









1.聚类的定义
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
聚类和分类的区别
聚类(Clustering):是指把相似的数据划分到一起,具体划分的时候并不关心这一类的标签,目标就是把相似的数据聚合到一起,聚类是一种无监督学习(Unsupervised Learning)方法。分类(Classification):是把不同的数据划分开,其过程是通过训练数据集获得一个分类器,再通过分类器去预测未知数据,分类是一种监督学习(Supervised Learning)方法。
2.聚类的方法以及原理
数据聚类方法主要可以分为划分式聚类方法(Partition-based Methods)、基于密度的聚类方法(Density-based methods)、层次化聚类方法(Hierarchical Methods)等
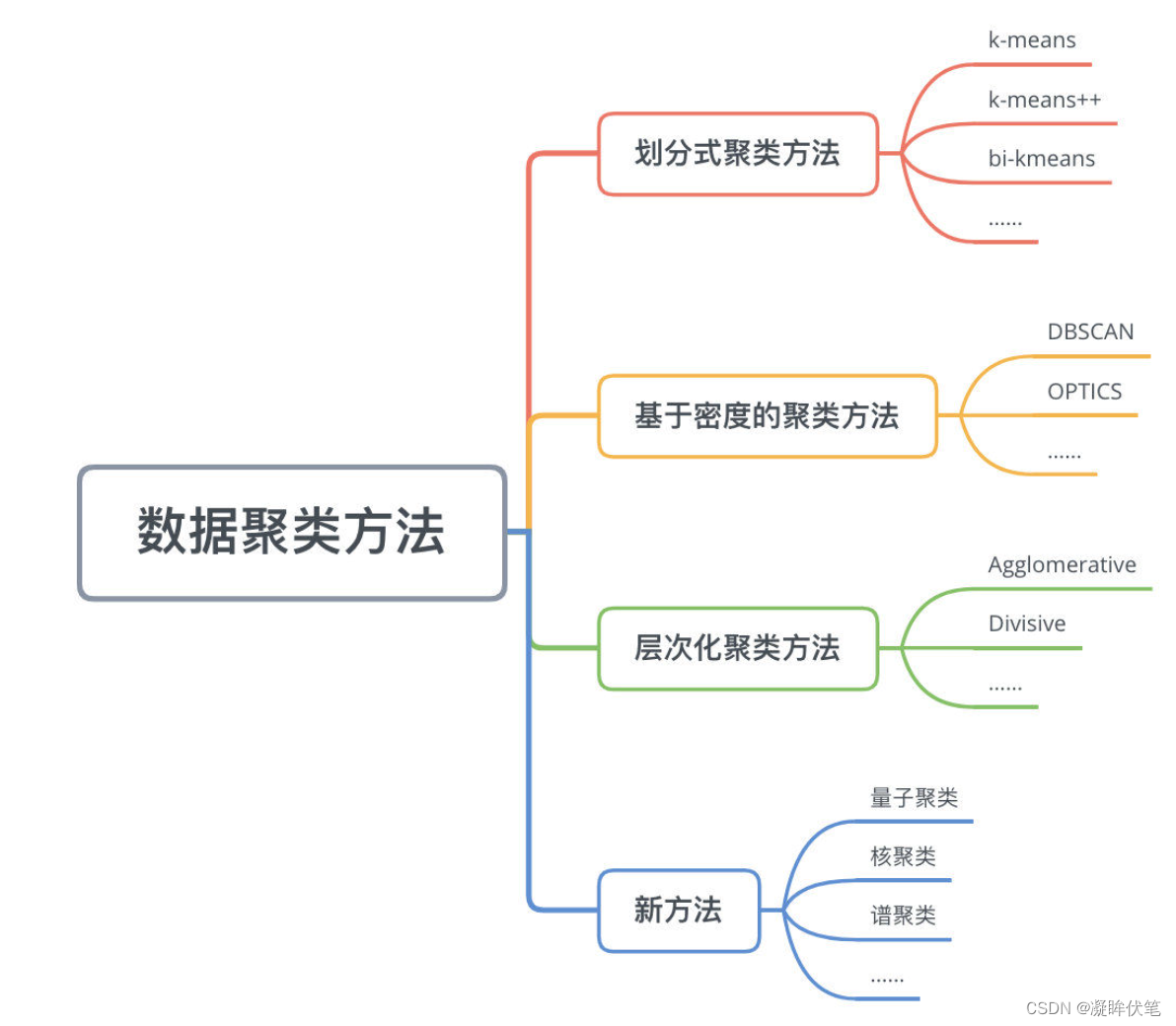
划分式聚类方法
划分式聚类方法需要事先指定簇类的数目或者聚类中心,通过反复迭代,直至最后达到"簇内的点足够近,簇间的点足够远"的目标。经典的划分式聚类方法有k-means及其变体k-means++、bi-kmeans、kernel k-means等。
经典k-means源代码,下左图是原始数据集,通过观察发现大致可以分为4类,所以取k=4,测试数据效果如下右图所示。
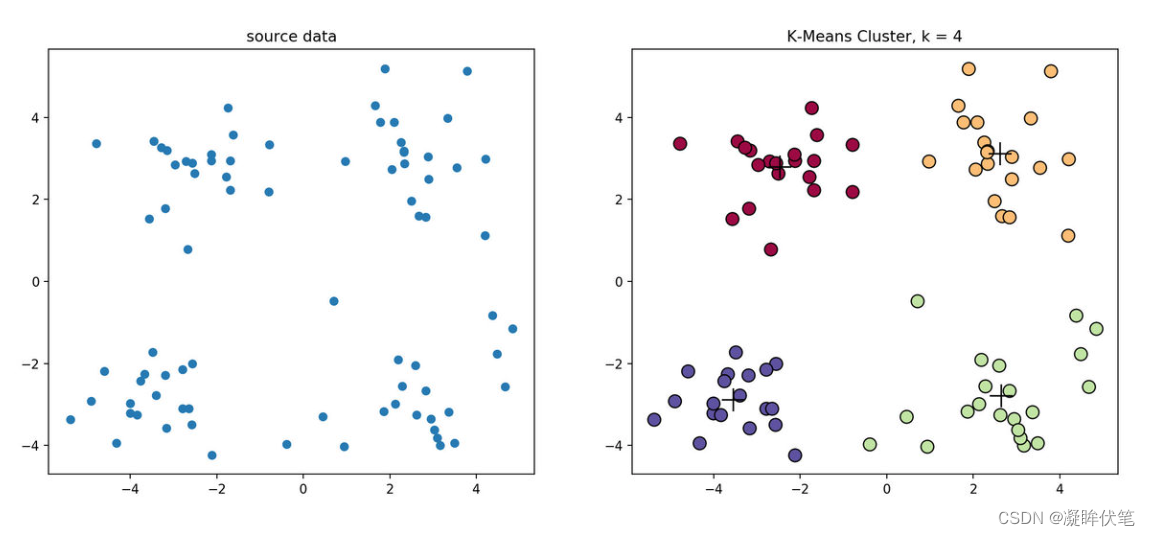
KMeans聚类
主要思想:
聚类算法要把M个数据点按照分布分成K类(很多算法的K是人为提前设定的)。我们希望通过聚类算法得到 K个中心点,以及每个数据点属于哪个中心点的划分。
• 中心点可以通过迭代算法来找到,满足条件:所有的数据点到聚类中心的距离【L2距离】之和是最小的。
• 中心点确定后,每个数据点属于离它最近的中心点。
如何寻找中心点?
采用 EM算法 迭代确定中心点。流程分两步:
• ① 更新中心点:初始化的时候以随机取点作为起始点;迭代过程中,取同一类的所有数据点的重心(或质心)作为新中心点。
• ② 分配数据点:把所有的数据点分配到离它最近的中心点。
重复上面的两个步骤,一直到中心点不再改变为止。
优点:
简单易用
缺点:
1:中心点是所有同一类数据点的质心,所以聚类中心点可能不属于数据集的样本点。
2:计算距离时我们用的是L2距离的平方。对离群点很敏感,噪声(Noisy Data)和离群点(Outlier)会把中心点拉偏,甚至改变分割线的位置。
3:对初始化敏感,初始化点是随机点
demo:
from sklearn.cluster import KMeans
kmeans = KMeans(n_cluster=3, random_state=0, n_init=100).fit(df)
print(kmeans.labels_)
print(kmeans.cluster_centers_)
K-Mediods聚类
主要思想:
K-Mediods算法与K-Means最大的区别就是:K-Means是寻找簇中的平均值作为质心。而K-Mediods在寻找到平均值之后,会选一个离这个均值最近的实际点作为质心。也就是常说K-Mediods会以数据集中真正存在的最优点来作为它的质心
适用场景:
K-medoids方法不太受孤立点的影响,但是其计算代价又很大
优点:
1.实际点作为质心
2.为避免平方计算对离群点的敏感,把平方变成绝对值。
缺点:
1.对初始化敏感,初始化点是任意选择数据集中的点。
2.复杂度方面,相比于 K-Means 的O(n) ,K-Medoids 更新中心点的复杂度O(n^2) 要更高一些。
基于密度的方法
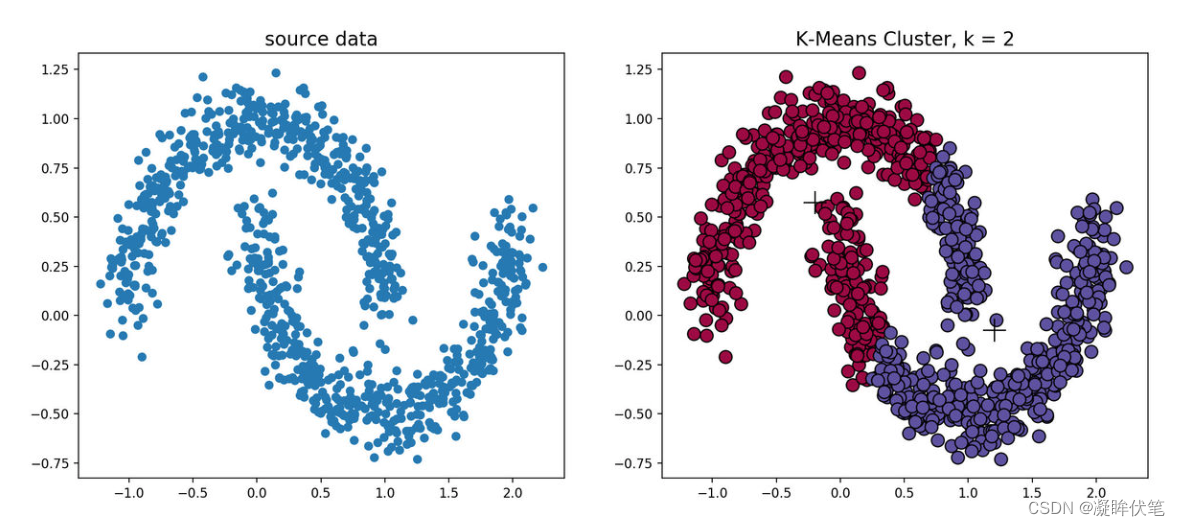
k-means算法对于凸性数据具有良好的效果,能够根据距离来讲数据分为球状类的簇,但对于非凸形状的数据点,就无能为力了,当k-means算法在环形数据的聚类时,我们看看会发生什么情况。
均值漂移聚类
主要思想:
均值漂移聚类是基于滑动窗口的算法,来找到数据点的密集区域。这是一个基于质心的算法,通过将中心点的候选点更新为滑动窗口内点的均值来完成,来定位每个组/类的中心点。然后对这些候选窗口进行相似窗口进行去除,最终形成中心点集及相应的分组。
1. 确定滑动窗口半径r,以随机选取的中心点C半径为r的圆形滑动窗口开始滑动。均值漂移类似一种爬山算法,在每一次迭代中向密度更高的区域移动,直到收敛。
2. 每一次滑动到新的区域,计算滑动窗口内的均值来作为中心点,滑动窗口内的点的数量为窗口内的密度。在每一次移动中,窗口会想密度更高的区域移动。
3. 移动窗口,计算窗口内的中心点以及窗口内的密度,知道没有方向在窗口内可以容纳更多的点,即一直移动到圆内密度不再增加为止。
4. 步骤一到三会产生很多个滑动窗口,当多个滑动窗口重叠时,保留包含最多点的窗口,然后根据数据点所在的滑动窗口进行聚类。
优点:
1.不同于K-Means算法,均值漂移聚类算法不需要我们知道有多少类/组
2.基于密度的算法相比于K-Means受均值影响较小
缺点:
窗口半径r的选择可能是不重要的(个人理解,因为当有多个滑动窗口重叠时,保留包含最多点的窗口,所以说你半径大小好像不是那么重要)
demo:
import sklearn.cluster as sc
bw = sc.estimate_bandwidth(df, n_sample=len(df), quantile=0.2)
model = sc.MeanShift(bandwidth=bw).fit(df)
基于密度的聚类方法(DBSCAN)
基于密度的聚类方法可以在有噪音的数据中发现各种形状和各种大小的簇。其核心思想就是先发现密度较高的点,然后把相近的高密度点逐步都连成一片,进而生成各种簇。算法实现上就是,对每个数据点为圆心,以eps为半径画个圈(称为邻域eps-neigbourhood),然后数有多少个点在这个圈内,这个数就是该点密度值
主要思想:
与均值漂移聚类类似,DBSCAN也是基于密度的聚类算法。
1. 首先确定半径r和minPoints. 从一个没有被访问过的任意数据点开始,以这个点为中心,r为半径的圆内包含的点的数量是否大于或等于minPoints,如果大于或等于minPoints则改点被标记为central point,反之则会被标记为noise point。
2. 重复1的步骤,如果一个noise point存在于某个central point为半径的圆内,则这个点被标记为边缘点,反之仍为noise point。重复步骤1,知道所有的点都被访问过。
适用场景:
优点:不需要知道簇的数量
缺点:需要确定距离r和minPoints
DBSCAN 缺点:
1、对两个参数的设置敏感,即圈的半径 eps 、阈值 MinPts。
2、DBSCAN 使用固定的参数识别聚类。显然,当聚类的稀疏程度不同,聚类效果也有很大不同。即数据密度不均匀时,很难使用该算法
3、如果数据样本集越大,收敛时间越长。此时可以使用 KD 树优化
层次化聚类方法
前面介绍的几种算法确实可以在较小的复杂度内获取较好的结果,但是这几种算法却存在一个链式效应的现象,比如:A与B相似,B与C相似,那么在聚类的时候便会将A、B、C聚合到一起,但是如果A与C不相似,就会造成聚类误差,严重的时候这个误差可以一直传递下去。为了降低链式效应,这时候层次聚类就该发挥作用了。
层次聚类算法 (hierarchical clustering) 将数据集划分为一层一层的 clusters,后面一层生成的 clusters 基于前面一层的结果。层次聚类算法一般分为两类:
- Agglomerative 层次聚类:又称自底向上(bottom-up)的层次聚类,每一个对象最开始都是一个
cluster,每次按一定的准则将最相近的两个cluster合并生成一个新的cluster,如此往复,直至最终所有的对象都属于一个cluster。这里主要关注此类算法。 - Divisive 层次聚类: 又称自顶向下(top-down)的层次聚类,最开始所有的对象均属于一个
cluster,每次按一定的准则将某个cluster划分为多个cluster,如此往复,直至每个对象均是一个cluster。
BIRCH
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),它是用层次方法来聚类和规约数据
BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个树结构称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。从右图中我们可以看看聚类特征树的样子:每个节点包括叶子节点都有若干个CF,而内部节点的CF有指向孩子节点的指针,所有的叶子节点用一个双向链表链接起来。
将所有的训练集样本建立了CF Tree,一个基本的BIRCH算法就完成了,对应的输出就是若干个CF节点,每个节点里的样本点就是一个聚类的簇。也就是说BIRCH算法的主要过程,就是建立CF Tree的过程。
Birch聚类算法优缺点
优点:
(1)节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
(2)聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
(3)可以识别噪音点,还可以对数据集进行初步分类的预处理。
缺点:
(1)由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同。
(2)对高维特征的数据聚类效果不好。此时可以选择Mini Batch K-Means。
(3)如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
凝聚层次聚类
主要思想:
层次聚类算法分为两类:自上而下和自下而上。凝聚层级聚类(HAC)是自下而上的一种聚类算法。HAC首先将每个数据点视为一个单一的簇,然后计算所有簇之间的距离来合并簇,直到所有的簇聚合成为一个簇为止
具体步骤:
1. 首先我们将每个数据点视为一个单一的簇,然后选择一个测量两个簇之间距离的度量标准。例如我们使用average linkage作为标准,它将两个簇之间的距离定义为第一个簇中的数据点与第二个簇中的数据点之间的平均距离。
2. 在每次迭代中,我们将两个具有最小average linkage的簇合并成为一个簇。
3. 重复步骤2知道所有的数据点合并成一个簇,然后选择我们需要多少个簇。
适用场景:
优点:
1.不需要知道有多少个簇
2.对于距离度量标准的选择并不敏感
缺点:
效率低
其他聚类方法
用高斯混合模型(GMM)的最大期望(EM)聚类
可以看做是k-means模型的一个优化
高斯混合模型(GMM)做聚类首先假设数据点是呈高斯分布的,相对应K-Means假设数据点是圆形的,高斯分布(椭圆形)给出了更多的可能性。我们有两个参数来描述簇的形状:均值和标准差。所以这些簇可以采取任何形状的椭圆形,因为在x,y方向上都有标准差。因此,每个高斯分布被分配给单个簇。
所以要做聚类首先应该找到数据集的均值和标准差,我们将采用一个叫做最大期望(EM)的优化算法。下图演示了使用GMMs进行最大期望的聚类过程。
具体步骤:
1. 选择簇的数量(与K-Means类似)并随机初始化每个簇的高斯分布参数(均值和方差)。也可以先观察数据给出一个相对精确的均值和方差。
2. 给定每个簇的高斯分布,计算每个数据点属于每个簇的概率。一个点越靠近高斯分布的中心就越可能属于该簇。
3. 基于这些概率我们计算高斯分布参数使得数据点的概率最大化,可以使用数据点概率的加权来计算这些新的参数,权重就是数据点属于该簇的概率。
4. 重复迭代2和3直到在迭代中的变化不大
图团体检测(Graph Community Detection)
主要思想:
当我们的数据可以被表示为网络或图,可以使用图团体检测方法完成聚类。在这个算法中图团体(graph community)通常被定义为一种顶点(vertice)的子集,其中的顶点相对于网络的其他部分要连接的更加紧密。下图展示了一个简单的图,展示了最近浏览过的8个网站,根据他们的维基百科页面中的链接进行了连接。
具体步骤:
1. 首先初始分配每个顶点到其自己的团体,然后计算整个网络的模块性 M。
2. 第 1 步要求每个团体对(community pair)至少被一条单边链接,如果有两个团体融合到了一起,该算法就计算由此造成的模块性改变 ΔM。
3. 第 2 步是取 ΔM 出现了最大增长的团体对,然后融合。然后为这个聚类计算新的模块性 M,并记录下来。
4. 重复第 1 步和 第 2 步——每一次都融合团体对,这样最后得到 ΔM 的最大增益,然后记录新的聚类模式及其相应的模块性分数 M。
5. 重复第 1 步和 第 2 步——每一次都融合团体对,这样最后得到 ΔM 的最大增益,然后记录新的聚类模式及其相应的模块性分数 M。
SpectralClustering
主要思想:
谱聚类是从图论中演化出来的算法,后来在聚类中得到了广泛的应用。它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
先根据样本点计算相似度矩阵,然后计算度矩阵和拉普拉斯矩阵,接着计算拉普拉斯矩阵前k个特征值对应的特征向量,最后将这k个特征值对应的特征向量组成n*K的矩阵U,U的每一行成为一个新生成的样本点,对这些新生成的样本点进行k-means聚类,聚成k类,最后输出聚类的结果。这就是谱聚类算法的基本思想
适用场景:
优点:
缺点:
谱聚类算法是一个使用起来简单,但是讲清楚却不是那么容易的算法,它需要你有一定的数学基础。如果你掌握了谱聚类,相信你会对矩阵分析,图论有更深入的理解。同时对降维里的主成分分析也会加深理解。
下面总结下谱聚类算法的优缺点。
谱聚类算法的主要优点有:
1)谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到
2)由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
3)当聚类的类别个数较小的时候,谱聚类的效果会很好,但是当聚类的类别个数较大的时候,则不建议使用谱聚类;
4)谱聚类算法建立在谱图理论基础上,与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解
谱聚类算法的主要缺点有:
1)如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
2) 聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
3)谱聚类适用于均衡分类问题,即各簇之间点的个数相差不大,对于簇之间点个数相差悬殊的聚类问题,谱聚类则不适用;
3.聚类的一般过程
- 数据准备:特征标准化和降维
- 特征选择:从最初的特征中选择最有效的特征,并将其存储在向量中
- 特征提取:通过对选择的特征进行转换形成新的突出特征
- 聚类:基于某种距离函数进行相似度度量,获取簇
- 聚类结果评估:分析聚类结果,如
距离误差和(SSE)等
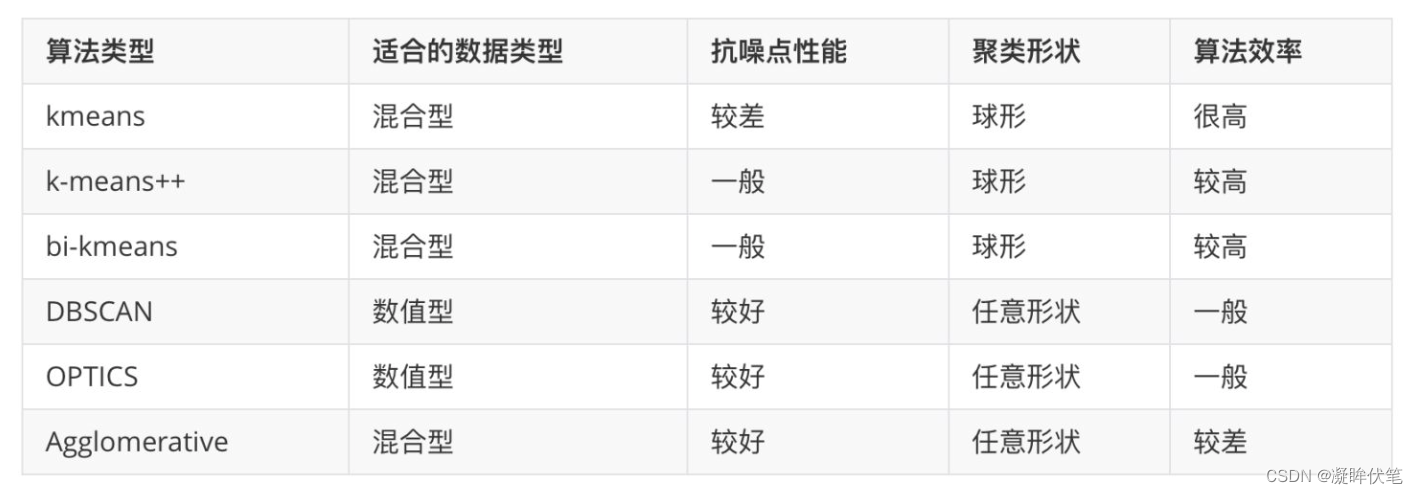
聚类方法比较:
总结:
1.从以上对传统的聚类分析方法所做的总结来看,不管是k-means方法,还是CURE方法,在进行聚类之前都需要用户事先确定要得到的聚类的数目。然而在现实数据中,聚类的数目是未知的,通常要经过不断的实验来获得合适的聚类数目,得到较好的聚类结果。
2.传统的聚类方法一般都是适合于某种情况的聚类,没有一种方法能够满足各种情况下的聚类
3.提出了一种基于最小生成树的聚类算法,该算法通 过逐渐丢弃最长的边来实现聚类结果,当某条边的长度超过了某个阈值,那么更长边就不需要计算而直接丢弃,这样就极大地提高了计算效率,降低了计算成本。
4.处理大规模数据和高维数据的能力有待于提高。目前许多聚类方法处理小规模数据和低维数据时性能比较好,但是当数据规模增大,维度升高时,性能就会急剧下 降,比如k-medoids方法处理小规模数据时性能很好,但是随着数据量增多,效率就逐渐下降,而现实生活中的数据大部分又都属于规模比较大、维度比较 高的数据集。有文献提出了一种在高维空间挖掘映射聚类的方法PCKA(Projected Clustering based on the K-Means Algorithm),它从多个维度中选择属性相关的维度,去除不相关的维度,沿着相关维度进行聚类,以此对高维数据进行聚类。
5.目前的许多算法都只是理论上的,经常处于某种假设之下,比如聚类能很好的被分离,没有突出的孤立点等,但是现实数据通常是很复杂的,噪声很大,因此如何有效的消除噪声的影响,提高处理现实数据的能力还有待进一步的提高。
参考文档:
3.https://blog.csdn.net/m0_37758063/article/details/124115568
4.https://www.cnblogs.com/pinard/p/6221564.html
5.https://www.showmeai.tech/article-detail/197
6.https://www.cnblogs.com/cy0628/articles/13914934.html
7.https://yey.world/2019/11/23/COMP90051-18/

















 2895
2895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









