






代理模型——SVM笔记
支持向量机(SVM): 是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)与逻辑回归和神经网络相比,支持向量机在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。SVM 适合中小型数据样本、非线性、高维的分类问题。
分为4种类型:线性可分,硬间隔(是完全分类准确,不能存在分类错误的情况,很容易发生过拟合),软间隔(允许一定量的样本分类错误,引入松弛变量和惩罚参数。),线性不可分(SVM 可以使用所谓的核技巧(kernel trick),将数据映射到更高维度的空间中,以便找到可以分隔数据的超平面)。
算法思想:找到集合边缘上的若干数据(称为支持向量(Support Vector))用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大(样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。)(SVM的最终目的:用拉格朗日乘子法和KKT条件求解最优值)。
SVM推导过程:找到一个平面(等价于求参数 w , b w,b w,b),使得离平面最近的点,能够最远(离决策面最远)。即优化目标
设平面方程为: w T x + b = 0 {w^T}x + b = 0 wTx+b=0, x x x到面的距离=平面法向量的单位方向向量×距离

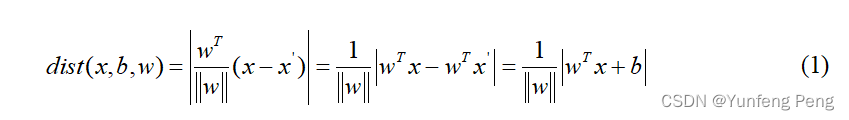
决策方程:
y
(
x
)
=
w
T
Φ
(
x
)
+
b
y(x) = {w^T}\Phi (x) + b
y(x)=wTΦ(x)+b,(其中
Φ
(
x
)
\Phi (x)
Φ(x)是对数据进行核变换后面说),下面是决策的前提,有监督的二分类。
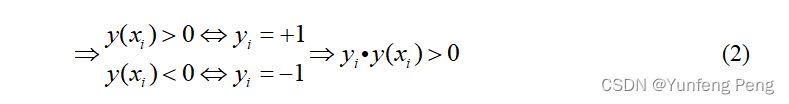
化简距离公式(去绝对值),利用(2)的条件,化简(1)

优化目标:使离决策面最近的点距离最远(胖)
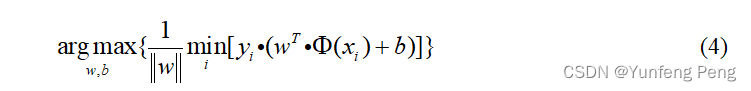
缩放变换:(之前我们认为恒大于0,现在严格了些大于1)
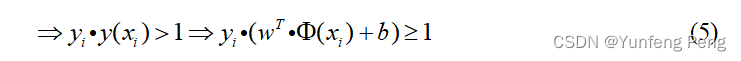
将(5)带入(4)中,化简后只需要考虑 arg max w , b 1 ∥ w ∥ \mathop {\arg \max }\limits_{w,b} {1 \over {\left\| w \right\|}} w,bargmax∥w∥1即可
目标函求解
当前目标函数: max w , b 1 ∥ w ∥ \mathop {{{\max }_{w,b}}}\limits_{} {1 \over {\left\| w \right\|}} maxw,b∥w∥1,约束条件 y i ( w T Φ ( x i ) + b ) ≥ 1 {y_i}({w^T}\Phi ({x_i}) + b) \ge 1 yi(wTΦ(xi)+b)≥1
机器学习中的常规套路:将求解极大值问题转换成极小值问题 min w , b 1 2 w 2 {\min _{w,b}}{1 \over 2}{w^2} minw,b21w2
应用拉格朗日乘子法求解(在条件下求极值):
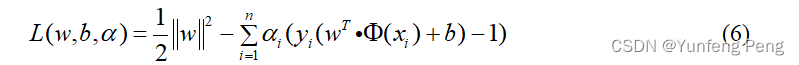
利用KKT条件(对偶性质)等到下面的求解式子:
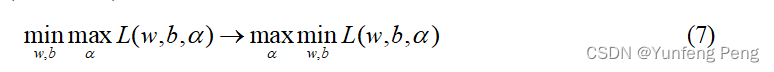
KKT条件没必要推导,几十页的推理过程,知道就行。
求解我们在拉格朗日乘子法的目标函数: max α min w , b L ( w , b , α ) \mathop {\max }\limits_\alpha \mathop {\min }\limits_{w,b} L(w,b,\alpha ) αmaxw,bminL(w,b,α),先求 min w , b L ( w , b , α ) \mathop {\min }\limits_{w,b} L(w,b,\alpha ) w,bminL(w,b,α)
对
w
w
w求偏导: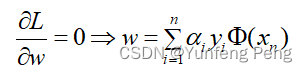
对
b
b
b求偏导: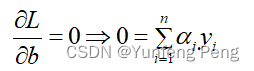
将的
w
w
w偏导和
b
b
b的偏导代入到(6)中: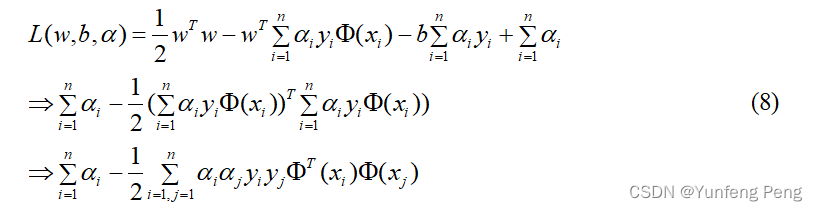
完成了第一步的求解: min w , b L ( w , b , α ) \mathop {\min }\limits_{w,b} L(w,b,\alpha ) w,bminL(w,b,α)
继续对
α
\alpha
α求极大值: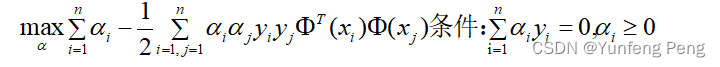
求极大值转换成求极小值: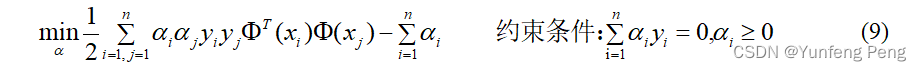
公式(9)也就是最终的目标函数了,将样本点数据带入,求出 α \alpha α,从而求出 w w w,然后求出 b = y ( x i ) − w T Φ ( x i ) b = y({x_i}) - {w^T}\Phi ({x_i}) b=y(xi)−wTΦ(xi) (所有的样本点,有其他的方法不用带入所有的样本点,例如SMO),最终求得平面方程。(只有支持向量提供作用,因为其他的点的 α \alpha α为0,从而 w w w为0,所以与其他样本点无关)。
软间隔(soft-margin):有时候数据中有一些噪音点,如果考虑它们咱们的线就不太好了。把不好的那个点可以看做噪声点(异常点)。

之前的方法要求要把两类点完全分得开,这个要求有点过于严格了,放宽要求,为了解决这个问题,引入松弛因子和惩罚参数。
y
i
(
w
T
Φ
(
x
i
)
+
b
)
≥
1
−
ξ
{y_i}({w^T}\Phi ({x_i}) + b) \ge 1 - \xi
yi(wTΦ(xi)+b)≥1−ξ
新的目标函数:
min
1
2
∥
w
∥
2
+
C
∑
i
=
1
n
ξ
i
\min {1 \over 2}{\left\| w \right\|^2} + C\sum\limits_{i = 1}^n {{\xi _i}}
min21∥w∥2+Ci=1∑nξi
当C趋近于很大时:意味着分类严格不能有错误。当C趋近于很小时:意味着可以有更大的错误容忍。
接着利用拉格朗日乘子法求解极值,和上面的使同样的解法。
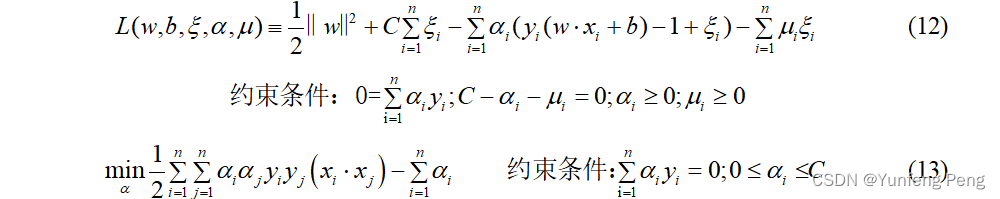
公式(13)也就是代惩罚项的最终目标函数了,将样本点数据带入,求出 α \alpha α,从而求出 w w w,最终求出超平面。
核函数:映射到高维空间,他没有将样本点映射到高维空间(如果要将样本点映射到高维空间再求他的内积,复杂度呈指数的形式扩大),它是利用和函数直接先求内积然后映射到高维空间。这也是为什么SVM流行的核心原因。

比较好用的核函数(SVM非线性的决策边界和神经网络挺像的),就是高斯核函数(将原始特征映射成高斯的距离特征):
K
(
X
,
Y
)
=
exp
{
−
∥
X
−
Y
∥
2
2
σ
2
}
K(X,Y) = \exp \left\{ { - {{{{\left\| {X - Y} \right\|}^2}} \over {2{\sigma ^2}}}} \right\}
K(X,Y)=exp{−2σ2∥X−Y∥2}。注:没必要自己去发现一个核函数,这么多年了,都没发现更好的。
决策边界和神经网络挺像的),就是高斯核函数(将原始特征映射成高斯的距离特征):。注:没必要自己去发现一个核函数,这么多年了,都没发现更好的。















 1733
1733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









