







目录
Skin Lesion Segmentation Based on Improved U-net
摘要
- 黑色瘤问题背景,表明其亟待解决
- 指明皮肤病变分割是解决该问题的重要步骤
- 指明目前解决方案仍然存在的问题:不同皮肤状态产生的固有的视觉复杂性和模糊性。
- U-Net模型在本问题上有优秀的表现
- 作者基于U-Net做出了改进
- 在ISIC 2017数据集上的训练获得不错的结果
1、引言
- 详细说明了黑色素瘤的危害,以及尽早识别该病症的紧迫性。
- 目前存在的难点:(1)黑色素瘤、痣和脂溢性角化病等不同皮肤疾病之间内在的视觉相似性,即使是皮肤镜专家也很难区分它们。如下图所示
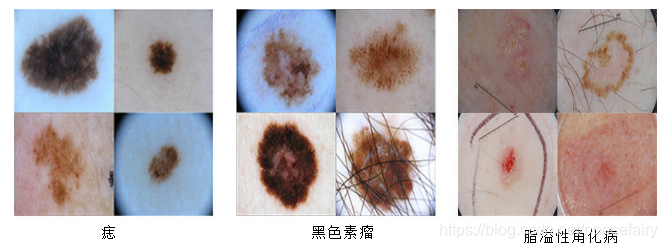
加上(2)世界范围内有经验的皮肤科医生非常有限,不同的皮肤科专家之间的决策存在偏差。 - 由于机器学习的飞速发展,因此,设计自动皮肤镜评估算法,积极协助皮肤科医生,改善上述困难是可能的,也是有意义的。
黑色素瘤检测的一般流程包括预处理、分割、特征提取和分类。皮肤病变分割是最基本也是最重要的一步,对后续的分类任务有很大的帮助。本文将重点研究基于皮肤镜图像的皮肤病变分割任务。
- 针对该问题所提出的解决方法大致分为两类传统和深度学习方法
-
传统的学习方法基于浅层学习模型,可以通过无监督或有监督的方式学习,而深度学习方法基于DCNN(深卷积神经网络)模型,可以通过端到端的体系结构以有监督的方式学习。
文中列举了传统学习的方法的论文和相关方法,并指出了传统学习方法的局限性。
传统方法通常涉及复杂的步骤,其性能高度依赖于预处理和后处理步骤。
由于上述缺点,在皮肤状况复杂、图像不理想的情况下(如上所述的情况)分割结果差。
深度学习方法
目前大都基于FCN和U-Net。参考文献[9]提出基于FCN的分割方法,参考文献[10]利用了反卷积,同时用Jaccard Loss 代替交叉熵损失函数。参考文献[11,12]基于U-Net进行优化。
该问题的难点:复杂的皮肤状况和模糊的边界。
本文提出的方法,基于U-Net进行改进,主要添加了Batch Normalization 和空洞卷积。除此之外,还利用集成技术,现有的集成技术通常使用不同的参数训练多个模型,相比之下,我们的方法不需要训练额外的模型,效率会稍高一些。
2、提出的方法
提出方案流程图,一共分为三个模块。

2.1 预处理模块
- 将所有的图像先放大,之后统一处理为256x256的尺寸(由于原数据分辨率过大,为提高处理效率)
- 将图像的RGB和HSV空间作为输入
- 通过除以每个颜色通道的最大强度值,将所有输入通道规格化到范围[0,1]。
2.2 基于DCNN的分割
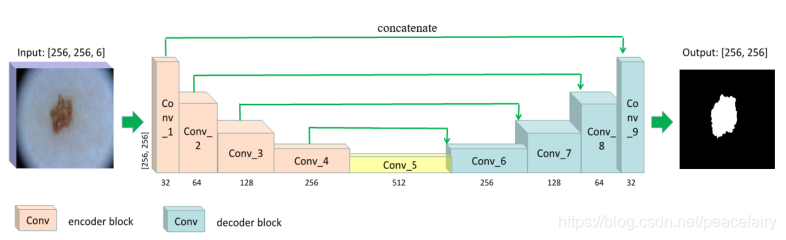
输入是6个通道(RGB+HSV)的图像
编码器阶段采用的CONV块:Conv、BN、Conv、BN、Expanded Conv和Max Pool
解码器阶段采用的CONV块:up sampling, concatenate, conv, BN, conv, BN and
dilated conv.
图中黄色块Conv_5连接层:conv, BN, conv, BN and dilated conv
最终输出是概率图,每个元素表示像素属于**感兴趣区域(**黑色素瘤、痣或脂溢性角化病)的概率。
2.3 集成技术
为了提高分割性能,已有的许多工作都是通过集成不同的训练模型来得到最终的分割结果。最终的概率图是使用不同学习模型生成的概率图的平均值。
然而,训练不同的模型,特别是DCNN模型可能非常耗时。
本文集成技术的思路,利用在测试数据集上的数据增强来实现集成技术。具体做法是首先对给定的测试图像旋转90°,180°,270°再进行垂直和水平的翻转。得到这些增广数据的预测掩码后,借助这些增广数据的预测掩码进行反向操作(reverse operation)重建原始图像的预测mask。最终的预测mask取这些重建预测mask的平均值。
待解决的问题,这个反向操作(reverse operation)是什么意思?
我理解的是反向进行垂直和水平的翻转,之后再反向旋转90°,180°和270°。
2.4 图像增广(数据增强)
深度学习模型的成功实施需要大量的训练数据。本文采用数据增强的方法,将训练样本的数量从2,000幅增加到48000幅。由于皮肤病变的感兴趣区域通常集中在图像中,与皮肤区域相比通常占据较小的面积,因此我们使用了3种不同尺度的图像。3个缩放图像包括原始图像和裁剪后的居中图像,其大小分别为原始大小的80%和70%。然后,对于每个尺度的图像,我们将图像随机旋转90度、180度、270度,或者随机翻转图像。
此外,我们还采用 rigid 移动最小二乘法[15]来生成变形图像。生成的图像与原始图像相比,属于轻微的视觉差异图像,可以模仿真实的图像,适用于医学图像分割任务。然后将这些图像全部归一化为256×256的相同大小。
3、实验和结果
3.1 数据集
数据集采用的的ISIC 2017 在该数据集中还可以看到光照变化、噪声和各种伪影。
3.2 实现
深度学习框架采用的是tensorflow+keras+Intel® i7-7700 4.2 GHz CPU+GPU of Nvidia GeForce GTX 1080Ti 11GB+采用Adam优化器+初始学习率设置为0.0001+损失函数采用交叉损失函数+epochs设置为3,batch_size设置为16,iteration = 48000/16 = 3000
3.3 评价准则
JA,DC,ACC,SE,SP
3.4 结果与分析
比较模型:U-Net,SegNet 为了进行公平的比较,这些神经网络的输入是相同的。实验结果见表。
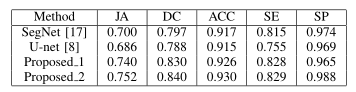
其中Proposed_1,Proposed_2分别代表没有使用测试集成技术和使用测试集成技术。
4、结论和将来的工作
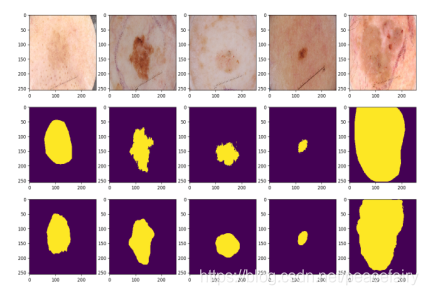
该模型存在的问题:该模型学习到将暗区域作为感兴趣的区域,在感兴趣区域比周围皮肤区域亮的少数情况下该模型的分割性能不好。作者指出这是类别不均衡导致的。希望后续的工作能够解决该问题。
不好的分割结果如下图所示:

















 1592
1592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









