







参考: http://blog.csdn.net/zouxy09/article/details/8781543
网络结构
- CNN是个多层神经网络
- 每层由多个二维平面组成
- 每个平面由多个独立神经元组成
- S: 特征映射层
- C: 特征提取层
- 每层由多个二维平面组成
核心思想
- 局部感受野
- 权值共享
- 时间/空间亚采样
参数减少与特征共享
- CNN的优势
- 通过感受野和权值共享减少了神经网络需要训练的参数个数
- 一般情况
- 1000 * 1000 像素的图像
- 1百万个神经元
- 如果他们全连接, 则需要 1012 10 12 个权值参数
- CNN减少参数的原理
- 图像的空间联系是局部的
- 每个神经元不需要对全局图像做感受
- 每个神经元只需要感受局部的图像区域(感受野) –> 减少参数
- 神经元的个数取决于感受野的大小和重叠情况
- 让每个神经元的参数都相同 –> 再一次减少参数 –> ++但是这样做仅仅是提取了一种特征++
- 用不同的滤波器(卷积核)去卷积图像 –> 得到对图像的不同特征的放映(Feature Map)
- 卷积: 使原信号特征增强, 并且降低噪音
- 举例
- (1000×1000)像素的图像, 感受野(10×10)
- 隐层每个神经元只和这个10×10的局部图像连接
- 一个神经元有一百个参数
- 准确的说是++101个++(要加上偏置, 偏置被同一个滤波器共享)
- 1百万个神经元只有10^6×100 = 10 ^ 8个连接(10^8个参数)
- 权值共享 : 如果每个神经元的100个参数是相同的 –> 一共只有++100个参数++
- 用100个不同的滤波器(卷积核)提取不同的特征 –> 100×100=++10K个参数++
- 图像的空间联系是局部的
典例(LeNet-5)
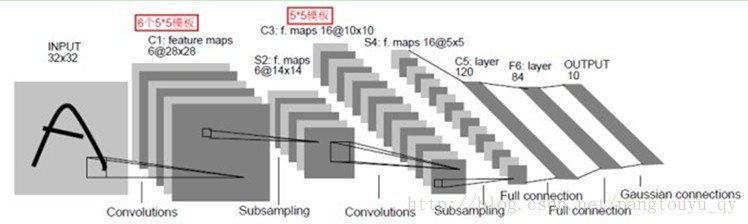
- LeNet-5基本情况
- 输入: 32×32的图像
- 共7层
- 每层有多个Feature Map
- 每个Feature Map有多个神经元
C1: 卷积层
- 6个28×28特征图(Feature Map)
- 因为用了6种不同的卷积核
- 每个神经元与INPUT中的5×5感受野相连
- 156个训练参数
- 156 = (5×5+1)×6
- 122,304个连接
- 122304 = (28×28)×156
S2: 下采样层
- 下采样: 对于一个样值序列间隔几个样值取样一次, 这样得到新序列就是原序列的下采样
- WHY下采样, 利用图像局部相关性的原理
- 减少数据处理量
- 同时保留有用信息
- WHY下采样, 利用图像局部相关性的原理
- 6个14×14特征图(Feature Map)
- 每个单元对应C1中的2×2感受野
- 数据获得方法: 2×2邻域的四个数相加–>乘一个参数–>加偏置–>套sigmoid
- 每个单元对应C1中的2×2感受野
- 12个训练参数
- 12 = 2*6
- 5880个连接
- 功能:
- 模糊滤波器
- 二次特征提取
C3: 卷积层
- 用5×5的卷积核去卷积S2
- 16个10×10特征图
- 因为用了16种不同的卷积核
- 本层的特征图是上一层提取到的特征图的不同组合
- 每个特征图是连接到S2中的所有6个或者几个特征图的
- 一种可能的连接方式
- C3的前6个特征图以S2中3个相邻的特征图子集为输入
- 接下来6个特征图以S2中4个相邻特征图子集为输入
- 接下来6个特征图以S2中4个相邻特征图子集为输入
- 最后一个将S2中所有特征图为输入
- 1516个可训练参数
- 1516 = (3×25+1)×6+(4×25+1)×6+(4×25+1)×3+(6×25+1)×1
S4: 下采样层
- 16个5×5特征图
- 每个单元与C3中相应特征图的2*2感受野相连接
- 32个训练参数
- 32 = 2×16
C5: 卷积层
- 用5×5的卷积核去卷积S4
- 120个1×1特征图 –> 构成了S4和C5之间的全连接
F6
- 84个单元
- 84的选择来自于输出层的设计
- 10164个可训练参数
- 10164 = (120+1)×84
- 功能
- 计算输入向量和权重向量之间的点积
- 加上一个偏置
- 传递给sigmoid函数产生单元i的一个状态
OUTPUT
- 由欧式RBF径向基函数(Euclidean Radial Basis Function)单元组成
- RBF参数向量起着F6层目标向量的角色
- RBF单元计算输入向量和参数向量之间的欧式距离
训练过程
- 概述
- 神经网络用于模式识别的主流是有指导学习网络
- 任一样本的类别是已知
- 要根据同类样本在空间的分布及不同类样本之间的分离程度找一种适当的空间划分方法
- 卷积网络在本质上是一种输入到输出的映射
- 卷积网络执行的是有导师训练
- 样本集是由形如: (输入向量, 理想输出向量)的向量对构成的
- 神经网络用于模式识别的主流是有指导学习网络
主要包括四步
- 第一阶段: 向前传播阶段
- 从样本集中取一个样本(X,Yp), 将X输入网络
- 计算相应的实际输出Op
- Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
- 第二阶段: 向后传播阶段
- 算实际输出Op与相应的理想输出Yp的差
- 按极小化误差的方法反向传播调整权矩阵
CNN的优点
- CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形
- 网络可以并行学习
- 在语音识别和图像处理方面有着独特的优越性
- 权值共享降低了网络的复杂性
- 特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度
- 避免了显式的特征取样, 隐式地从训练数据中进行学习
- 在图像处理方面的优点
- 输入图像和网络的拓扑结构能很好的吻合
- ++特征提取和模式分类同时进行++, 并同时在训练中产生
- 权重共享可以减少网络的训练参数, 使神经网络结构变得更简单, 适应性更强















 3374
3374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









