







解决的问题:在少样本情形下的开放集识别(=少样本分类+开放集识别)。与其他识别任务的区别如下
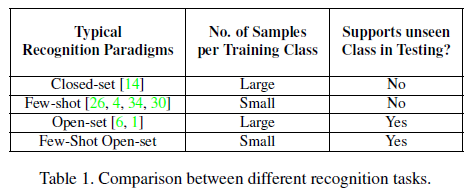
为什么要解决这个问题:1)首先,开放集识别在所有设置下都是一个挑战。在少样本的训练模式下训练的识别器面对看不见的类别的可能性并不低。因此,支持少样本的开放式识别技术比不支持的开放式识别技术更有用。2)其次,少样本开放集识别由于缺少标记数据,比大规模开放集识别更难解决。因此,少样本设置对开放集识别的研究提出了更大的挑战。3)第三,和开放集识别一样,少样本识别的主要挑战是对训练中看不到的数据做出准确的判定。由于这使得鲁棒性成为了少样本架构的主要特征,这些架构也可能在开放集识别方面表现出色。最值得注意的是,它们很可能击败大规模分类器,而大规模分类器在鲁棒性维度上得分不高。
使用的方法:介绍了一种新的开放集元学习(PEELER)算法。这结合了每集随机选择一组新的类,1)最大化这些类样本的后置熵的损失,以及2)基于马氏距离的新的度量学习公式。
步骤1:对训练问题集合,循环选择少样本 episodes (S,T) n次,即N-way K-shot选择n个问题,每个问题选择K个训练样本,测试样本任意
步骤2:根据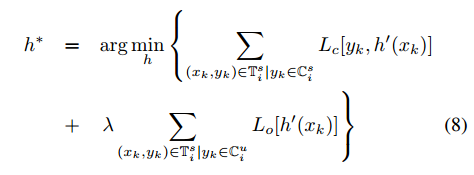 ,使用每个episodes训练一个模型h*
,使用每个episodes训练一个模型h*
,其中Lc=![]() ,(即希望最小化已知类的分类误差)
,(即希望最小化已知类的分类误差)
Lo=![]() (即希望最小化未知类的分类误差,不将未知类分到任意已知类下)。
(即希望最小化未知类的分类误差,不将未知类分到任意已知类下)。
![]() ,即使用原型距离度量进行分类
,即使用原型距离度量进行分类
![]() ,距离计算使用了高斯分布
,距离计算使用了高斯分布
步骤3:将目标任务和样本集进行训练,使用。
步骤4:测试h''
存在问题:
1.少样本分类episodes中涉及的类不应该与任何测试集重合。
可创新性:
实验结果与结论:
1.5way-5 shot >5way-1 shot > 10way-1shot,说明少样本episodes类别少更好,每类训练样本数多更好。
2.basic>softmax、openmax、G-openmax、Counter















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









