







文章目录
ElasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,在海量数据查询中,数据库的模糊查询性能低且不能够很好的满足用户查询需求,我们可以用Elasticsearch优化
核心概念
- 索引 (index)
ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念。
- 映射(mapping)
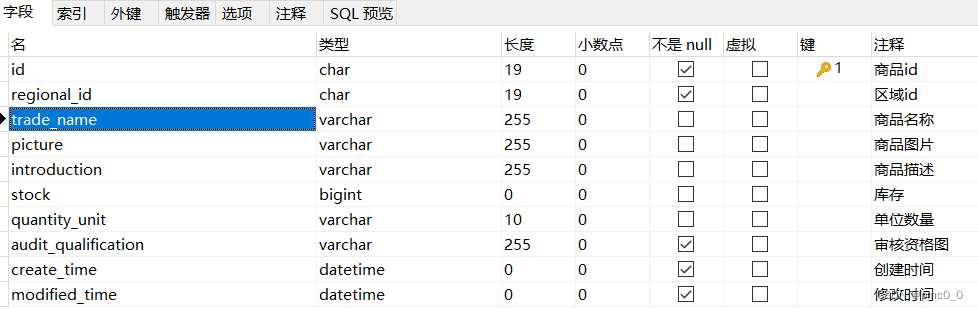
mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
- 文档(document)
Elasticsearch中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数据。
- 倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表。
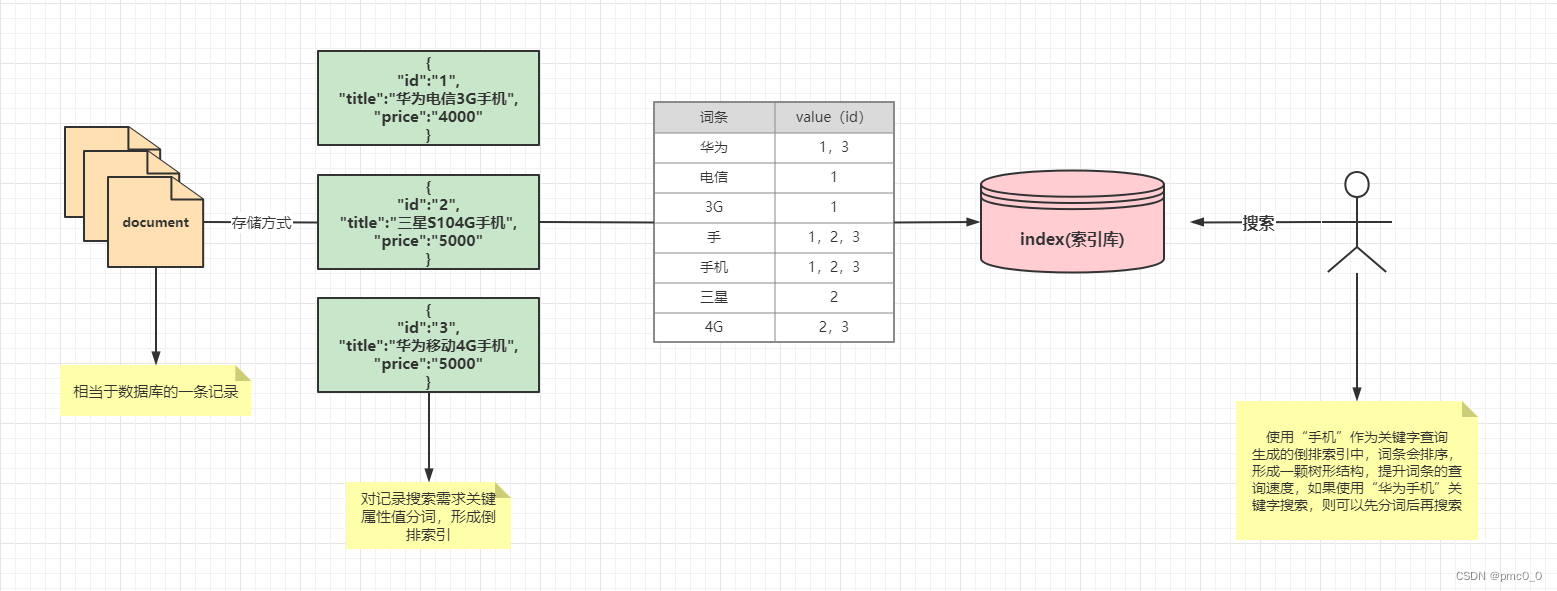
数据存储和搜索原理
- 倒排索引:将各个文档中的内容,进行分词,形成词条。然后记录词条和数据的唯一标识(id)的对应关系,形成的产物。
ElasticSearch目录
| 目录名称 | 描述 |
|---|---|
| bin | 可执行脚本文件,包括启动elasticsearch服务、插件管理、函数命令等 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等 |
| lib | elasticsearch所依赖的java库 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境要求必须修改 |
| logs | 默认的日志文件存储路径,生产环境务必修改 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等 |
| plugins | 已经安装的插件的目录 |
| jdk/jdk.app | 7.0以后才有,自带的java环境 |
分词器
分词器(Analyzer)∶将一段文本,按照一定逻辑,分析成多个词语的一种工具,如:华为手机—>华为、手、手机,ES默认的分词器对中文不友好,要用相关的分词器IK
- 直接去GitHub找到对应版本(如果是源码则需要Maven编译)直接下载后解压到ES下的plugins目录中自己新建的文件夹(可以起名analysis-ik),再将解压后的config目录内的所有文件复制到ES目录下的config,重启ES后可以看到相关信息

操作ES
JavaAPI方式一般操作文档,而索引和映射通过脚本操作,只做部分介绍
索引操作
# 添加索引 person_index为索引名,命令行是在kibana控制台操作
PUT person_index
# 查询索引
GET person_index
# 删除索引
DELETE person_index
# 关闭索引
POST person_index/_close
# 打开索引
POST person_index/_open
映射操作
字符串
- text:会分词,不支持聚合
- keyword:不会分词,将全部
数值
- long
- integer
- short
布尔
范围类型
- integer_range
- float_range
日期
- date
数值
- []
对象
- {}
# 添加映射,person是索引名
PUT person/_mapping
{
"properties":{
"name":{
"type":"keyword"
},
"age":{
"type":"integer"
}
}
}
# 查询影视
GET person/_mapping
文档操作
- 整合SpringBoot
@Configuration
public class EsConfig {
@Bean
public RestHighLevelClient getRestHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(
new HttpHost(
"127.0.0.1",
9200,
"http"
)
));
}
}
package cn.edu.guet.es;
import cn.edu.guet.es.pojo.Person;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
/**
* @author pangjian
* @ClassName Test
* @Description TODO
* @date 2022/6/23 18:22
*/
@SpringBootTest
@RunWith(SpringRunner.class)
public class EsTest {
@Autowired
private RestHighLevelClient client;
@Test
public void contextLoads() {
System.out.println(client);
}
/**
* @Description:添加文档,id存在则修改文档
* @return void
* @date 2022/6/23 19:18
*/
@Test
public void addOrUpdateDoc() throws IOException {
Person person = new Person();
person.setId("2");
person.setAge(23);
person.setName("小潘");
String data = JSON.toJSONString(person);
// 获取操作文档对象,文档存储肯定是基于某一个索引
IndexRequest request = new IndexRequest("person").id(person.getId()).source(data, XContentType.JSON);
// 添加数据
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 打印结果
System.out.println(response.getId());
}
}
批量操作
Bulk批量操作是将文档的增删改查一次请求全部做完。
@Test
public void testBulk() throws IOException {
// 创建bulk请求对象,整合所有操作
BulkRequest bulkRequest = new BulkRequest();
// 添加7号记录
Map map = new HashMap();
map.put("name", "3");
map.put("age", 4);
IndexRequest indexRequest = new IndexRequest("person").id("7").source(map);
bulkRequest.add(indexRequest);
// 修改7号记录
Map map1 = new HashMap();
map.put("name", "4");
UpdateRequest updateRequest = new UpdateRequest("person", "7").doc(map);
bulkRequest.add(updateRequest);
// 删除2号文档
DeleteRequest deleteRequest = new DeleteRequest("person", "2");
bulkRequest.add(deleteRequest);
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println(status);
}
导入数据
将库存表数据存入ES索引库
@Test
public void importData() throws IOException {
QueryWrapper<Commodity> wrapper = new QueryWrapper<>();
List<Commodity> commodityList = commodityMapper.selectList(wrapper);
BulkRequest bulkRequest = new BulkRequest();
for(Commodity commodity : commodityList) {
IndexRequest indexRequest = new IndexRequest("commodity");
indexRequest.id(commodity.getId()).source(JSON.toJSONString(commodity), XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println(status);
}
查询
查询所有
// 查询所有数据,要分页
@Test
public void getAllByPage() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
词条不分词等值查询
词条查询,查询的条件字符串和词条完全匹配,如下面查询口罩则会出行两条记录,如果查询防疫一次性医用口罩则只会查询到一条(如果你导入数据时候对导入数据是keyword类型的话,如果是text类型,则不会查询出数据,因为text分词了,索引库存的没有防疫一次性医用口罩这个词条),因为词条查询不会对搜索的字符串进行分词
// 词条查询
@Test
public void getTermQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.termQuery("tradeName", "口罩");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
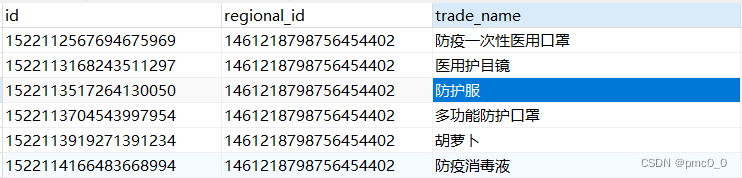
结果查询出两条数据,一条是多功能防护口罩,一条是防疫一次性医用口罩
match分词等值查询
会首先将搜索字符串进行分词后再和索引库里面的词条进行等值查询
// match查询
@Test
public void getMatchQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.matchQuery("tradeName", "多功能防护口罩");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
用“多功能防护口罩”作为搜索字符串进行match查询,得到两条数据,因为match查询会先将搜索字符串分词后再进行搜索
分词模糊查询
会首先将搜索字符串进行分词后再和索引库里面的词条进行模糊查询。如果查询“口”字,并不会查询到数据,因为IK分词器并不会把“口罩”关键字再分词后存入索引库,所以当我们用match等值查询时并不会有相关数据命中,我们需求要有“口罩”被查询出来,这时候就要用模糊查询了,模糊查询不要*号开头,否则性能低
- wildcard查询:会对查询条件进行分词。还可以使用通配符?(单个字符)和*(0或多个字符)
- regexp查询:正则查询
- prefix查询:前缀查询
@Test
public void getWildCardQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("tradeName", "口?");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
查询到两条记录
@Test
public void getPrefixQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.prefixQuery("tradeName", "口");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
以“口”字和索引库中“口”字为前缀得词条进行匹配查询
范围查询
@Test
public void getRangeQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery("stock");
// 指定上下限制
queryBuilder.gte(5000);
queryBuilder.lte(20000);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 排序
searchSourceBuilder.sort("stock", SortOrder.DESC);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
queryString查询
会对搜索字符串分词后,和多个查询字段进行词条等值匹配,也就是搜索口罩,可以根据商品名称匹配,也可以对商品描述进行匹配
@Test
public void getStrQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("口罩").field("tradeName").field("introduction");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 排序
searchSourceBuilder.sort("stock", SortOrder.DESC);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
布尔查询
对多个查询条件连接,连接方式,比如我们要搜索小米品牌的口罩,有两个字段和两个搜索字符串,要把小米品牌的商品和口罩商品进行一个条件拼接,如果最后得到小米品牌得口罩就可以用must
- must:条件必须成立
- must_not:条件必须不成立
- should:条件可以成立
- filter:条件必须成立,性能比must高,因为不会计算得分(得分是数据的匹配度)
// 布尔查询
@Test
public void getBooleanQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询条件
QueryBuilder queryBuilder1 = QueryBuilders.matchQuery("tradeName", "口罩");
QueryBuilder queryBuilder2 = QueryBuilders.matchQuery("introduction", "口罩");
// 拼接条件
BoolQueryBuilder queryBuilder = new BoolQueryBuilder();
queryBuilder.must(queryBuilder1).must(queryBuilder2);
searchSourceBuilder.query(queryBuilder);
// 分页,从0开始,查3条数据
searchSourceBuilder.from(0);
searchSourceBuilder.size(3);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}
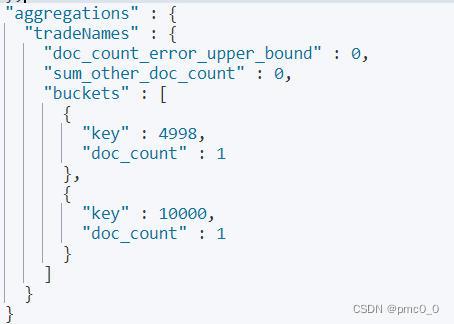
聚合查询
- 指标聚合:相当于max,min
- 桶聚合:相当于group by,不能对text类型数据进行分组
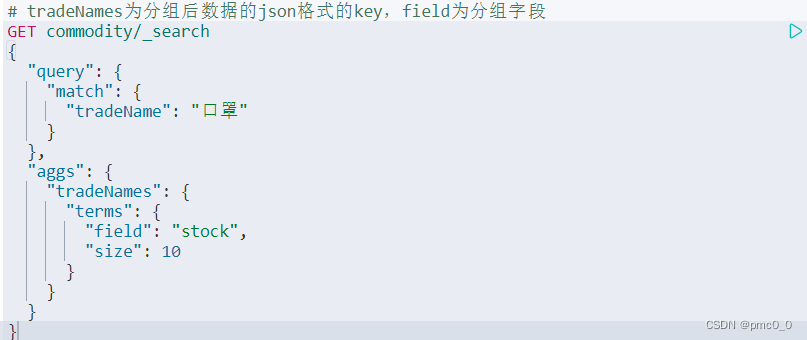
上面就是查询商品名为口罩的商品,然后根据库存去分组,库存相同的口罩会被分到一组里面。以后可以先查询手机,查询到的手机根据品牌去分组,这是一个适用场景。
@Test
public void getAggQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.matchQuery("tradeName", "口罩");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 分组,按照库存进行分组,第一个参数是自定义字段,之后的结果会包装在这一个key里面,值为结果
AggregationBuilder aggregationBuilder = AggregationBuilders.terms("tradeNames").field("stock").size(5);
searchSourceBuilder.aggregation(aggregationBuilder);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
// 获取聚合对象,难点,在于怎么取出想要的数据
Aggregations aggregations = searchResponse.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
Terms regional = (Terms) aggregationMap.get("tradeNames");
List<? extends Terms.Bucket> buckets = regional.getBuckets();
List regionalList = new ArrayList();
for (Terms.Bucket bucket : buckets ) {
Object o = bucket.getKey();
regionalList.add(o);
}
}
高亮查询
其实就是对搜索字段进行一个前后缀拼接,让html效果在浏览器上呈现颜色高亮
@Test
public void getHighQuery() throws IOException {
// 构建查询请求对象,指定索引库
SearchRequest search = new SearchRequest("commodity");
// 构建查询条件
QueryBuilder queryBuilder = QueryBuilders.matchQuery("tradeName", "口罩");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(queryBuilder);
// 设置高亮字段,也就是口罩两个字,再设置前缀后缀,这个可以自定义实现,这里用了html去显示高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("tradeName");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);
// 添加条件到请求中
search.source(searchSourceBuilder);
// 获取查询结果
SearchResponse searchResponse = client.search(search, RequestOptions.DEFAULT);
// 获取命中对象
SearchHits hits = searchResponse.getHits();
// 命中总记录数
long totalHits = hits.getTotalHits().value;
// 获取查询到的数据
final SearchHit[] searchHits = hits.getHits();
List<Commodity> commodityList = new ArrayList<>();
for (SearchHit searchHit : searchHits) {
String sourceAsString = searchHit.getSourceAsString();
Commodity commodity = JSON.parseObject(sourceAsString, Commodity.class);
// 将高亮字段替换查询结果的字段
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
HighlightField title = highlightFields.get("tradeName");
Text[] fragments = title.fragments();
commodity.setTradeName(fragments[0].toString());
commodityList.add(commodity);
}
System.out.println(commodityList);
System.out.println(totalHits);
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









