







上一节我们讲到了如何做一个最简单的cpu, 现代的CPU相比与早期的CPU有很多进步的地方,是一代又一代人不断创新优化的成果,本篇文章就简单介绍从最简单的cpu到现在的告诉运算的cpu都有什么进步
一、独立电路指令集拓展
用最简单的cpu实现一个乘法或者除法,其实是通过不断加法或者减法来实现的,研究者发现这种方式需要用到的时钟周期多,带来高耗时,于是工程师提出了一种思路是否可以用复杂度替换时间的消耗, 设计了很多具有独立功能的计算单元,例如乘法器,除法器等等,使cpu的复杂度更高了,但是制行了更快速。 现在cpu设计了专门的电路来处理图形操作,解码压缩,加密等运算,例如MMX,SSE, 3DNOW等指令集,MMX用多位并行运算可以同时计算8-16个数的加减运算,达到快速计算的目的

随着越来越多的独立电路加入,指令集也越来越多,现在intel拥有上千个指令集来加速cpu的运算
二、 快速传递数据给CPU
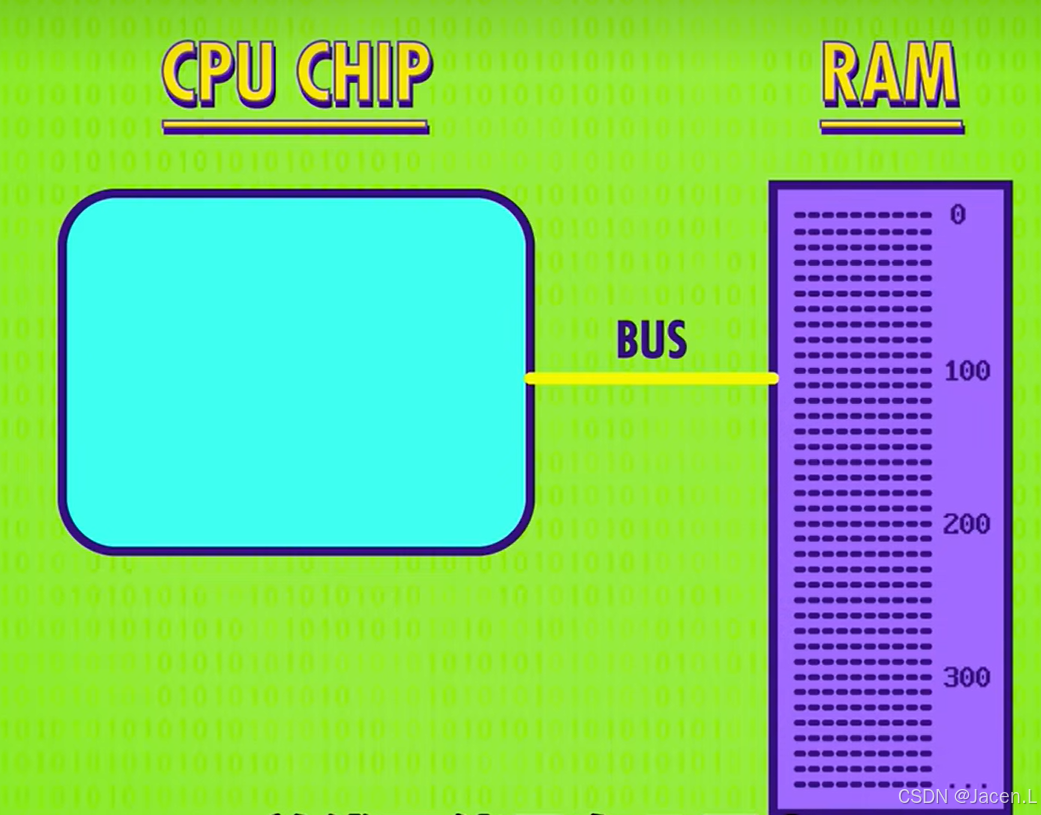 早期的CPU,RAM是在cpu外部它们之间用总线链接,CPU每秒可以执行上亿个指令,但是数据存储在RAM当中,每次读取数据都得获取指令,解码,执行,才能将数据加载进cpu,这样就浪费了很多的时钟周期,cpu空等数据。
早期的CPU,RAM是在cpu外部它们之间用总线链接,CPU每秒可以执行上亿个指令,但是数据存储在RAM当中,每次读取数据都得获取指令,解码,执行,才能将数据加载进cpu,这样就浪费了很多的时钟周期,cpu空等数据。
解决方法是在cpu内部增加一块内存的缓存,一般只有几KB,而RAM一般都有几GB,所以每次cache都是读取一小块RAM内的内存到cache内,虽然花时间比较久,但是一小块内存都读取进cpu,由于连续的数据一般都是有关联,cpu读取数据一般也是顺序读取的,也避免了CPU多次读取RAM。
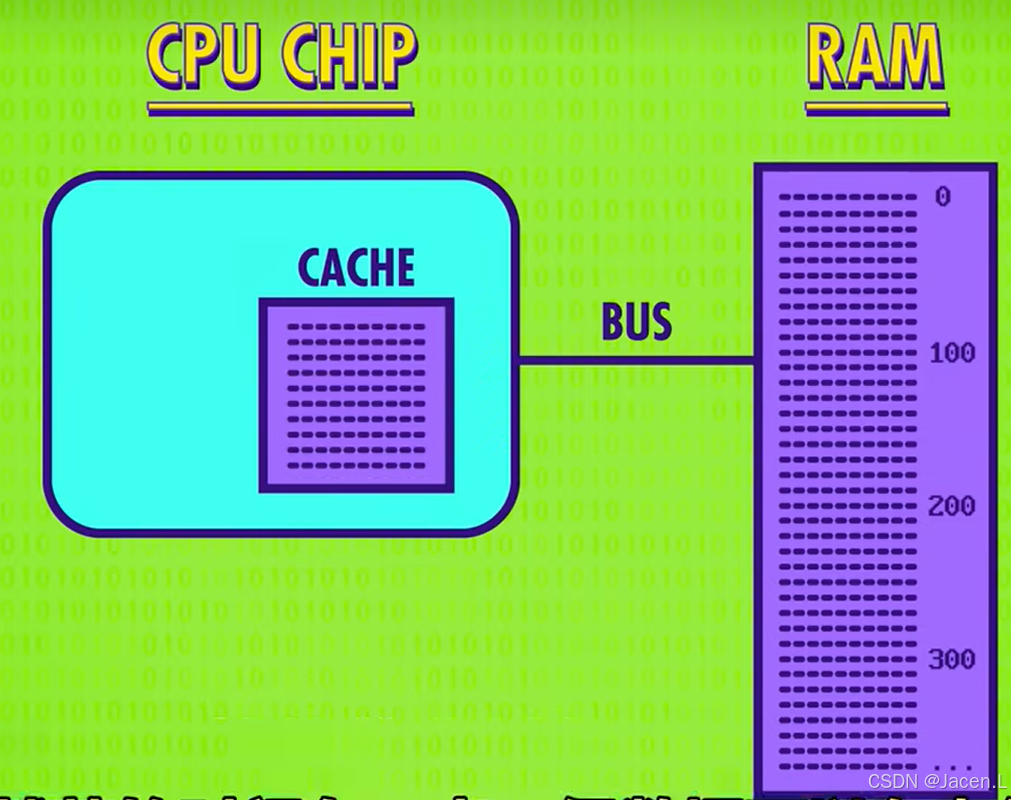
如果CPU需要读取的数据已经在CACHE内叫做缓存命中(CACHE HIT),反之叫做缓存未命中(CACHE MISS)这也是衡量一个程序效率的指标。
假设CPU写了一块CACHE内的数据,此时CACHE内的数据就和RAM内的数据不同步了,因此每一块缓存内都有一个标记,科学家叫做 脏位(Dirty Bit), 同步一般发生在cache缓存满了,cpu又需要读取数据的时候,在加载新的内容进CACHE的时候,会先检查脏位,如果是脏的,则会先将CACHE内容写回RAM,再进行读取。
三、 指令流水线
上一章节我们讲到了CPU处理流程的三个阶段FETCH,DECODE,EXECUTE 获取,解码和执行,cpu按照这个顺序不断循环
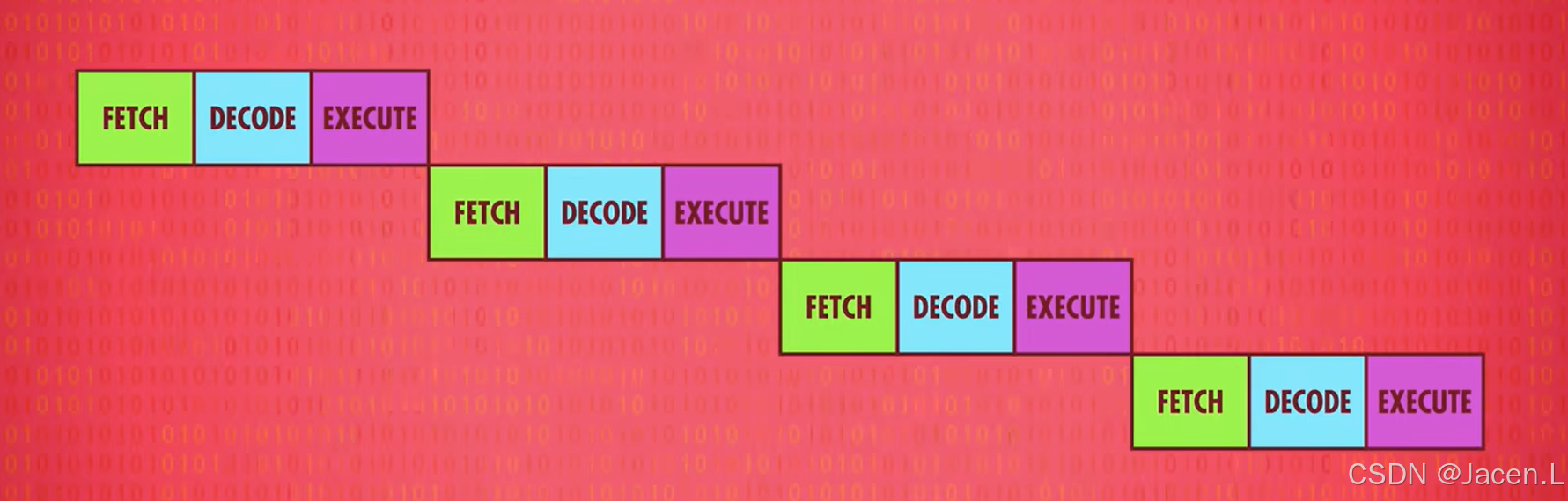
假如DECODE的同时,CPU就FETCH下一条指令呢,这样我们就会拥有三倍的效率
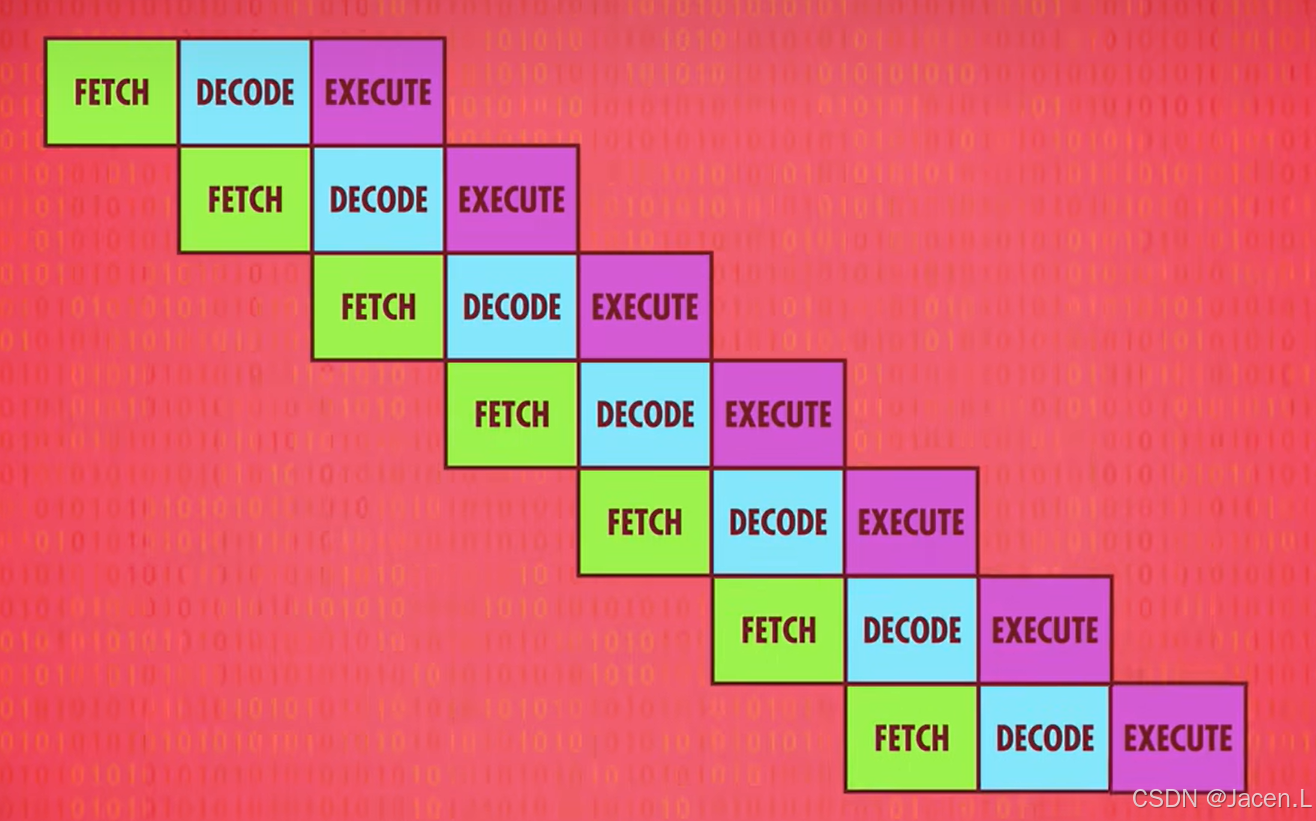
这里会出现一个问题:
数据依赖
跟数据的依赖性有关系,例如你正在读某个数据,而正在执行的指令去修改了这个数据,此时你读出来的就是老数据。所以并行执行的时候一定要关注数据之间的依赖关系。高端的处理器会提前梳理这一类的依赖关系,确保不会出现这种情况,可以预见的是这种电路非常复杂
条件跳转
跳转语句会使程序停下来,等待跳转值的确定,此时cpu就造成了空转。高端的cpu会使用一种叫做“推测执行”的方法。
可以把JUMP想象成一个岔路口,cpu会退出哪一条路径的可能性最大,并将那条路径的指令提前放进流水线执行,当然如果预测错了,就得重新执行。为了提高预测的准确性CPU产商开发了非常复杂的“分支预测”算法,现在CPU的正确率超过90%
四、超标量处理器
并行处理之后,虽然一个时钟周期内指令变多了,但是可能还远远达不到ALU的满算力,类似的那么将取指,解码执行的单元变多呢,超标量处理器(SUPERSCALAR)就出现了。
比如执行一个从内存读取数据的指令的时候,ALU闲置了,此时就可以用多个处理单元来解决,读取内存的同时,执行ALU的计算
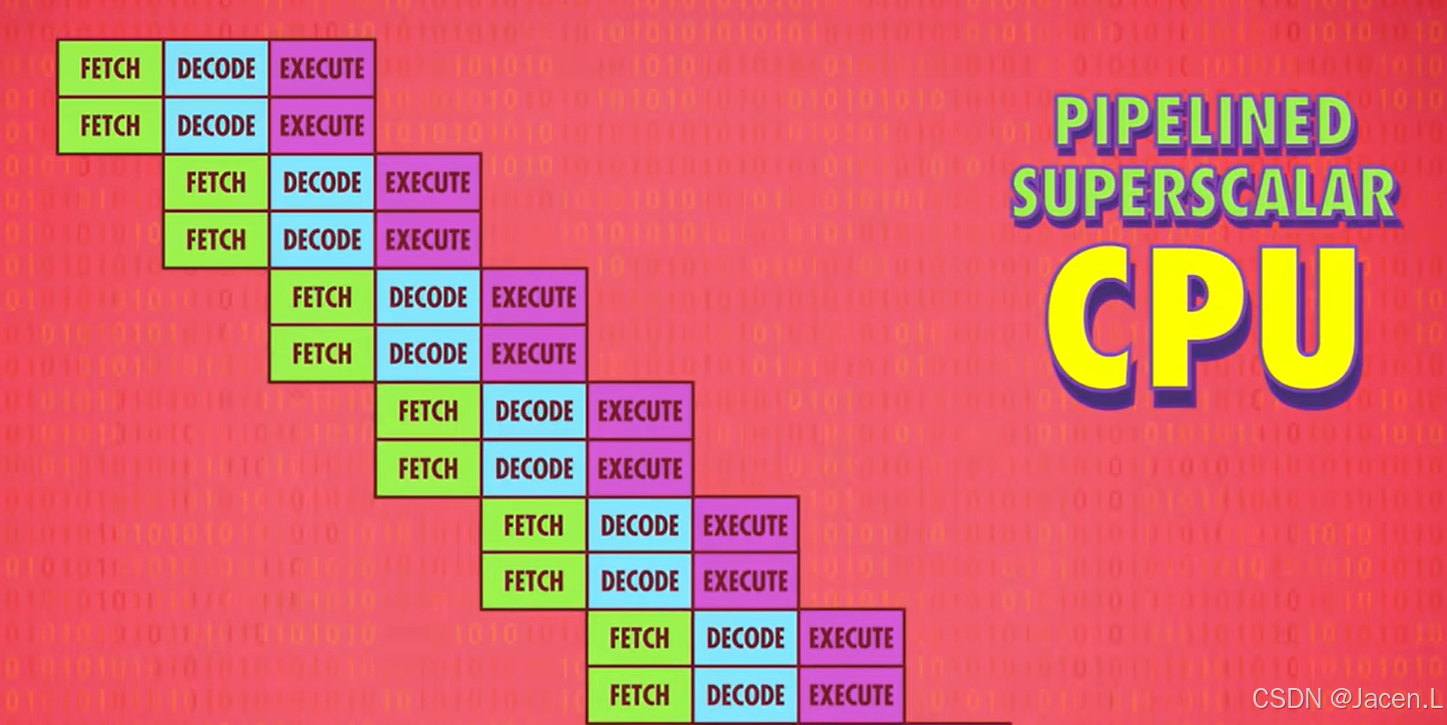
很多CPU甚至有4个,8个完全相同的ALU可以执行计算
上一章:



















 5595
5595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











