







导数
之所以求导,是因为我们的优化模型的求解都是通过求导来进行的,深度学习或者说神经网络当中最重要的一个要素是反向传播算法(Back propagation)。反向传播算法与数学当中求导链式法则有非常密切的关系,当前的流行的网络结构,无不遵循这个法则,比如计算视觉当中的LeNet、AlexNet、GoogLeNet、VGG、ResNet,还有其它的各种网络。


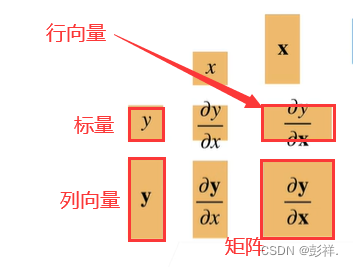
当然我们在pytorch中是不需要自己来求导的,但仍要我们掌握一下
自动求导
在pytorch乃至整个神经网络中,链式求导法则是十分重要的,尽管我们不需要自己手动计算,但我们依旧要掌握相关概念,如计算图,其实际上的运算流程与链式求导法则相同
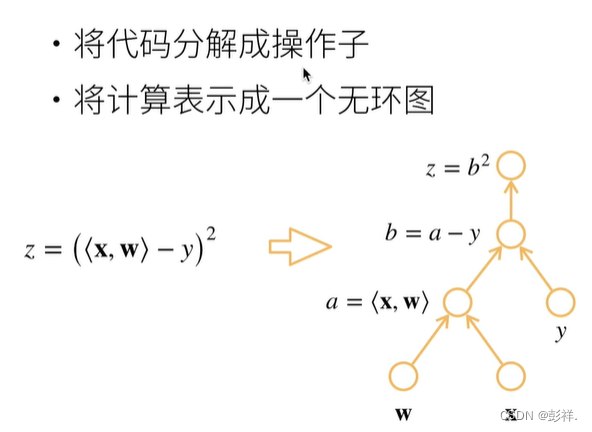

正向传播”求损失,“反向传播”回传误差
一个Tensor中通常会记录如下图中所示的属性:
- data: 即存储的数据信息
- requires_grad: 设置为True则表示该Tensor需要求导
- grad:该Tensor的梯度值,只有自动求导后,才有值,每次在计算backward时都需要将前一时刻的梯度归零,否则梯度值会一直累加。
- grad_fn: 叶子节点通常为None,只有中间节点的 grad_fn 才有效,用于指示梯度函数是哪种类型。
- is_leaf: 用来指示该Tensor是否是叶子节点
import torch
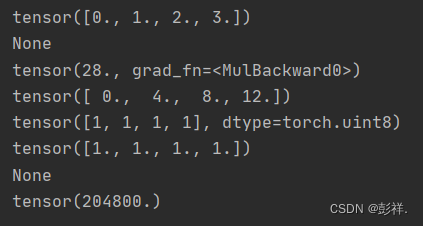
x = torch.arange(4.0)
print(x)#指定参数reuqires_grad=True来建立一个反向传播图,从而能够计算梯度
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True) 指定我要在这里存储x的梯度
print(x.grad) # 默认值是None 通过该值来获取梯度
y=2*torch.dot(x,x)#对于矩阵而言,内积即为平方,则2*x^2的导数即为4*x,注意dot(x,x)内积为标量,而x作为向量,x*x则为矩阵,我们不对其求导
print(y)
y.backward()#通过y的反向传播函数;来调用,即求导
print(x.grad)#计算出x的梯度
print(x.grad==4*x)
x.grad.zero_()#默认情况下,pytorch会累积梯度,因此我们在计算另一个数值前需要清零
y=x.sum()
y.backward()
print(x.grad)
x.grad.zero_()
y = x * x
u = y.detach()#将y当作一个常数,而不是一个x的函数,则u也是常数
z = u * x
z.sum().backward()#这是先求和再求导的意思。在深度学习中,我们的目的不是计算微分矩阵,而是批量中每个样本单独计算的偏导数之和,
# 上面的报错信息意思
















 1617
1617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











