






1. 准备工作
a. 下载新的数据集并转化成YOLOv7数据集格式
LabelImg:是一款开源的图像标注工具,标签可用于分类和目标检测,它是用python写的,并使用Qt作为其图形界面,简单好用(虽然是英文版的)。其注释以 PASCAL VOC格式保存为XML文件,这是ImageNet使用的格式。此外,它还支持 COCO数据集格式,目前还不支持YOLO格式。
# cmd下执行,其自动会安装labelimg以及lxml和pyqt5
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
# 结束后,在cmd中输入labelimg,即可开启
labelimg为了快速,下载已标注好的数据集:SafetyHelmet (安全帽佩戴检测)
链接:https://pan.baidu.com/s/1hf9Ot5oFs6JtR6wMli_Kdg
提取码:8ubf
它包括7581张图像,其中9044个人类安全头盔佩戴对象(正样本)和111514个正常头部对象(未佩戴或负样本,一张图像里面可能有多个)。正样本对象来自goolge或baidu,用LabelImg手动标记。一些负面样本来自SCUT-HEAD。修复了原始SCUT-HEAD的一些错误,并使数据可以直接加载为正常的Pascal VOC格式。此外,还提供了一些使用MXNet-GluonCV进行预处理的模型。
原始的Pascal VOC 格式: classes = ['hat',“person”】“hat”表示正样本,“person”表示负样本
---VOC2028
---Annotations
---ImageSets
---JPEGImages
b. 下载YOLOv7并编译
git clone https://github.com/WongKinYiu/yolov7
cd yolov7
pip install -r requirements.txt怎么判断编译成功,检测功能没问题呢?
# 首先下载初始权重,得到两个权重文件。
cd yolov7
mkdir weights
wget https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7_training.pt
# 预测图片,有比较清晰的检测结果
python3 detect.py --weights weights/yolov7.pt --source inference/images
# 参数说明
--weights weight/yolov7.pt # 这个参数是把已经训练好的模型路径传进去,就是刚刚下载的文件
--source inference/images # 传进去要预测的图片c. 转化成yolov7数据集格式 (train:val:test = 8:1:1 )
在yolov7下新建datasets,将数据集放在yolov7/datasets下
cd yolov7
mkdir datasets
cd datasets
unzip VOC2028.zip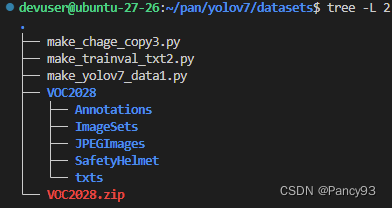
第一步:通过make_yolov7_data1.py将原来的Annotations的*.xml文件转化成 *.txt
import os.path
import xml.etree.ElementTree as ET
class_names = ['SafetyHelmet','person]
xmlpath = '/home/devuser/pan/yolov7/datasets/VOC2028/Annotations/' # 原xml路径
txtpath = '/home/devuser/pan/yolov7/datasets/VOC2028/txts/' # 转换后txt文件存放路径
files = []
if not os.path.exists(txtpath):
os.makedirs(txtpath)
for root, dirs, files in os.walk(xmlpath):
None
number = len(files)
print(number)
i = 0
while i < number:
name = files[i][0:-4]
xml_name = name + ".xml"
txt_name = name + ".txt"
xml_file_name = xmlpath + xml_name
txt_file_name = txtpath + txt_name
xml_file = open(xml_file_name)
tree = ET.parse(xml_file)
root = tree.getroot()
# filename = root.find('name').text
# image_name = root.find('filename').text
w = int(root.find('size').find('width').text)
h = int(root.find('size').find('height').text)
f_txt = open(txt_file_name, 'w+')
content = ""
first = True
for obj in root.iter('object'):
name = obj.find('name').text
# class_num = class_names.index(name)
class_num = 1
xmlbox = obj.find('bndbox')
x1 = int(xmlbox.find('xmin').text)
x2 = int(xmlbox.find('xmax').text)
y1 = int(xmlbox.find('ymin').text)
y2 = int(xmlbox.find('ymax').text)
if first:
content += str(class_num) + " " + \
str((x1 + x2) / 2 / w) + " " + str((y1 + y2) / 2 / h) + " " + \
str((x2 - x1) / w) + " " + str((y2 - y1) / h)
first = False
else:
content += "\n" + \
str(class_num) + " " + \
str((x1 + x2) / 2 / w) + " " + str((y1 + y2) / 2 / h) + " " + \
str((x2 - x1) / w) + " " + str((y2 - y1) / h)
# print(str(i / (number - 1) * 100) + "%\n")
print(content)
f_txt.write(content)
f_txt.close()
xml_file.close()
i += 1第二步:通过make_trainval_txt2.py按照8:1:1划分数据集
import os
import random
random.seed(0)
xmlfilepath='/home/devuser/pan/yolov7/datasets/VOC2028/Annotations/'
saveBasePath='/home/devuser/pan/yolov7/datasets/VOC2028/ImageSets/Main/'
#----------------------------------------------------------------------#
# 想要增加测试集修改trainval_percent
# train_percent不需要修改
#----------------------------------------------------------------------#
trainval_percent = 1
train_percent = 0.8
temp_xml = os.listdir(xmlfilepath)
total_xml = []
for xml in temp_xml:
if xml.endswith(".xml"):
total_xml.append(xml)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
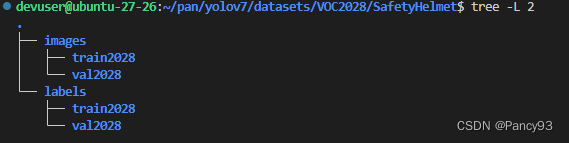
ftest .close()第三步:通过make_chage_copy3.py将按照比例划分好的数据集重新放进images和labels
import os
import shutil
from tqdm import tqdm
SPLIT_PATH ='/home/devuser/pan/yolov7/datasets/VOC2028/ImageSets/Main/'
IMGS_PATH = '/home/devuser/pan/yolov7/datasets/VOC2028/JPEGImages'
TXTS_PATH = '/home/devuser/pan/yolov7/datasets/VOC2028/txts/'
TO_IMGS_PATH ='/home/devuser/pan/yolov7/datasets/VOC2028/SafetyHelmet/images'
TO_TXTS_PATH ='/home/devuser/pan/yolov7/datasets/VOC2028/SafetyHelmet/labels'
data_split = ['train.txt', 'val.txt']
to_split = ['train2028', 'val2028']
for index, split in enumerate(data_split):
split_path = os.path.join(SPLIT_PATH, split)
to_imgs_path = os.path.join(TO_IMGS_PATH, to_split[index])
if not os.path.exists(to_imgs_path):
os.makedirs(to_imgs_path)
to_txts_path = os.path.join(TO_TXTS_PATH, to_split[index])
if not os.path.exists(to_txts_path):
os.makedirs(to_txts_path)
f = open(split_path, 'r')
count = 1
for line in tqdm(f.readlines(), desc="{} is copying".format(to_split[index])):
# 复制图片
src_img_path = os.path.join(IMGS_PATH, line.strip() + '.jpg')
dst_img_path = os.path.join(to_imgs_path, line.strip() + '.jpg')
if os.path.exists(src_img_path):
shutil.copyfile(src_img_path, dst_img_path)
else:
print("error file: {}".format(src_img_path))
# 复制txt标注文件
src_txt_path = os.path.join(TXTS_PATH, line.strip() + '.txt')
dst_txt_path = os.path.join(to_txts_path, line.strip() + '.txt')
if os.path.exists(src_txt_path):
shutil.copyfile(src_txt_path, dst_txt_path)
else:
print("error file: {}".format(src_txt_path)) 2. 修改配置文件
/home/devuser/pan/yolov7/cfg/training/yolov7.yaml
nc: 2 # number of classes/home/devuser/pan/yolov7/data/SafetyHelmet.yaml
# COCO 2017 dataset http://cocodataset.org
# download command/URL (optional)
# download: bash ./scripts/get_coco.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: '/home/devuser/pan/yolov7/datasets/VOC2028/SafetyHelmet/images/train2028' # 118287 images
val: '/home/devuser/pan/yolov7/datasets/VOC2028/SafetyHelmet/images/val2028' # 5000 images
#test: ./coco/test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 2
# class names
names: ['hat','person']3. 下载初始权重,训练模型
训练的初始权重:yolov7_training.pt
python3 train.py --weights weights/yolov7_training.pt --cfg cfg/training/yolov7.yaml --data data/SafetyHelmet.yaml --device 0,1 --batch-size 8 --epoch 50训练文件train.py的入参说明: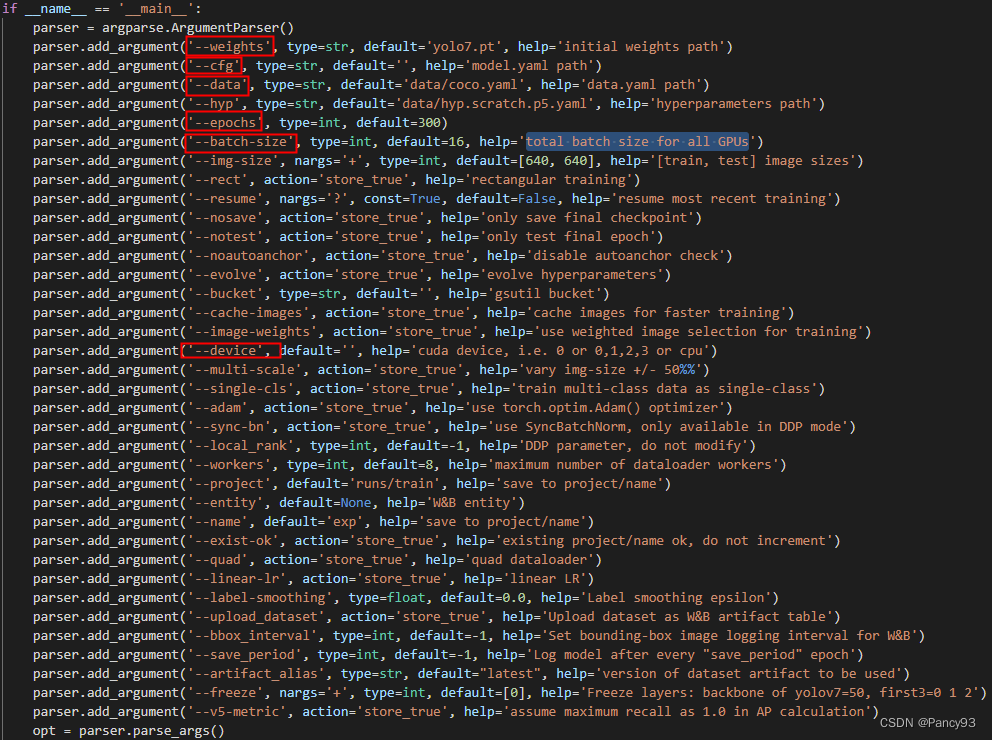
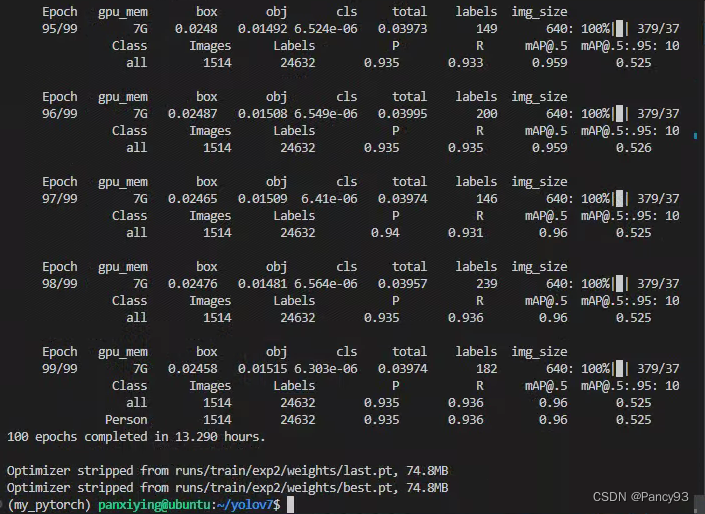
训练结果:
4.测试
python3 detect.py --weights ./runs/train/exp2/weights/best.pt --source ./datasets/VOC2028/SafetyHelmet/images/test2028/测试结果:
| model | classes | P | R | mAP | mAP@.5:.95:10 |
| YOLOv5 | - | - | - | - | - |
| YOLOv7 | 2 |















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









