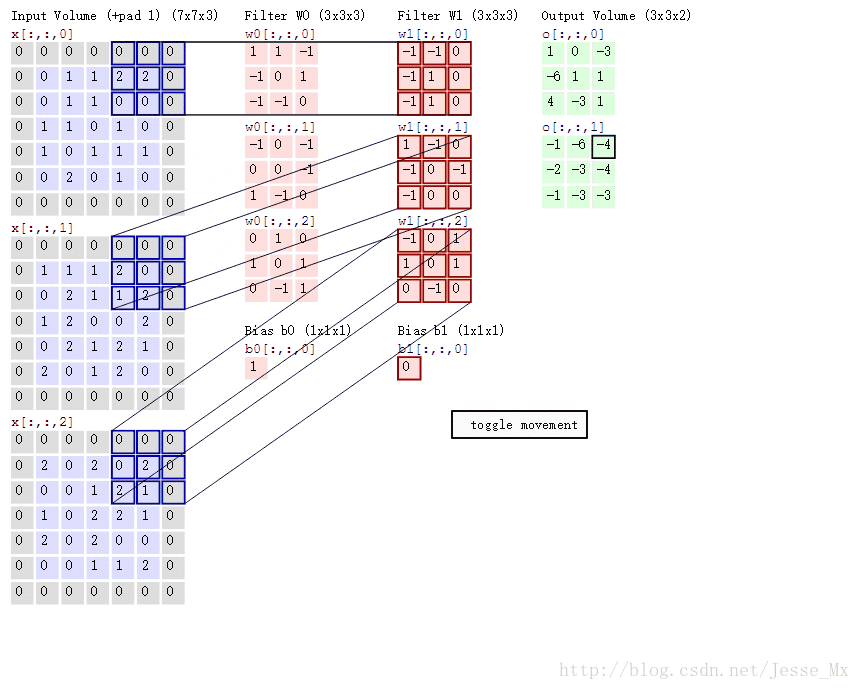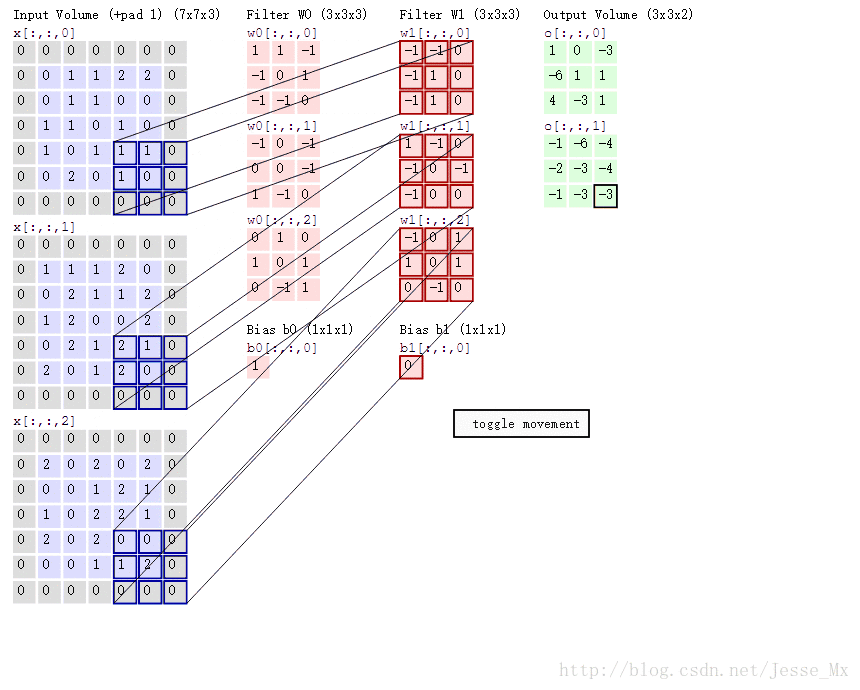
深度可分离卷积其实是一种可分解卷积(factorized convolutions),可分解为两个更小的操作:depthwise convolution(深度卷积)和pointwise convolution(逐像素卷积)。标准卷积其卷积核作用在所有的输入通道上(input channels),而depthwise convolution针对每个输入通道采用不同的卷积核,就是说一个卷积核对应一个输入通道,所以说depthwise convolution是depth级别的操作。而pointwise convolution(逐像素卷积)其实就是普通的卷积,只不过其采用1x1的卷积核。图2中更清晰地展示了两种操作。对于深度可分离卷积,其首先是采用depthwise convolution(深度卷积)对不同输入通道分别进行卷积,然后采用pointwise convolution(逐像素卷积)将上面的输出再进行结合,这样其实整体效果和一个标准卷积是差不多的,但是会大大减少计算量和模型参数量。
与标准卷积网络不同的是,深度可分离卷积将卷积核拆分成单通道形式,在不改变输入特征图像的深度的情况下,对每一通道进行卷积操作,这样就得到了和输入特征图通道数一致的输出特征图;逐点卷积就是1×1卷积。主要作用就是对特征图进行升维和降维。

实例分析:
标准卷积:假设输入feature map为12×12×3,经过一个5×5×3的卷积核卷积得到一个8×8×1的输出特征图。若输出有256个feature map,我们将会得到一个8×8×256的输出feature map。
深度可分离卷积:
1.假设输入feature map为12×12×3,首先经过5×5×1×3的深度卷积之后,得到了8×8×3的输出特征图;
2.再用256个1×1×3的卷积核对输入feature map进行逐点卷积,输出的feature map为8×8×256。
理解:
优势:用更少的参数,更少的运算,但是能达到差不多的结果
标准卷积的参数量:
![]()
标准卷积的计算量:
![]()
深度可分离卷积的参数量由深度卷积和逐点卷积两部分组成:
深度可分离卷积的参数量:
![]()
深度可分离卷积的计算量:
![]()
两者对比:一般情况下N比较大,那么如果采用3x3卷积核的话,depthwise separable convolution相较标准卷积可以降低大约9倍的计算量。
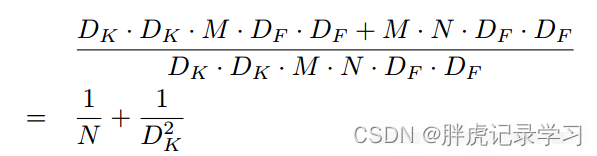
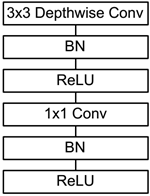
网络结构:
在卷积后加入BN层与Relu激活函数
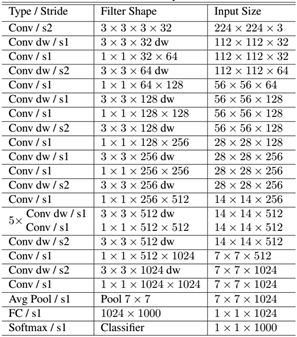
3.MobileNet网络结构
除了最后的FC层没有非线性激活函数,其他层都有BN和ReLU非线性函数。MobileNet的网络结构如图所示。首先是一个3x3的标准卷积,s2进行下采样。然后就是堆积深度可分离卷积,并且其中的部分深度卷积会利用s2进行下采样。然后采用平均池化层将feature变成1x1,根据预测类别大小加上全连接层,最后是一个softmax层。
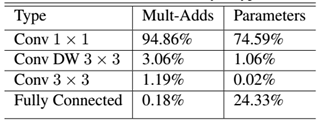
模型几乎将所有的密集运算放到1×1卷积上,这可以使用general matrix multiply (GEMM) functions优化。在MobileNet中有95%的时间花费在1×1卷积上,这部分也占了75%的参数:
4.Width Multiplier: Thinner Models (瘦身)
两个超参数:width multiplier(宽度因子)和resolution multiplier(分辨率因子)
第一个参数width multiplier主要是按比例减少输入输出通道数,该参数记为 ,其取值范围为(0,1],那么输入与输出通道数将变成
和
;
第二个参数resolution multiplier主要是按比例降低特征图的大小,记为,其取值范围为(0,1],比如原来输入特征图是224x224,可以减少为192x192。
5.总结
论文提出了一种基于深度可分离卷积的新模型MobileNet,同时提出了两个超参数width multiplier(宽度因子)和resolution multiplier(分辨率因子)用于快速调节模型适配到特定环境。
参考:
仅为学习记录,侵删!
















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











