






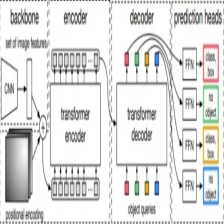


先前介绍了RT-DETR推理单张图像的案例,今天则介绍以下如何利用RT-DETR来进行视频推理。
事实上,进行视频推理的过程与单张图片的过程及其类似,就是将原本的视频切分为多帧图像后再进行推理即可。这里面涉及到Image等相关操作,今天便借此机会梳理一遍。
我们的实现思路很简单,其步骤如下:
- 将视频拆分为多帧
- 将多帧图像依次输入RT-DETR模型中进行检测
- 将多帧图像的检测结果合并为视频
利用cv2生成视频读取器,读取视频
classes = ['car','truck',"bus"]
videoname = '1.mp4'
capture = cv2.VideoCapture(videoname)
images = []
通过循环将视频拆分为多帧图像
if capture.isOpened():
while True:
ret,img=capture.read() # img 就是一帧图片,此时的img是ndarray格式,即numpy的数组类型
if not ret:break # 当获取完最后一帧就结束
img=cv2.resize(img,(640,640))#由于模型输入的图像尺寸固定为640*640,因此需要转换
img = Image.fromarray(img)#将数组类型转换为Image类型
img = img.convert('RGB')#通道位置置换
im_data = ToTensor()(img)[None]#模型输入类型为tensor,故将其转换为tensor类型
size = torch.tensor([[640, 640]])#设定输入图像的尺寸
加载onnx模型文件,并判断GPU是否可用,同时进行前向推理,并计算FPS
if torch.cuda.is_available():
print("GPU")
sess = ort.InferenceSession("model.onnx", None, providers=["CUDAExecutionProvider"])
else:
print("CPU")
sess= ort.InferenceSession("model.onnx", None)
import time
start = time.time()
output = sess.run(
output_names=['labels', 'boxes', 'scores'],
#output_names=None,
input_feed={'images': im_data.data.numpy(), "orig_target_sizes": size.data.numpy()},
)
end = time.time()
fps = 1.0 / (end - start)
print(fps)
根据结果获取目标类别,标注框与得分,并将其绘制在每张图像上
labels, boxes, scores = output
draw = ImageDraw.Draw(img)#生成ImageDraw对象,用于画图
thrh = 0.6
for i in range(im_data.shape[0]):
scr = scores[i]
lab = labels[i][scr > thrh]
box = boxes[i][scr > thrh]
for l, b in zip(lab, box):
draw.rectangle(list(b), outline='red',)#ImageDraw对象画框并写入类别,因为原本输出的类别是0,1,2,需要使用定义的数组来获取其真实类别名称
draw.text((b[0], b[1] - 10), text=str(classes[l.item()]),font_size=16, fill='blue', )
images.append(img)#将画好的每张图加入到images数组中
视频合成,指定合成视频的名称,帧率等信息,将images中的图像合成为视频
video_name = 'output.mp4'
fps = 30 # 每秒钟30帧
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
video = cv2.VideoWriter(video_name, fourcc, fps, (640,640))
# 合成视频
for i in range(len(images)):
img = images[i]
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
video.write(img)
可以看到,其在视频推理过程中,对CPU的利用率明显增高

当然我们也可以直接将其生成gif
imageio.mimsave('output.gif',images,fps=25)
完整代码如下:
import torch
import onnxruntime as ort
from PIL import Image, ImageDraw
from torchvision.transforms import ToTensor
import cv2
import imageio
import numpy as np
import os
if __name__ == "__main__":
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
##################
classes = ['car','truck',"bus"]
##################
videoname = '1.mp4'
capture = cv2.VideoCapture(videoname)
images = []
if capture.isOpened():
while True:
ret,img=capture.read() # img 就是一帧图片
if not ret:break # 当获取完最后一帧就结束
img=cv2.resize(img,(640,640))
img = Image.fromarray(img)
img = img.convert('RGB')
im_data = ToTensor()(img)[None]
size = torch.tensor([[640, 640]])
if torch.cuda.is_available():
print("GPU")
sess = ort.InferenceSession("model.onnx", None, providers=["CUDAExecutionProvider"])
else:
print("CPU")
sess= ort.InferenceSession("model.onnx", None)
import time
start = time.time()
output = sess.run(
output_names=['labels', 'boxes', 'scores'],
#output_names=None,
input_feed={'images': im_data.data.numpy(), "orig_target_sizes": size.data.numpy()},
)
end = time.time()
fps = 1.0 / (end - start)
print(fps)
labels, boxes, scores = output
draw = ImageDraw.Draw(img)
thrh = 0.6
for i in range(im_data.shape[0]):
scr = scores[i]
lab = labels[i][scr > thrh]
box = boxes[i][scr > thrh]
for l, b in zip(lab, box):
draw.rectangle(list(b), outline='red',)
draw.text((b[0], b[1] - 10), text=str(classes[l.item()]),font_size=16, fill='blue', )
images.append(img)
# 可以用 cv2.imshow() 查看这一帧,也可以逐帧保存
else:
print('视频打开失败!')
#############
img.save('2.jpg')
imageio.mimsave('output.gif',images,fps=25)
video_name = 'output.mp4'
fps = 30 # 每秒钟30帧
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
video = cv2.VideoWriter(video_name, fourcc, fps, (640,640))
# 合成视频
for i in range(len(images)):
img = images[i]
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
video.write(img)
















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











