







ResNet
0 总结
2. Related Work
- Residual Representation
- VLAD
- Multigrid
- Shortcut Connections
- highway networks
3. Deep Residual Learning
3.1. Residual Learning
假设多层非线性网络可以近似一个函数 H ( x ) H(x) H(x),等价而言 应当也可以近似残差 F ( x ) : = H ( x ) − x F(x) := H(x)-x F(x):=H(x)−x。不管是原函数或残差函数,都可以用来获得原函数。
但,优化得到两者的难度不同。
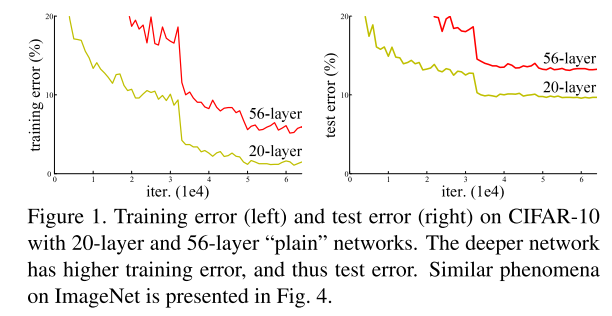
对比实验:增加网络到一定程度后,training error反而上涨。
但是:如果增加的层数能构建出一个identity映射,增加identity映射不应该使training error上涨(因为增加的不会改变输出,也就不改变error)。
因此:说明多层非线性网络,可能很难通过优化,使增加的这些层趋近于identity映射。
反而:如果是估计残差函数,优化器只需要优化到使得所有weights都为零,就是一个identity映射。(直观而言,这要简单一些)
our reformulation may help to precondition the problem??
3.2. Identity Mapping by Shortcuts
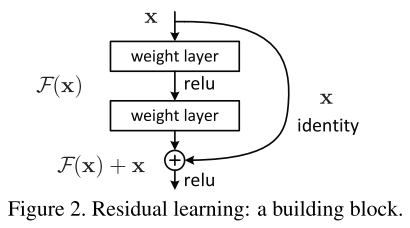
Identity Mapping的构建方式。
注意:
- 第二个非线性ReLU在残差和identity相加之后。
- 这种形式,没有增加参数,也没有增加计算量。(这一特点对于对比实验也很重要,因为普通网络和对应残差网络的参数、层数、计算量都一样)
- 如果输出和输入维度不同,则 W s x W_s x Wsx投影到对应维度。
-
F
(
x
)
F(x)
F(x)是简单的线性
W
x
Wx
Wx时没有作用,需要2-3层以上线性FC,也可以是卷积。
3.3. Network Architectures
第一个用于比较的网络基于VGG-19,改为34层,变成plain网络。残差网络在此基础上每两层增加一个shortcuts。
在feature map大小减半/filter数量翻倍时,有两种方式shortcut:
- zero padding
- 通过1x1 conv进行projection??
3.4. Implementation
基本参考AlexNet、VGG、BN的做法,要点如下
Training
- (VGG)随机rescale到[256,480]大小
- (AlexNet/VGG)随机crop出224x224、随机flip
- (AlexNet)per-pixel均值subtract
- (VGG)color augmentation(AlexNet里的PCA处理)
- (BN)每个卷积之后、activate之前,都用BN
- 从头开始训练plain/residual 网络
- mini-batch size 256
- (VGG/AlexNet)learning rate 从0.1开始,当error plateau时,除以10
- 训练了 60 × 1 0 4 60\times 10^4 60×104个iteration
- weight decay 0.0001, momentum 0.9
- (BN)没有用dropout
Testing
- (AlexNet)标准10-crop方式
- (VGG)用全卷积方式,对多scale的分数进行平均
4. Experiments
4.1. ImageNet Classification
Plain Networks
用34层和18层网络,对比出现了退化现象:validation error 34-layer > 18-layer。作者认为这不是来自于梯度消失(vanishing gradients),因为:
- 用BN训练,保证前向传播信号有 non-zero variances
- 确认了反向传播的梯度norm很正常
猜测:更深的plain network,指数级地更难收敛,导致了更难降低训练误差。
Residual Networks
同样用34和18层网络,有3个主要的现象:
- 34层training error显著好于18层,并且validation error同样。说明:层数增加的退化问题得到解决。
- 和plain网络相比,residual网络更好。说明:很深的网络,残差学习有效果。
- 18层的res/plain网络精度相当,但resnet收敛更快。
Identity vs Projection Shortcuts
对比identity和projection两种shortcuts。
- A) 都是identity,zero-padding来升维,所有shortcuts都没有参数要学
- B) projection来升维,其他都是identity
- C) 所有都是projection
从结果来看,3)>2)>=1),都只有很轻微的提升。这个区别,更可能来源于projection带来的更多学习参数,没有本质上的提升,所以之后都不用projection。Identity不提升复杂度,对于接下来的bottleneck架构更重要。
Deeper Bottleneck Architecture
一个bottleneck,是1x1 + 3x3 + 1x1,分别用来降维、卷积、升维。对于这种设计,identity更有效。
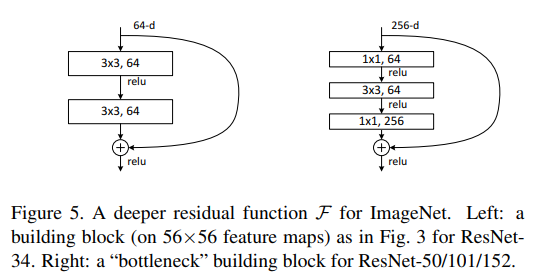
50/101/152-layer ResNet
把34层网络里的2层,换成3层bottleneck,就是50层。用B)来升维,也就是正常都用identity,升维用projection。
增加更多3层block,可以构造101/152层ResNet。
50-layer ResNet: 3.8B FLOPS
101-layer ResNet: x
152-layer ResNet: 11.3B FLOPS
VGG-16: 15.3B FLOPS
VGG-19: 19.6B FLOPS
4.2. CIFAR-10 and Analysis
残差网络的response相比plain网络更小。残差函数通常更接近0。
更深的残差网络,response更小,每层对signal的修改更少。
1000层的网络,很可能overfit。但却能在train时收敛。
4.3. Object Detection on PASCAL and MS COCO
TODO: 先看了BN、RCNN、FPN基础知识后再补充。















 1496
1496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









