







 本文介绍了非确定有限状态自动机(NFA)的定义和构建方法,包括其组成元素:有限状态集合、输入符号集合、状态迁移函数、开始状态和接受状态。以实例展示了NFA的状态和符号迁移过程。
本文介绍了非确定有限状态自动机(NFA)的定义和构建方法,包括其组成元素:有限状态集合、输入符号集合、状态迁移函数、开始状态和接受状态。以实例展示了NFA的状态和符号迁移过程。
保留版权,转载需注明出处(http://blog.csdn.net/panjunbiao)。
非确定有限状态自动机(Nondeterministic Finite Automata,NFA)由以下元素组成:
- 一个有限的状态集合S
- 一个输入符号集合Sigma,并且架设空字符epsilon不属于Sigma
- 一个状态迁移函数,对于所给的每一个状态和每一个属于Sigma或{epsilon}的符号,输出迁移状态的集合。
- 一个S中的状态s0作为开始状态(初始状态)
- S的一个子集F,作为接受状态(结束状态)
例如,我们给定:
- S={s0, s1, s2, s3, s4}
- Sigma={a, b}
- 状态迁移函数T,且T(s0, a} = {s1}, T(s1, a) = {s2}, T(s2, b) = {s3}, T(s3, b) = {s4}
- s0为开始状态
- {s4}为接受状态
这样我们就得到一个很简单的NFA,它可以用图来表示,如下图图1:
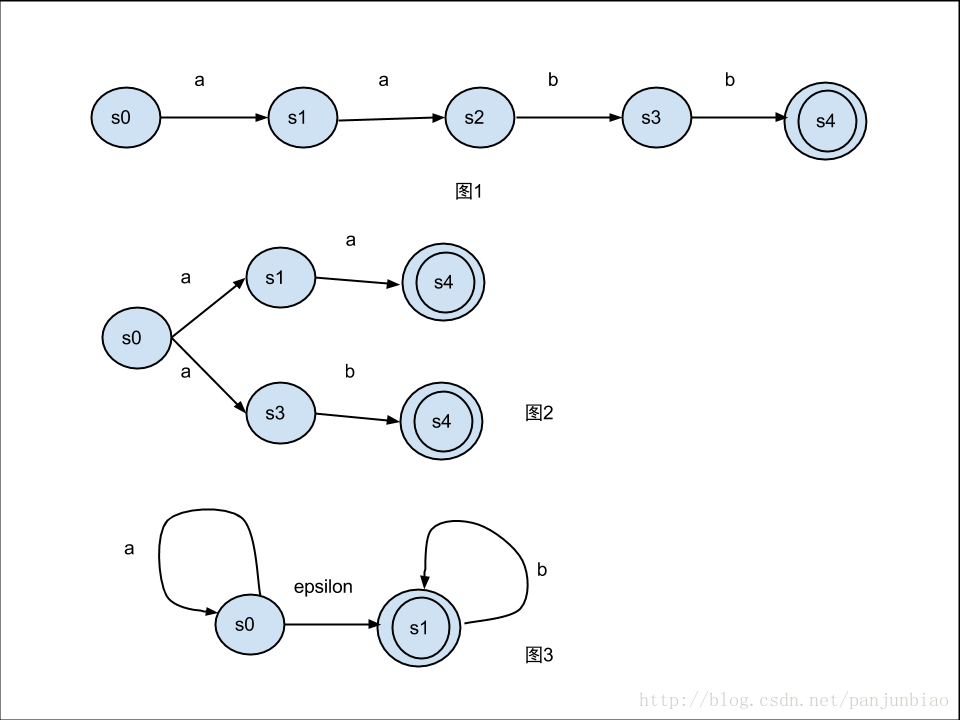
NFA是一个识别器,例如图1所示的NFA,我们从状态s0开始,按顺序输入aabb,在输入第一个符号a之后,状态将从s0迁移到s1,输入第二个符号a之后,状态迁移到s2,输入第三个符号b之后,状态迁移到s3,输入第四个符号b之后,状态迁移到s4,而s4是接收状态,也就是说对我们刚才输入的aabb字符串说yes,表明本NFA识别了所输入的字符串。
所谓非确定,是指在某个状态输入同一个符号,状态可以迁移到不同的下一个状态,例如图2,在s0处输入字符a,状态既可以迁移为s1,也可以迁移为s3,准确的说是状态迁移到了{s1,s3},因此图2所示的NFA能够接受的字符串包括aa和ab。
另外,NFA的特点还在于空符号也能进行状态迁移,例如图3的s0,不需要任何输入字符就可以迁移到s1,因此图3的NFA可以识别的语言为*a*b,即0到任意多个a
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3354
3354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









