






纸上得来终觉浅,绝知此事要躬行。
网上分析 resnet 的帖子和博客有很多,但是我还是建议大家去看一下论文的原文,一定会有不一样的收获。
按照原文的意思,将underlying mapping H(x) , 表示为 F(x ) + x 的这种形式;
但是使用加法的前提就是 F(x) 和 x 的 dimension 要是相同的,如果没有下采样层存在的话,我们单单使用卷积操作,
是可以控制 padding的方式来达到 dimension 相同的效果的。
但是一个神经网络不能没有下采样层的存在, 所以要想办法解决dimension的问题。
文章中给出了两种方案,一种是 ‘ 补0 ’, 也就是维度减少后,简单的补充0进去,以达到dimension相同的目的。
另一种方案就是使用 projection shortcut 的方法,具体的方法大家可以自行翻看论文的原文,我认为这是非常有必要的,虽然会需要一点时间,但是这确实是值得的。
所以,残差网络在搭建的时候要考虑两种形式的 shortcut ,一种是 identity shortcut 另一种是projection shortcut。
下面我们就这两种形式来分开说;
首先是 identity shortcut

这是两种 identity mapping 的结构图, 左图为普通结构,右图为bottle neck结构
任意一种结构的左侧的直线结构是神经网络的主路 ; 右侧的曲线称为 ‘ shortcut ’, 它允许梯度直接反向传播到更浅的层。
通过这些残差块堆叠在一起,可以形成一个非常深的网络。
并且这种方式使得每一个残差块能够很容易学习到恒等映射(identity mapping),这意味着我们可以添加很多的残差块而不会损害训练集的表现 (因为如果出现精度下降,就会做恒等映射,保持和之前的精度相同)。
其实在每个残差模块内部不仅仅只是有conv 操作,还配有相应的BN 与 ReLU激活,
具体的情况可以参照下面的这张图;

对于主路径:
主路径的第一部分:
第一个CONV2D有F1个过滤器,其大小为(1,1),步长为(1,1),使用填充方式为“valid”,
命名规则为conv_name_base + '2a',使用00作为随机种子为其初始化。
第一个BatchNorm是通道的轴归一化,其命名规则为bn_name_base + '2a'。
接着使用ReLU激活函数,它没有命名也没有超参数。
主路径的第二部分:
第二个CONV2D有F2个过滤器,其大小为(f,f),步长为(1,1),使用填充方式为“same”,命名规则为conv_name_base + '2b',使用00作为随机种子为其初始化。
第二个BatchNorm是通道的轴归一化,其命名规则为bn_name_base + '2b'。
接着使用ReLU激活函数,它没有命名也没有超参数。
主路径的第三部分:
第三个CONV2D有F3个过滤器,其大小为(1,1),步长为(1,1),使用填充方式为“valid”,命名规则为conv_name_base + '2c',使用00作为随机种子为其初始化。
第三个BatchNorm是通道的轴归一化,其命名规则为bn_name_base + '2c'。
注意这里没有ReLU函数
# 注, 这里的filter 的 size 为 (1,1),(f,f), (1,1 ) 对应上面的bottle neck结构
最后一步:
将捷径与输入加在一起
使用ReLU激活函数,它没有命名也没有超参数。
下面开始这部分的实现 :
import numpy as np
import tensorflow as tf
from keras.layers import Conv2D, BatchNormalization, Activation, Add
from keras.layers import Input, ZeroPadding2D, MaxPooling2D, AveragePooling2D, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.models import Model首先是相关模块的引入,因为使用的是keras , 所以搭建网络就显得相对容易并且简洁的多。
一些相关的接口源码,均可以通过 https://keras.io/zh/ 来找到。
def identity_block(X, f, filters, stage, block):
"""
实现图3的恒等块
参数:
X - 输入的tensor类型的数据,维度为( m, n_H_prev, n_W_prev, n_H_prev )
f - 整数,指定主路径中间的CONV窗口的维度
filters - 整数列表,定义了主路径每层的卷积层的过滤器数量
stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。
block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。
返回:
X - 恒等块的输出,tensor类型,维度为(n_H, n_W, n_C)
"""
#定义命名规则
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
#获取过滤器
F1, F2, F3 = filters
#保存输入数据,将会用于为主路径添加捷径
X_shortcut = X
#主路径的第一部分
##卷积层
X = Conv2D(filters=F1, kernel_size=(1,1), strides=(1,1) ,padding="valid",
name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
##使用ReLU激活函数
X = Activation("relu")(X)
#主路径的第二部分
##卷积层
X = Conv2D(filters=F2, kernel_size=(f,f),strides=(1,1), padding="same",
name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
##使用ReLU激活函数
X = Activation("relu")(X)
#主路径的第三部分
##卷积层
X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid",
name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X)
##归一化
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
##没有ReLU激活函数
#最后一步:
##将捷径与输入加在一起
X = Add()([X,X_shortcut])
##使用ReLU激活函数
X = Activation("relu")(X)
return X
然后来看 projection shortcut 的部分
关于解释的部分,这里不再赘述了,希望大家可以多读读论文原文。
我们只根据 projection shortcut 的结构图(如下)来实现;

上面的图与 identity mapping 的唯一不同之处就在与 shortcut 上面多了一个卷积操作与BN操作,
多出来这部分的唯一目的就是为了解决维度的问题,所以在上面的路径上并没有加入ReLU 这个激活函数。
代码部分如下;
def convolutional_block(X, f, filters, stage, block, s=2):
"""
实现图5的卷积块
参数:
X - 输入的tensor类型的变量,维度为( m, n_H_prev, n_W_prev, n_C_prev)
f - 整数,指定主路径中间的CONV窗口的维度
filters - 整数列表,定义了主路径每层的卷积层的过滤器数量
stage - 整数,根据每层的位置来命名每一层,与block参数一起使用。
block - 字符串,据每层的位置来命名每一层,与stage参数一起使用。
s - 整数,指定要使用的步幅
返回:
X - 卷积块的输出,tensor类型,维度为(n_H, n_W, n_C)
"""
#定义命名规则
conv_name_base = "res" + str(stage) + block + "_branch"
bn_name_base = "bn" + str(stage) + block + "_branch"
#获取过滤器数量
F1, F2, F3 = filters
#保存输入数据
X_shortcut = X
#主路径
##主路径第一部分
X = Conv2D(filters=F1, kernel_size=(1,1), strides=(s,s), padding="valid",
name=conv_name_base+"2a", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2a")(X)
X = Activation("relu")(X)
##主路径第二部分
X = Conv2D(filters=F2, kernel_size=(f,f), strides=(1,1), padding="same",
name=conv_name_base+"2b", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2b")(X)
X = Activation("relu")(X)
##主路径第三部分
X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding="valid",
name=conv_name_base+"2c", kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3,name=bn_name_base+"2c")(X)
#捷径
X_shortcut = Conv2D(filters=F3, kernel_size=(1,1), strides=(s,s), padding="valid",
name=conv_name_base+"1", kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3,name=bn_name_base+"1")(X_shortcut)
#最后一步
X = Add()([X, X_shortcut])
X = Activation("relu")(X)
return X
OK , 我们有了上面的这两部分, 就可以开始残差网络的实现了。
在这我们先来看一下下面的这张表格:

前面两列的 18 和 34 都是普通结构的残差块(也就是 (3,3)和(3,3)相连接) ;
后面的50,101, 152 是bottle neck 结构的模块 (也即是(1,1) (3,3)(1,1)相连接);
我们这里要实现的是 resnet50 所以大家可以根据这个结构图来看一下这个网络的构造大体是个什么样子,
并且可以将其与跟其他更深的网络层次进行比较。
下图中的”ID BLOCK“是指标准的恒等块,”ID BLOCK X3“是指把三个恒等块放在一起。
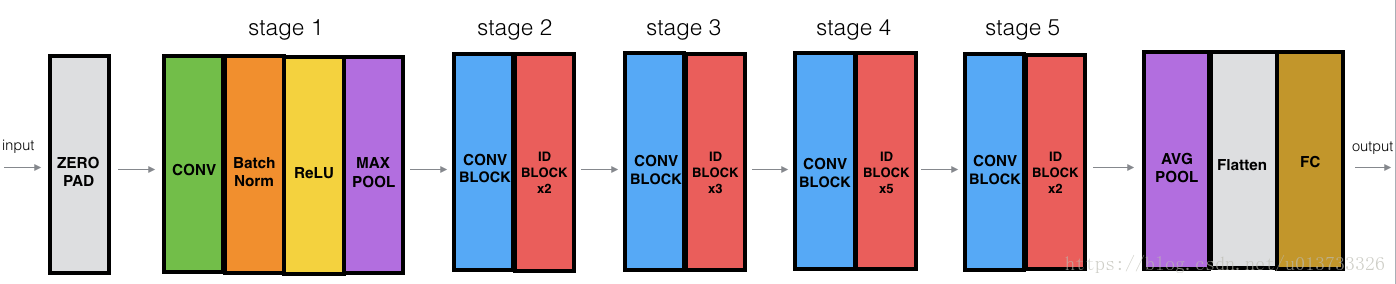
这个50层的网络的细节如下:
(与上面表格中的细节相同)
1. 对输入数据进行0填充,padding =(3,3)
stage1:
卷积层有64个过滤器,其维度为(7,7),步伐为(2,2),命名为“conv1”
规范层(BatchNorm)对输入数据进行通道轴归一化。
最大值池化层使用一个(3,3)的窗口和(2,2)的步伐。
stage2:
卷积块使用f=3个大小为[64,64,256]的过滤器,f=3,s=1,block=”a”
2个恒等块使用三个大小为[64,64,256]的过滤器,f=3,block=”b”、”c”
stage3:
卷积块使用f=3个大小为[128,128,512]的过滤器,f=3,s=2,block=”a”
3个恒等块使用三个大小为[128,128,512]的过滤器,f=3,block=”b”、”c”、”d”
stage4:
卷积块使用f=3个大小为[256,256,1024]的过滤器,f=3,s=2,block=”a”
5个恒等块使用三个大小为[256,256,1024]的过滤器,f=3,block=”b”、”c”、”d”、”e”、”f”
stage5:
卷积块使用f=3个大小为[512,512,2048]的过滤器,f=3,s=2,block=”a”
2个恒等块使用三个大小为[256,256,2048]的过滤器,f=3,block=”b”、”c”
均值池化层使用维度为(2,2)的窗口,命名为“avg_pool”
展开操作没有任何超参数以及命名
全连接层(密集连接)使用softmax激活函数,命名为"fc" + str(classes)
实现如下:
def ResNet50(input_shape=(64,64,3),classes=6):
"""
实现ResNet50
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
参数:
input_shape - 图像数据集的维度
classes - 整数,分类数
返回:
model - Keras框架的模型
"""
#定义tensor类型的输入数据
X_input = Input(input_shape)
#0填充
X = ZeroPadding2D((3,3))(X_input)
#stage1
X = Conv2D(filters=64, kernel_size=(7,7), strides=(2,2), name="conv1",
kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name="bn_conv1")(X)
X = Activation("relu")(X)
X = MaxPooling2D(pool_size=(3,3), strides=(2,2))(X)
#stage2
X = convolutional_block(X, f=3, filters=[64,64,256], stage=2, block="a", s=1)
X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="b")
X = identity_block(X, f=3, filters=[64,64,256], stage=2, block="c")
#stage3
X = convolutional_block(X, f=3, filters=[128,128,512], stage=3, block="a", s=2)
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="b")
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="c")
X = identity_block(X, f=3, filters=[128,128,512], stage=3, block="d")
#stage4
X = convolutional_block(X, f=3, filters=[256,256,1024], stage=4, block="a", s=2)
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="b")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="c")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="d")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="e")
X = identity_block(X, f=3, filters=[256,256,1024], stage=4, block="f")
#stage5
X = convolutional_block(X, f=3, filters=[512,512,2048], stage=5, block="a", s=2)
X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="b")
X = identity_block(X, f=3, filters=[512,512,2048], stage=5, block="c")
#均值池化层
X = AveragePooling2D(pool_size=(2,2),padding="same")(X)
#输出层
X = Flatten()(X)
X = Dense(classes, activation="softmax", name="fc"+str(classes),
kernel_initializer=glorot_uniform(seed=0))(X)
#创建模型
model = Model(inputs=X_input, outputs=X, name="ResNet50")
return model
然后是模型的实例化和编译
model = ResNet50(input_shape=(64,64,3),classes=6)
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["accuracy"])
模型的工作到这里就OK 了
参考
https://blog.csdn.net/Solo95/article/details/85176688
https://blog.csdn.net/u013733326/article/details/80250818
他翻译的原文在这里 https://blog.csdn.net/Solo95/article/details/85177557
对于以上博主的工作表示万分感谢 !!!!














 639
639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









