







FBNetv1
论文地址: CVPR 2019
《FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search》
问题
传统卷积神经网络的设计除了注重准确率之外,还需要兼顾运行性能,特别是在移动设备上的运行性能,这使得卷积神经网络的设计变得更加困难,主要有以下难点:
- Intractable design space(未知的设计空间),由于卷积网络参数很多,导致设计空间十分复杂,目前很多方法提出自动化搜索,能够简化人工设计的流程,但这种方法一般需要大量的算力,卷积网络的设计空间是组合的,训练卷积网络是非常耗时的,因此之前的网络设计基本不怎么搜索整个设计空间。采用强化学习和遗传算法的NAS非常耗时;
- Nontransferable optimality(不可广泛移植的最优解),卷积网络的性能取决于很多因素,比如输入分辨率和目标设备,不同的分辨率需要调整不同的网络参数,而相同block在不同的设备上的效率也可能大不相同,所以需要对网络在特定的条件下进行特定的调优,一旦这些因素改变,最优解的结构就会变化;
- Inconsistent efficiency metrics(不一致的效率度量),大多数效率指标不仅与网络结构相关,也和目标设备上的软硬件设置有关,之前的许多工作都用了硬件无关的度量比如FLOPs(乘加操作的次数)去评估效率。然而,FLOP计数低的网络不一定快,还跟block的实现方式相关。硬件无关的度量和实际的效率之间的不一致性使卷积网络的设计更加困难。
作者提出了一种可微神经架构搜索(DNAS)框架,使用基于梯度的方法去优化卷积网络结构:DNAS用操作随机执行的超级网络代表搜索空间,将找到最佳架构的问题放松到找到产生最佳架构分布的问题,通过使用Gumbel Softmax技术,可以直接基于梯度优化(SGD)的方法训练结构分布。用于训练随机超级网络的损失不仅仅是交叉熵损失,还包括延时损失,为了评估网络结构的延时,本文将计算搜索空间每个操作的延时并且使用速查表模型去计算所有操作的延时(每个操作的时间加起来),使用这个模型可以快速的估量庞大的搜索空间中网络结构的延时。更重要的是,它使得延时关于层结构选择是可微的,
DNAS(可微神经架构搜索)
NAS的可以参考我之前的一篇博客:地址
由于描述神经网络结构的参数含有离散数据(如拓扑结构的定义,层的类型,层内的离散型超参数),因此网络结构搜索是一个离散优化问题;
定义结构的参数数量一般比较大,因此属于高维优化问题。另外,对于该问题,算法不知道优化目标函数的具体形式(每种网络结构与该网络的性能的函数关系),因此属于黑盒优化问题。这些特点为NAS带来了巨大的挑战;
传统的基于强化学习、遗传算法的NAS算法都存在计算量大的问题,这些方案低效的一个原因是结构搜索被当作离散空间(即网络结构的表示是离散的,如遗传算法中的二进制串编码)中的黑箱优化问题,无法利用梯度信息来求解;
一种解决思路是将离散优化问题连续化,称为可微结构搜索(Differentiable Architecture Search,DARTS)的算法,将网络结构搜索转化为连续空间的优化问题,采用梯度下降法求解,可高效地搜索神经网络架构,同时得到网络的权重参数:
DARTS将网络结构、网络单元表示成有向无环图,对结构搜索问题进行松弛,转化为连续变量优化问题;
目标函数是可导的,能够用梯度下降法求解,同时得到网络结构和权重等参数;算法通过寻找计算单元,作为最终网络结构的基本构建块;这些单元可以堆积形成卷积神经网络,递归连接形成循环神经网络;
DNAS支持去搜索层级搜索空间(layer-wise search space ),作者给网络的每一层选择一个不提供的块。DNAS通过一个super net表达搜索空间,super net的运算符是随机执行的(DNAS represents the search space by a super net whose operators execute stochastically.)。我们放宽寻找最优结构的问题,而去寻找产生最优结构的分布。使用Gumbel Softmax技术,我们可以使用基于梯度的优化方法比如SGD直接训练结构分布。
搜索过程与之前的基于强化学习的方法相比是非常快的。用来训练stochastic super net的loss由改善准确率的交叉熵loss和减少目标设备延时的延时loss组成。为了估量一个网络结构的延时,我们会计算搜索空间每个操作的延时并且使用速查表模型去计算所有操作的延时(每个操作的时间加起来),使用这个模型可以快速的估量庞大的搜索空间中网络结构的延时,更重要的是,它使得延时关于层结构选择是可微的。
相关工作
Efficient ConvNet models(高效的卷积模型):
近年来设计高效的卷积网络吸引了许多研究者:
SqueezeNet是早期致力于研究减少卷积模型参数量的早期工作之一;
后来的SqueezeNext和ShiftNet实现了更多的参数削减;
近来的研究从参数量转移到了FLOPs:
MobileNetV1和MobileNetV2使用depthwise卷积去替换更加昂贵的空间卷积;
ShuffleNet使用组卷积和shuffle操作去进一步减少FLOP次数;
之后的研究发现FLOP计数并不总能反应真实的硬件效率:
为了改善实际延时,ShuffleNetV2提出了一些列高效网络设计的实践指南;
有研究人员结合ShuffleNetV2和ShiftNet的思想去协同设计硬件友好的卷积网络和FPGA加速器;
Neural Architecture Search(神经架构搜索):
早期工作首先提出了使用强化学习去搜索神经网络架构以实现用较小的FLOPs达到可比较的准确率;
然而早期的NAS方法计算量是很大的。进来的研究试图通过权重共享或者基于梯度的方法减小计算代价;
后来又进一步发展了可微神经架构搜索和Gumbel Softmax结合的思想;
早期关于NAS的研究着重于cell 级的架构搜索,并且同样的cell结构在网络的所有层重复;然而,如此破碎和复杂的cell级结构是硬件不友好的,并且实际效率也很低。最近,有研究者研究了一个stage级的分层搜索空间,允许不同的block用于网络的不同stage,不过同一个stage中的block仍然是相同的。
不同于关注FLOPs,有研究关注于优化目标设备的延时;不仅仅是搜索新的架构,还有研究集中于提高现有模型的效率;
Gumbel Softmax

基于DNAS的方法
FBNet v1的训练方法和构建网络的方法基本上沿用了DARTS的方法,不同的是DARTS的Super net主要体现在Cell结构里,搜索空间包括cell内部的连接和路径上的操作;而FBNet体现在整个网络的主体里,连接是确定的,只搜索路径上的操作。
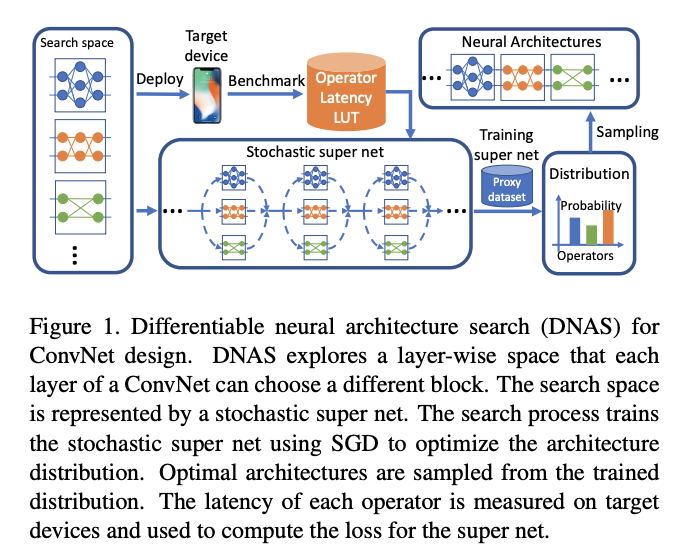
DNAS方法将整体的搜索空间表示为超网,在超网里,每个搜索路径上都并列放置着搜索空间里的操作,有不同的架构参数用于表示这些操作的权重;
将寻找最优网络结构问题转换为寻找最优的候选block分布,通过梯度下降来训练block的分布,而且可以为网络每层选择不同的block。
为了更好的估计网络的时延(Latency),预先测量并记录了每个候选block的实际时延,在估算时直接根据网络结构和对应的时延累计,和准确率一起作为优化的目标;
在搜索结束后,根据架构参数生成每条路径上的概率分布,从中采样出最好的网络作为输出,一般选取每条路径上概率值最高的操作。
方法
神经架构搜索问题用公式表示:
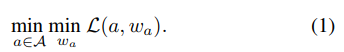
给定一个结构空间A,期望去寻找一个最优结构,使得训练它的权重
之后,可以使得损失
最小化。
即考虑搜索空间A、延时损失函数、搜索算法:
搜索空间A
之前的NASNet关注cell级别的搜索,一旦cell搜索到,网络就由这些cell堆叠得到;但是,许多搜索得到的cell非常复杂和琐碎,因此在移动端前向速度很慢;而且,同一结构的cell在不同深度的精度和延时有不同影响,因此FBNet v1允许不同的层选择不同的blocks来获得更好的精度和延时。
作者通过建立一个层次级别的搜索空间,其宏观结构固定,但是每层可以选择不同的block,整体结构如下图:
Block这一列代表着block的类型,“TBS”表示需要被搜索层类型,f列代表着一个Block中卷积核的个数,n列代表着Block的个数,s列代表着第一个Block的stride。

网络整体结构确定了网络层数和每层的输入输出的维数,网络的前三层和最后三层有着固定的操作。对于剩下的层,他们的Block需要被寻找。每层的卷积核个数是人为预先确定好的,对于浅层,使用相对较小的通道数,因为浅层的特征图分辨率较大,FLOP与输入尺寸的二次幂成正比;
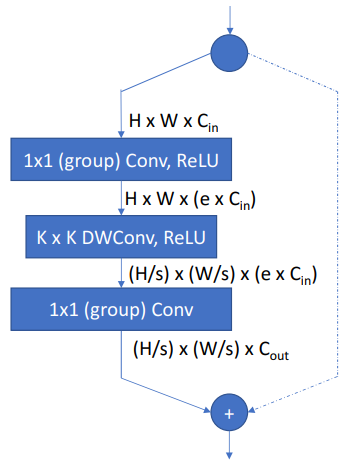
网络中的每个可搜索层可以从层次搜索空间中选择不同的块,Block的结构来源于MobileNetv2和ShiftNet,如下图:
包含depthwise卷积以及两个Group point-wise卷积,ReLU函数跟在第一个卷积和第二个卷积之后,最后一个卷积之后不接激活函数;同样仿照以一个扩展比例e来控制Block,它决定了第一个卷积将输入特征图的通道扩大多少;
左边先通过1× 1的分组卷积将channel放大,后面跟一个shuffle的操作,混合不同group的特征,然后再用核为K×K大小的可分离深度卷积进行计算,如果某个stage的stride为2,在该stage的第一个TBS block的可分离卷积stride设置成2,最后再用1×1的分组卷积将channel调整成stage的输出通道数大小;右边的分支就是一个跳跃连接,如果stride为1,就是直接连接,如果stride为2,通过stride=2的卷积将特征图调整成和左边一致的shape大小。
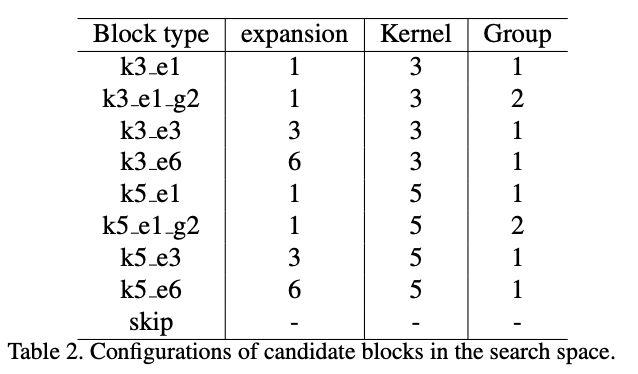
层级的搜索空间包含9个候选Blocks,它们的设置如下表:
k表示可分离卷积核大小,e表示中间channels的放大倍数,g表示分组的个数,skip表示直接将输入特征图输出而不经过任何操作,候选Block可以帮助降低网络的深度,整体来看,搜索空间包含22层,每层可以选择9种候选的Blocks,所以它包含个可能的结构;
延时损失函数
损失函数不仅要反映准确率:标准的分类交叉熵损失项,也要反应目标硬件上的时延Latency, 损失函数具体格式如下:
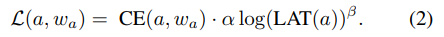
a表示网络架构,表示网络的权重参数,CE
表示交叉熵函数,α为时延项的系数,
为调整时延项的幅值,LAT
表示当前结构在目标硬件上的时延Latency;
搜索空间包含个可能的结构,所以时延的计算比较耗时,因此使用延时速查表模型去估计一个网络的整体延时,这个速查表基于每个操作的运行时间,定义:
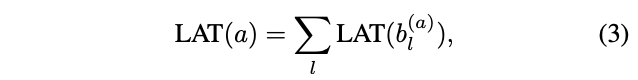
为结构a中l层的block,这种估计方法假设block间的计算相互独立,对CPUs和DSPs等串行计算设备有效;
搜索空间表示为一个随机的超网。这个超网有着22层整体结构,每层包含9个并行的Blocks,在超网的前向过程中,只有一个候选的Block被采样,候选block被执行的概率为:
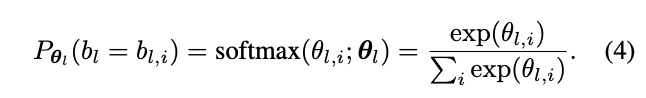
包含决定l层每个候选block采样概率的参数,l层的输出可表示为:
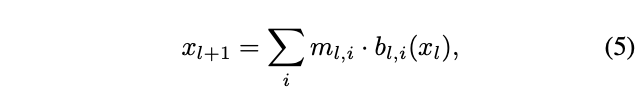
是(0, 1)随机变量,根据采样概率随机赋值,l层输出为所有block的输出之和。
网络结构a的采样概率可表示为:
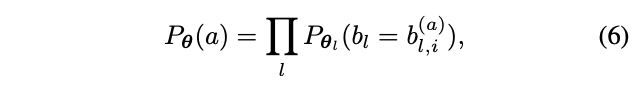
包含所有block的
,所以公式(1)可表示为:

权值是可导的,但
仍然不可导,因为
的定义是离散的,为此将
的生成方法转换为Gumbel Softmax:
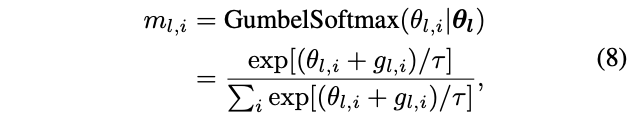

为Gumbel分布的随机噪声,为温度参数。当
接近0时,
类似于one-shot,当
越大时,
类似于连续随机变量。
交叉熵损失就可以对和
求导,而时延项也可以改写为:
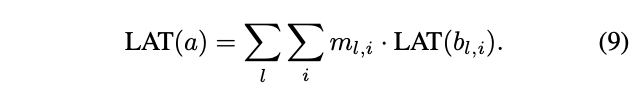
由于使用lookup表格,所以是个常量因子,网络A的整体时延对
和
也是可导的。
所以损失函数对权值和结构变量
都是可导的,可以使用SGD来高效优化损失函数。
搜索算法
由于损失函数可以用SGD来进行优化,搜索过程等价于去训练随机super net:训练过程中,计算损失对于权重的偏导数去训练super net中每个操作的权重,这部分与传统的卷积神经网络没有分别,操作搜索训练完成后,不同的操作使得整体网络的精度和速度不同,因此计算损失对于网络结构分布的偏导数
,去更新每个操作的抽样概率
;这一步会使得网络整体的精度和速度更高,因为抑制了低精度和低速度的选择,super net训练完成之后,可以从结构分布
中抽样获得最优的结构;
实验
搜索结构可视化:
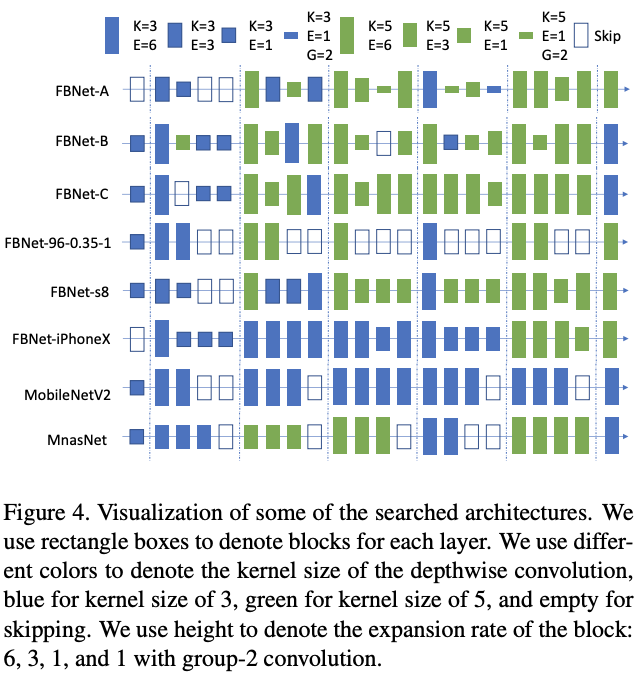
在搜索过程中,只选取了ImageNet的其中100类作为训练数据,训练90个epoch,每个epoch中,80%的数据用来训练网络参数,20%的数据用来训练架构参数,统计latency的设备采用三星Galaxy S8。搜索完成后,从中挑取了三个不同大小的代表网络进行训练,FBNet-A和FBNet-B、FBNet-C的区别在于最后一个卷积的输出channel不一样,结果如下图所示:
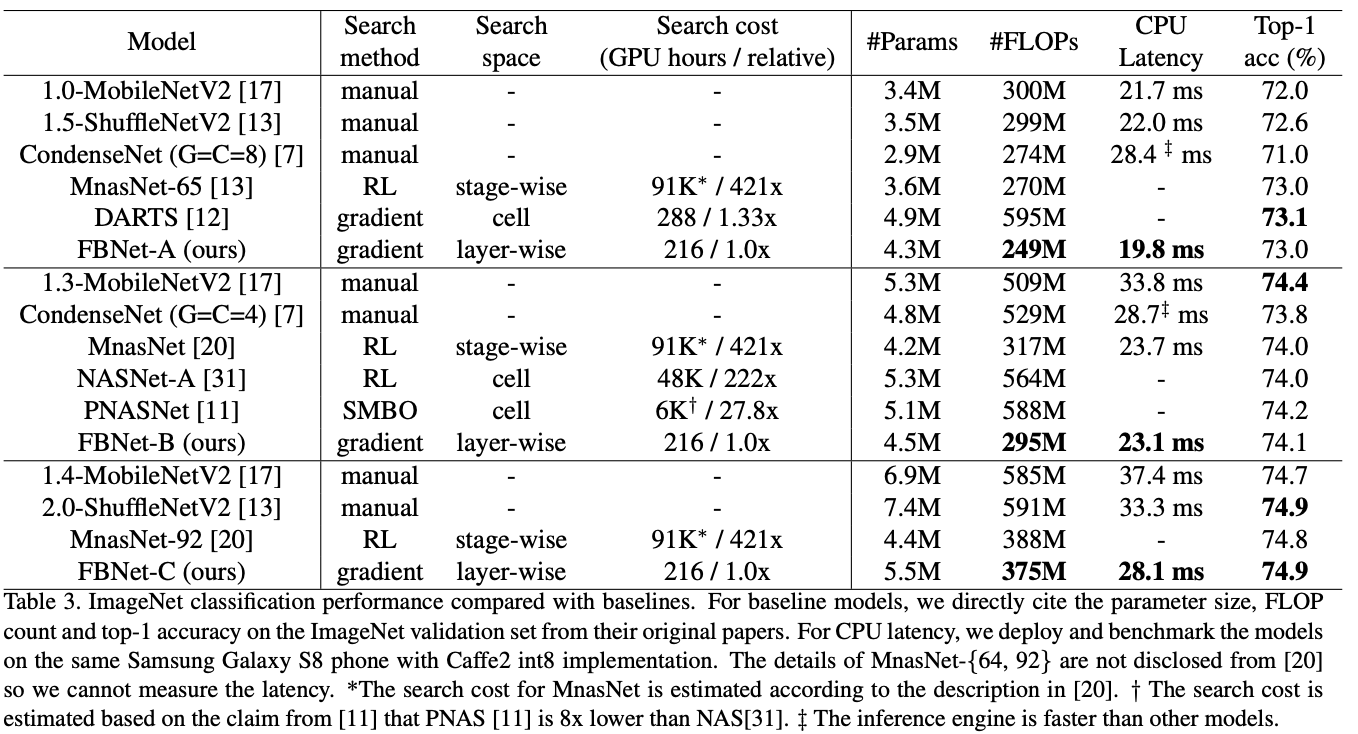
与各轻量级网络对比在ImageNet上的性能对比与特定资源和设备条件下的性能对比:
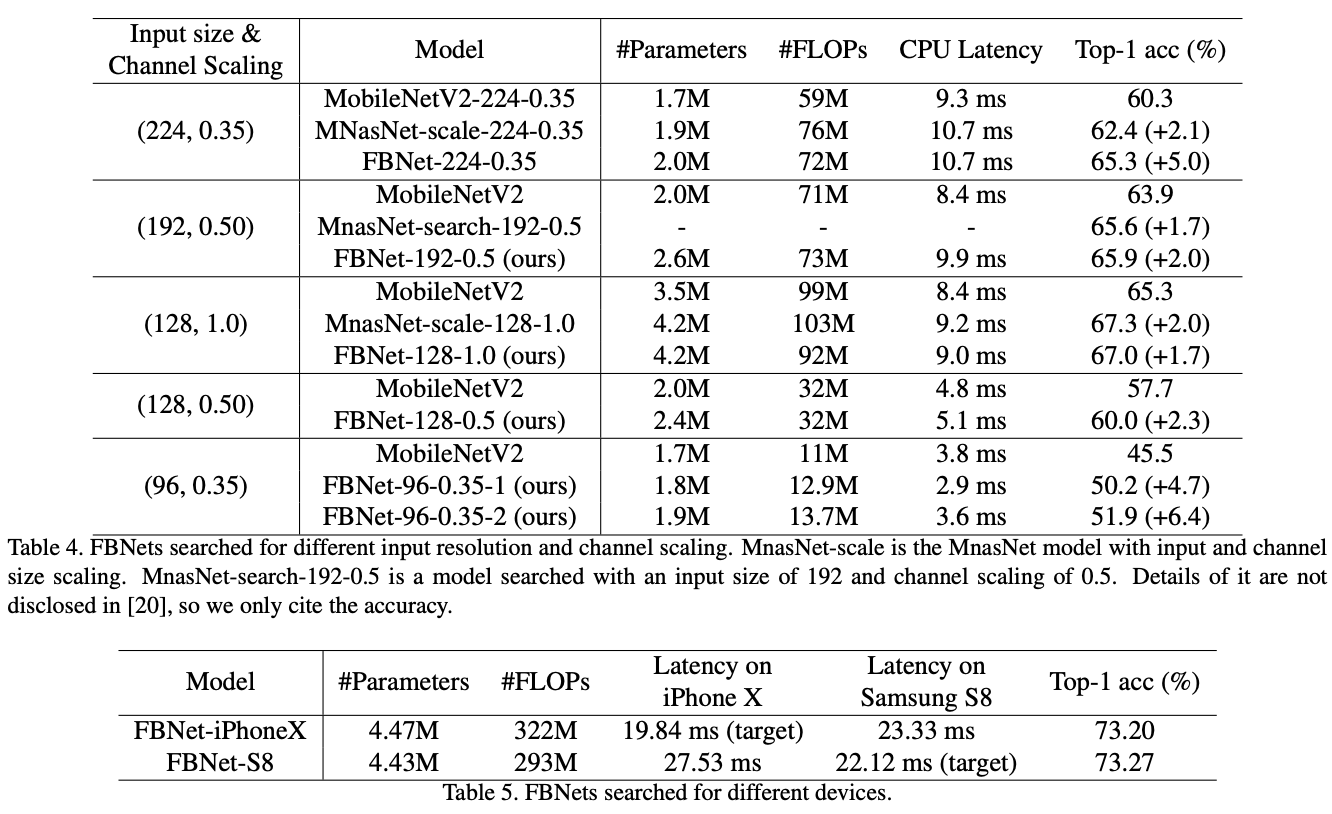
总结
提出一种可微的神经网络搜索方法(DNAS),将离散的单元结构选择转换为连续的单元结构概率分布,另外将目标设备时延Latency加入到优化过程中,结合超网的权值共享,能够快速地端到端地生成特定条件下的高性能轻量化网络;
DNAS算法比先前基于RL的NAS快几个数量级;
论文的block框架基于MobileNetV2和ShuffleNet设计,更多地是对其结构参数进行搜索,所以在网络结构有一定的束缚;
参考
FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
仅为学习记录,侵删!















 1625
1625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











