







上一篇讲了transformer的原理,接下来,看看它的衍生物们。
Transformer基本架构
Transformer模型主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责处理输入序列,将其转换为一系列内部表示;解码器则根据这些内部表示生成输出序列。编码器和解码器都由多个相同的层堆叠而成,每层包括自注意力机制和全连接前馈网络两个子层,子层之间采用残差连接和层归一化技术。
自注意力机制是Transformer的核心所在,它通过计算输入序列中每个位置上的向量表示之间的相似度,为每个位置生成一个权重向量。这样,模型就能够在处理每个位置上的向量时,考虑到其他所有位置上的信息,从而实现对全局信息的捕捉。全连接前馈网络则负责进一步处理自注意力机制的输出,提取更高级的特征表示。
随着研究的深入,Transformer模型也涌现出了许多变种。这些变种模型在保持基本架构不变的基础上,对某些组件进行了改进或添加新的组件,以提高模型的性能或适应不同的任务需求。
1.bert(Bidirectional Encoder Representations from Transformers)
前面有一些bert原理相关的博客,这里主要讲下主要区别,不对原理深究。
BERT是Transformer的一个重要变种,它采用全连接的双向Transformer编码器结构,通过预训练的方式学习通用的语言表示。BERT在预训练时采用了两种任务:遮盖语言建模(Masked Language Modeling)和下一句预测(Next Sentence Prediction)。这两种任务使得BERT能够捕获到丰富的上下文信息,从而在下游任务中取得良好的表现。
BERT的双向表示前,先回顾一下常见的双向表示
网络结构的双向:首先区别于biLSTM那种双向, 那种是在网络结构上的双层
例如 biLSTM来进行一个单词的双向上下文表示
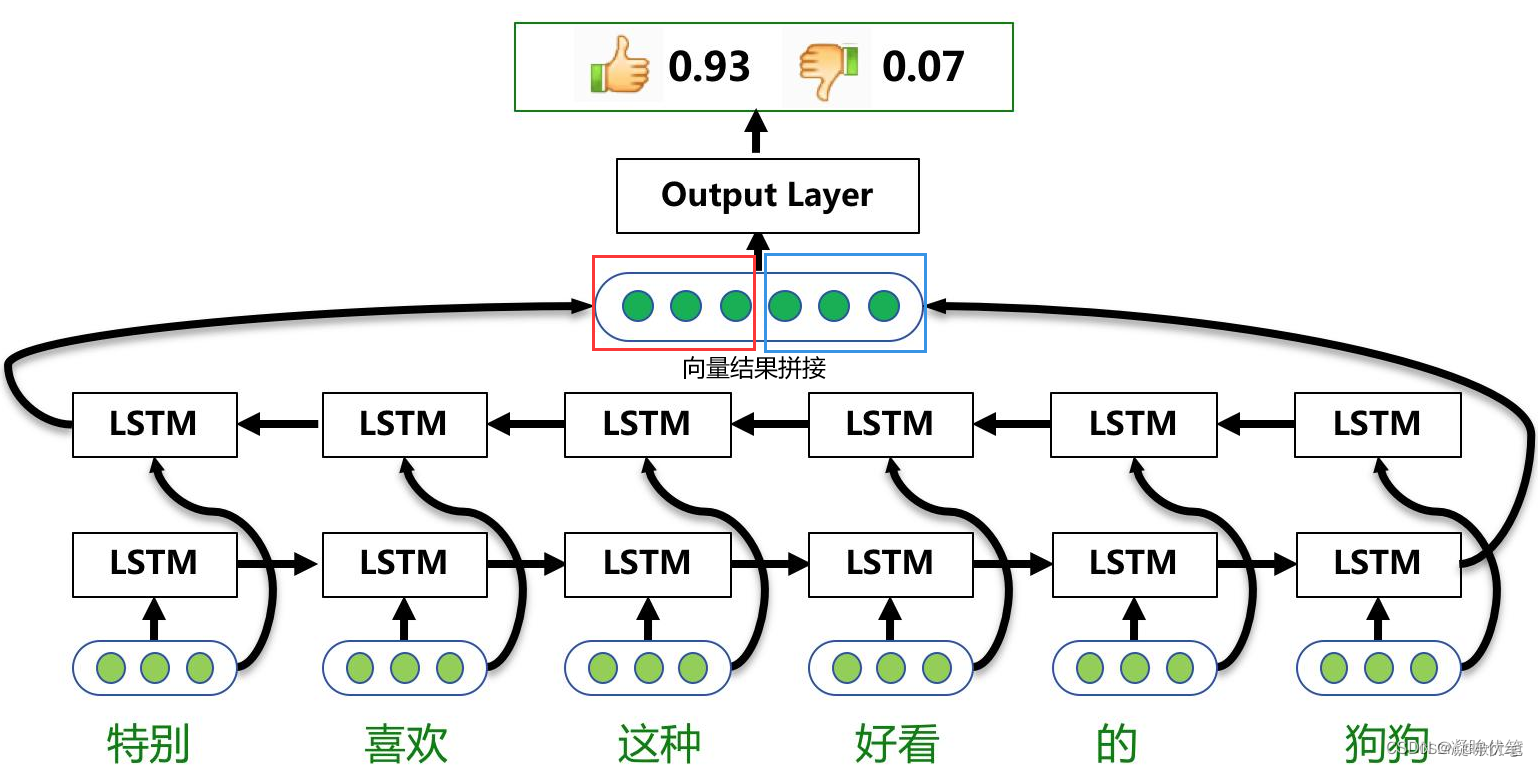
如图所示:单层的BiLSTM是由两个LSTM组合而成,一个是正向去处理输入序列;另一个反向处理序列,处理完成后将两个LSTM的输出拼接起来。在上图中,只有所有的时间步计算完成后,才能得到最终的BiLSTM的输出结果。正向的LSTM经过6个时间步得到一个结果向量;反向的LSTM同样经过6个时间步后得到另一个结果,将这两个结果向量拼接起来,得到最终的BiLSTM输出结果。
请注意,BERT并没有说讲一个序列反向输入到网络中,所以BERT并不属于这种。
用Bi-RNN或Bi-LSTM来“同时从左到右、从右到左扫描序列数据”。Bi-RNN是一种双向语言模型,刻画了正反两个方向上,序列数据中的时空依赖信息。双向语言模型,相比RNN等单向模型,可以提取更多的信息,模型潜力也更大。
Transformer也可以用来构建双向语言模型。最粗暴的方式,就是Bi-Transformer,即让2个Transformer分别从左到右和从右到左扫描输入序列。当然,这样做的话,模型参数太多,训练和推断阶段耗时会比较大。
BERT没有在Transformer的结构上费工夫,而是采用特别的训练策略,迫使模型像双向模型一样思考。这种训练策略就是随机遮蔽词语预测。BERT会对一个句子的token序列的一部分(15%)进行处理:(1)以80%的概率遮蔽掉;(2)以10%的概率替换为其他任意一个token;(3)以10%的概率保持。
预训练任务是一个mask LM ,通过随机的把句子中的单词替换成mask标签, 然后对单词进行预测。
这里注意到,对于模型,输入的是一个被挖了空的句子, 而由于Transformer的特性,通过上下文来分析句子,类似完型填空, 它是会注意到所有的单词的,这就导致模型会根据挖空的上下文来进行预测, 这就实现了双向表示, 说明BERT是一个双向的语言模型。
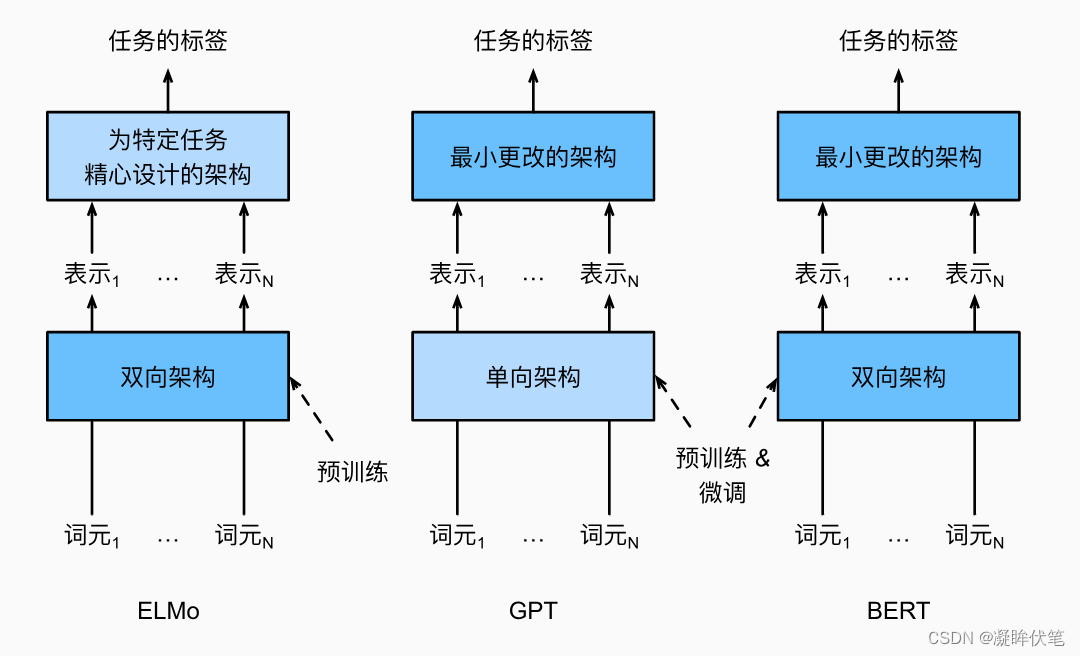
如我们所见,ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT(来自Transformers的双向编码器表示)结合了这两个方面的优点。它对上下文进行双向编码,并且对于大多数的自然语言处理任务 (Devlin et al., 2018)只需要最少的架构改变。通过使用预训练的Transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。 描述了ELMo、GPT和BERT之间的差异。
2.gpt
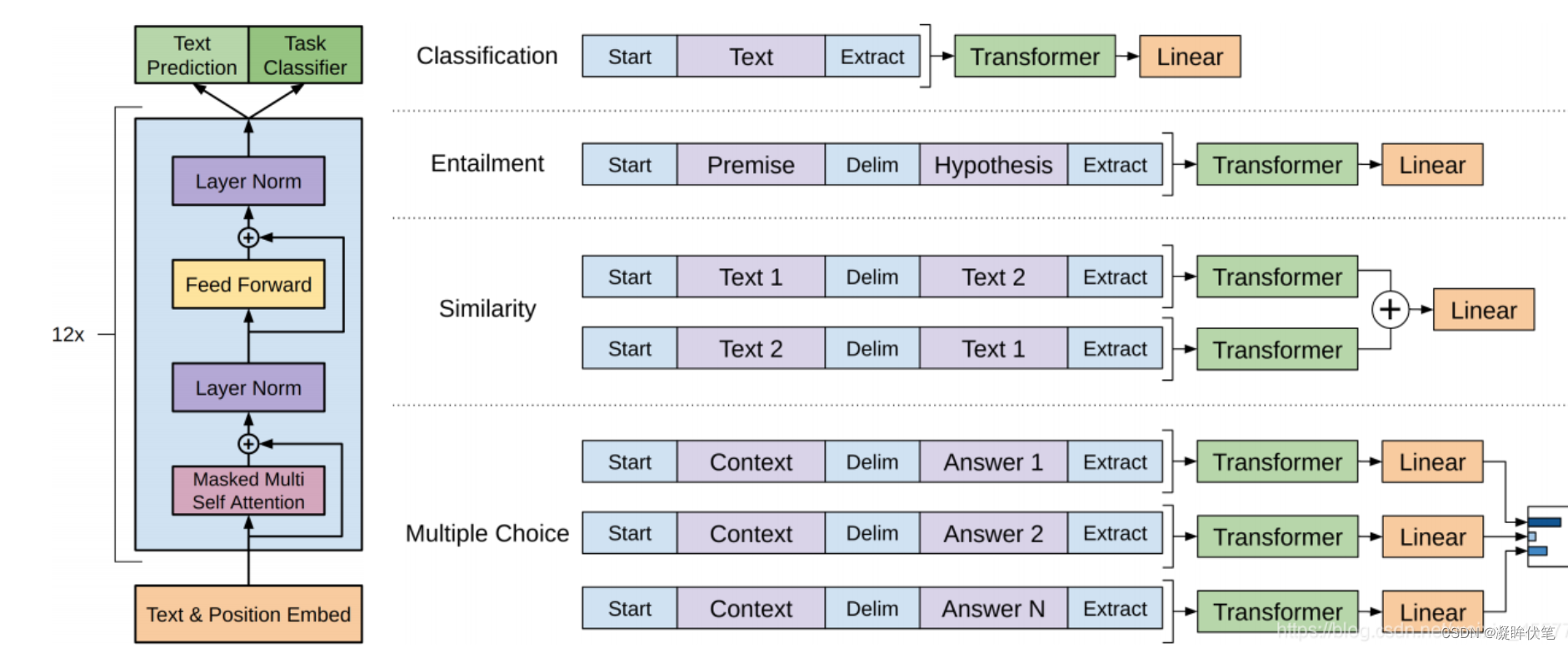
GPT(Generative Pre Training,生成式预训练)模型为上下文的敏感表示设计了通用的任务无关模型 (Radford et al., 2018)。GPT建立在Transformer解码器的基础上,预训练了一个用于表示文本序列的语言模型。当将GPT应用于下游任务时,语言模型的输出将被送到一个附加的线性输出层,以预测任务的标签。与ELMo冻结预训练模型的参数不同,GPT在下游任务的监督学习过程中对预训练Transformer解码器中的所有参数进行微调。GPT在自然语言推断、问答、句子相似性和分类等12项任务上进行了评估,并在对模型架构进行最小更改的情况下改善了其中9项任务的最新水平。
然而,由于语言模型的自回归特性,GPT只能向前看(从左到右)这是将masked self-attention的原因,每个位置的词都看不到后面的词。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
3.Transformer-XL
Transformer-XL旨在解决Transformer在处理长序列时遇到的问题。它通过引入分段循环机制和相对位置编码,使得Transformer能够处理更长的序列。此外,Transformer-XL还采用了分段注意力机制,以减少计算量和内存消耗。
4.gpt2
"GPT"和"GPT-2"都是由OpenAI开发的自然语言处理模型,基于一种被称为"transformer"的架构。下面是它们的主要区别:
在模型结构上,调整了每个block Layer Normalization的位置。将layer normalization放到每个sub-block之前,并在最后一个块后再增加一个layer normalization
模型大小:GPT-2模型比GPT更大。GPT的参数数量是1.17亿,而GPT-2的参数数量大约为15亿。这意味着GPT-2在模型大小和理解能力上都超过了GPT。transformer堆叠增加到48层,隐层维度1600
训练数据:尽管两个模型都是在互联网文本上进行训练的,但GPT-2使用了更多的训练数据,因此它对更多的主题和上下文具有更深的理解。800w文本,40gwebtext数据。
性能和生成能力:由于模型大小和训练数据的增加,GPT-2在许多自然语言处理任务上的性能都超过了GPT。GPT-2在生成连贯、逼真的文本方面也有很大的改进。
未监督学习:GPT-2是完全通过未监督学习训练的,这意味着它没有使用人工标记的数据。这与GPT的训练方法相同,但由于其更大的模型大小和更多的训练数据,GPT-2在未监督学习的效果上更加出色。
引发的关注:由于GPT-2的强大能力,它引发了人们对AI生成假新闻和虚假信息的担忧。这导致OpenAI在一开始时没有完全发布GPT-2模型,而是选择逐步发布。
GPT-2pre-training方法与gpt1一致,但在做下游任务时,不再进行微调,只进行简单的Zero-Shot,就能与同时期微调后的模型性能相差不大。
总的来说,GPT-2是GPT的一个升级版,它在模型大小、训练数据量以及生成能力等方面都有所提升。
5.gpt3
GPT3 可以理解为 GPT2 的升级版,使用了 45TB 的训练数据,拥有 175B 的参数量
GPT3 主要提出了两个概念:
情景(in-context)学习:在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测来补全任务中的其他示例。即,情境学习要求预训练模型要对任务本身进行理解。情境学习就是对模型进行引导,教会它应当输出什么内容,比如翻译任务可以采用输入:请把以下英文翻译为中文:Today is a good day。
情境学习分为三类:Zero-shot, one-shot and few-shot。GPT3 打出的口号就是“告别微调的 GPT3”,它可以通过不使用一条样例的 Zero-shot、仅使用一条样例的 One-shot 和使用少量样例的 Few-shot 来完成推理任务。下面是对比微调模型和 GPT3 三种不同的样本推理形式图。
下游任务:
本文聚焦于系统分析同一下游任务不同设置下,模型情境学习能力的差异:
Fine-tuning(FT) :利用成千上万的下游任务标注数据来更新预训练模型中的权重。缺点:每个新的下游任务都需要大量的标注预料,模型不能在样本外推预测时具有好效果,说明FT导致模型的泛化性降低。
Few-Shot(FS):模型在测试阶段可以得到少量的下游任务示例作为限制条件,但是不允许更新预训练模型中的权重。FS的主要优点是并不需要大量的下游任务数据。FS的主要缺点是不仅与fine-tune的SOTA模型性能差距较大且仍需要少量的下游任务数据。
One-Shot(1S):这种方式与人类沟通的方式最相似。
Zero-Shot(0S):0S的方式是非常具有挑战的,即使是人类有时候也难以仅依赖任务描述而没有示例的情况下理解一个任务。但0S设置下的性能是最与人类的水平具有可比性的。
6.chatgpt
ChatGPT是一个基于GPT3的聊天机器人,它利用了OpenAI的最新技术来模拟人类的对话。ChatGPT不仅可以回答问题,还可以进行闲聊和撰写文本,具有广泛的应用前景。
ChatGPT 与 GPT-3 的比较
1. 两个模型之间的相似之处
ChatGPT 和 GPT-3 都是 OpenAI 开发的语言模型,它们在来自各种来源的大量文本数据上进行训练。两种模型都能够对文本输入产生类似人类的响应,并且都适用于聊天机器人和对话式 AI 系统等任务。
2. 两个模型之间的差异
ChatGPT 和 GPT-3 之间有几个关键区别。
- 首先,ChatGPT 是专门为会话任务设计的,而 GPT-3 是一种更通用的模型,可用于广泛的语言相关任务。
- 其次,与 GPT-3 相比,ChatGPT 使用的数据量较少,这可能会影响其生成多样化和细微响应的能力。
- 最后,GPT-3 比 ChatGPT 更大更强大,有 1750 亿个参数,而 ChatGPT 只有 15 亿个参数。
ChatGPT 是一种最先进的会话语言模型,已经过来自各种来源的大量文本数据的训练,包括社交媒体、书籍和新闻文章。该模型能够对文本输入生成类似人类的响应,使其适用于聊天机器人和对话式人工智能系统等任务。
另一方面,GPT-3 是一种大规模语言模型,它已经在来自各种来源的大量文本数据上进行了训练。它能够产生类似人类的反应,可用于广泛的与语言相关的任务。
就相似性而言,ChatGPT 和 GPT-3 都在大量文本数据上进行训练,使它们能够对文本输入生成类似人类的响应。它们也都由 OpenAI 开发,被认为是最先进的语言模型。
但是,这两种模型之间也存在一些关键差异。ChatGPT 专为会话任务而设计,而 GPT-3 更通用,可用于更广泛的语言相关任务。此外,ChatGPT 接受了多种语言模式和风格的训练,与 GPT-3 相比,它更能够生成多样化和细微的响应。
就何时使用每种模型而言,ChatGPT 最适合需要自然、类人对话的任务,例如聊天机器人和对话式 AI 系统。另一方面,GPT-3 最适合需要通用语言模型的任务,例如文本生成和翻译。
7.大模型
大模型的基座是transformer,在这个基础上,增加一些变种,修改下结构,或者增加数据量。
其它:
transformer:
编码器可以用来做分类任务,解码器可以用来做语言建模。应用到各大主流模型中,会有意想不到的效果,最近看的论文中,大多从transformer中摘取一些结构,用在业务场景模型中。
参考:
1.双向lstm

















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









