







http://blog.csdn.net/pipisorry/article/details/52916307
路径错误
spark FileNotFoundError: [Errno 2] No such file or directory: '~/ENV/spark/./bin/spark-submit'
居然是因为这个引发的错误:SPARK_HOME = ~/ENV/spark应该改成SPARK_HOME = /home/pipi/ENV/spark
spark.textFile读取用户主目录下的文件出错
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: file:/home/pipi/files/...SparkLDA/~/files
文件名改成绝对路径就不会出错了,而不能使用主目录标志~。
importerror no module named 'pyspark'
可能出错原因:
1 设置的路径应该在import语句之前
2 pyspark_python路径出错,且如果在pycharm中修改后要重启pycharm才能生效,否则还是原来的路径(可能是因为之前的路径也保存在pycharm解释器中了?)
PYSPARK_PYTHON = /home/pipi/opt/anaconda3/bin/python
Note: 并不用设置py4j的路径。
系统环境错误
1 在~/.bashrc中设置的系统环境只能在terminal shell下运行spark程序才有效,因为.bashrc is only read for interactive shells.
如果要在当前用户整个系统中都有效(包括pycharm等等IDE),就应该将系统环境变量设置在~/.profile文件中。如果是设置所有用户整个系统,修改/etc/profile或者/etc/environment吧。
2 当然也可以在代码中设置,这样不管环境有没有问题了
# spark environment settings import sys, os os.environ['SPARK_HOME'] = conf.get(SECTION, 'SPARK_HOME') sys.path.append(os.path.join(conf.get(SECTION, 'SPARK_HOME'), 'python')) os.environ["PYSPARK_PYTHON"] = conf.get(SECTION, 'PYSPARK_PYTHON') os.environ['SPARK_LOCAL_IP'] = conf.get(SECTION, 'SPARK_LOCAL_IP') os.environ['JAVA_HOME'] = conf.get(SECTION, 'JAVA_HOME') os.environ['PYTHONPATH'] = '$SPARK_HOME/python/lib/py4j-0.10.3-src.zip:$PYTHONPATH'
3 在$SPARK_HOME/conf/spark-env.sh中设置这些变量好像也只是在terminal中的shell环境中才有效
JAVA_HOME is not set
Exception: Java gateway process exited before sending the driver its port number
但是在命令行中是有的
pipi@pipicmp:~$ echo $JAVA_HOME
/home/pipi/ENV/jdk
解决方法1:在py代码中加入JAVA_HOME到os中
JAVA_HOME = /home/pipi/ENV/jdk
os.environ['JAVA_HOME'] = conf.get(SECTION, 'JAVA_HOME')
解决方法2:或者在hadoop中配置好JAVA_HOME
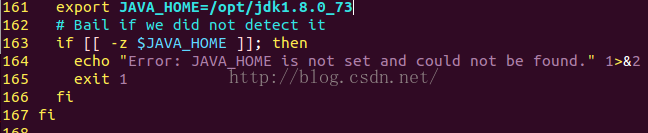
hadoop中配置JAVA_HOME
pika:~$sudo vim /usr/local/hadoop-2.6.4/libexec/hadoop-config.sh
在大概161行位置加上export JAVA_HOME=/opt/jdk1.8.0_73
KeyError: 'SPARK_HOME'
from pyspark.shell import sqlContext 语句出错
raise KeyError(key) from None KeyError: 'SPARK_HOME'
解决方法1:
代码中将SPARK_HOME加入到os.env中
os.environ['SPARK_HOME'] = conf.get(SECTION, 'SPARK_HOME')
解决方法2:import shell前要将SPARK_HOME设置放在其前面
os.environ['SPARK_HOME'] = conf.get(SECTION, 'SPARK_HOME')
解决方法3:
只要将SPARK_HOME加入到~/.profile就可以了,这样os.env就可以自动读取到。
export envfilename=~/.bashrc
export envfilename2=~/.profile
(echo "export SPARK_HOME=$ENV/spark
#export PYSPARK_PYTHON=python3
#export PATH=\${SPARK_HOME}/bin:\$PATH") | sudo tee -a $envfilename $envfilename2
. $envfilename
. $envfilename2
pyspark different python version
Exception: Python in worker has different version 2.7 than that in driver 3.5, PySpark cannot run with different minor versions
解决:设置PYSPARK_PYTHON
export ENV=~/ENV
export PYSPARK_PYTHON=$ENV/ubuntu_env/bin/python
export envfilename=~/.profile
(echo "
export SPARK_HOME=$ENV/spark
export PYSPARK_PYTHON=$PYSPARK_PYTHON
#export PATH=\${SPARK_HOME}/bin:\$PATH
") | sudo tee -a $envfilename
. $envfilename
loopback address: 127.0.1.1
WARN Utils: Your hostname, pipicmp resolves to a loopback address: 127.0.1.1; using 192.168.199.210 instead (on interface enp2s0)
解决:这个只是个warn,可以不解决,如果不想有的话,可以这样自动设置
(echo "export SPARK_LOCAL_IP=$(ifconfig | grep 'inet addr:'| grep -v '127.0.0.1' | cut -d : -f 2 | awk '{ print $1 }')") >> $SPARK_HOME/conf/spark-env.sh
皮皮blog运行错误
ValueError: Cannot run multiple SparkContexts at once
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Python version 3.5.2 (default, Sep 10 2016 08:21:44)
SparkSession available as 'spark'.
ValueError: Cannot run multiple SparkContexts at once; existing SparkContext(app=pyspark-shell, master=local[*]) created by <module> at <frozen importlib._bootstrap>:222
原因是:from pyspark.shell import sqlContext
引入的包中也定义了一个sc = spark.sparkContext导致和本代码中定义重复了。
py4j.java_gateway:Answer received: !yv
DEBUG:py4j.java_gateway:Command to send: m
未解决!!不过只是在logging中存在,debug信息,好像也没影响。
py4j.protocol.Py4JJavaError
py4j.protocol.Py4JJavaError: An error occurred while calling o49.trainLDAModel.
原因:corpus = data.zipWithIndex().map(lambda x: [x[-1], x[0:-1]]).cache()
lambda函数中的x下标在pyspark不能这样写?
解决:改成corpus = data.zipWithIndex().map(lambda x: [x[1], x[0]]).cache()就不报这个错误了,也是醉了。
py4j.protocol.Py4JError
LDA引入自from pyspark.mllib.clustering import LDA
py4j.protocol.Py4JError: An error occurred while calling o39.trainLDAModel. Trace:
py4j.Py4JException: Method trainLDAModel([class org.apache.spark.api.java.JavaRDD, class java.lang.Integer, class java.lang.Integer, class java.util.ArrayList, class java.lang.Double, class java.lang.Integer, class java.lang.Integer, class java.lang.String]) does not exist
原因:lda_model = LDA.train(corpus, maxIterations=max_iter, seed=seed, checkpointInterval=checkin_point_interval, k=K, optimizer=optimizer, docConcentration=[alpha], topicConcentration=beta)
解决:lda_model = LDA.train(corpus, maxIterations=max_iter, seed=seed, checkpointInterval=checkin_point_interval, k=K, optimizer=optimizer, docConcentration=alpha, topicConcentration=beta)
TypeError: Invalid param value given for param "docConcentration".
这个错误与上一个错误相关啊,呵呵了。。。
LDA引入自from pyspark.ml.clustering import LDA
TypeError: Invalid param value given for param "docConcentration".Could not convert 5.0 to list of floats.
原因:lda_model = LDA.train(corpus, maxIterations=max_iter, seed=seed, checkpointInterval=checkin_point_interval, k=K, optimizer=optimizer, docConcentration=alpha, topicConcentration=beta)
解决:lz设置docConcentration和TopicConcentration时,只能使用docConcentration=[value]和TopicConcentration=value两种不同的初始化方式,不知道为啥。。。否则出错。
lda_model = LDA.train(corpus, maxIterations=max_iter, seed=seed, checkpointInterval=checkin_point_interval, k=K, optimizer=optimizer, docConcentration=[alpha], topicConcentration=beta)
spark输出太多warning messages
WARN Executor: 2 block locks were not released by TID =
Lock release errors occur frequently in executor logs
原因:If there are any releasedLocks (after calling BlockManager.releaseAllLocksForTask earlier) and spark.storage.exceptionOnPinLeak is enabled (it is not by default) with no exception having been thrown while the task was running, a SparkException is thrown:
[releasedLocks] block locks were not released by TID = [taskId]:
[releasedLocks separated by comma]
Otherwise, if spark.storage.exceptionOnPinLeak is disabled or an exception was thrown by the task, the following WARN message is displayed in the logs instead:
WARN Executor: [releasedLocks] block locks were not released by TID = [taskId]:
[releasedLocks separated by comma]
Note If there are any releaseLocks, they lead to a SparkException or WARN message in the logs.
[/mastering-apache-spark-book/spark-executor-taskrunner.adoc]
mapWithState causes block lock warning?
The warning was added by: SPARK-12757 Add block-level read/write locks to BlockManager?
[connectedComponents() raises lots of warnings that say "block locks were not released by TID = ..."]
[ Lock release errors occur frequently in executor logs]解决:终于在调试log时候发现问题解决了
在简略Spark输出设置时[Spark安装和配置 ]修改过$SPARK_HOME/conf/log4j.properties.template文件只输出WARN信息,就算改成了ERROR,信息也还是会自动修改成WARN输出出来,不过多了一条提示:
Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel).
就在这时发现了一个解决方案:
根据提示在代码中加入sc.setLogLevel('ERROR')就可以解决了!
from: http://blog.csdn.net/pipisorry/article/details/52916307
ref:















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









