







EM算法的全称是期望极大算法(expectation maximization algorithm,EM),它的本质还是建立在极大似然估计上,经常运用在非监督学习的学习算法之中。
EM算法的特点是它非常适用于含有潜在变量的数据。但是什么算是潜在变量呢?举个例子,A和B去饭店吃饭,点了一堆菜和酒水,一共花了500元,这里吃饭的人和花了多少钱都是明确的变量,但是点了什么菜和酒水就是潜在变量了。
下面借助网上搜到的例子,直观上阐述一下算法的原理:
例:假定有A,B两种硬币,投掷它们出现正反的概率是不同的(可能A的正面概率是0.4,B的正面概率是0.3)。现在随机挑一个硬币,连续抛5次,记录下出现正反面的结果;然后再随机挑一个硬币....重复这样的工作5次,一共得到了5组数据。现在该如何根据实验结果估计A和B出现正面的概率?
这个例子中,随机挑的硬币到底是A还是B成了解决问题的关键,而这个关键也正是我们之前提到的潜在变量(我们所不知道的变量)。EM算法解决这个问题的思路是:
1.先假设出A的正面概率为x,B的正面概率为y,至于该如何假设,实际应用中常常是由别的算法给出的。
2.对每一组数据,根据1中假设的概率,计算这组数据的期望(在这个问题中,就是判断由假设的概率来分析抛硬币的结果,我们该更倾向于认为是抛了A还是抛了B)。计算完之后,我们就消除了潜在变量(因为我们通过期望的计算已经做出了假设)。
3.通过第二步,把这个含有潜在变量的问题转化成了普通的参数估计问题。我们只要对得到的数据采用极大似然估计,就能估计出一个新的A的正面概率x和B的正面概率y。
4.不断重复前三步,直到计算结果收敛或者两次循环之差小于你规定的阈值。
数学上可以证明,这个方法是收敛的。
现在举一个EM算法的具体应用——高斯混合模型(Gaussian mixture model,GMM)
GMM算法假设所有的样本是由K个不同的高斯分布所形成的(其中的K的值是靠人工设置的),我们只要找到每个样本所对应的高斯分布,就相当于完成了对这个样本的聚类(所有的样本会被分成K类)。因此,GMM的算法达到的目的是:1.对所样本的点聚类。2.计算出不同的样本对应的K个高斯分布的参数。高斯混合模型的概率密度如下所示:
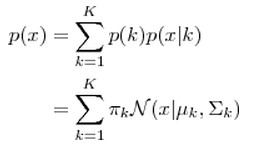
根据上面的式子,如果我们要从 GMM 的分布中随机地取一个点的话,实际上可以分为两步:首先随机地在这 K 个高斯分布之中选一个,每个高斯分布被选中的概率实际上就是它的系数  ,选中了这个高斯分布之后,再单独地考虑从这个高斯分布中选取一个点就可以了。
,选中了这个高斯分布之后,再单独地考虑从这个高斯分布中选取一个点就可以了。
假设我们已经知道了每个样本对应的类别,那么GMM中K个不同高斯分布的参数可以直利用极大似然估计求得。但是,实际问题中,样本的类别往往是未知的,这时计算GMM就需要用要EM算法的思想。
1.我们先假设所有的系数以及高斯混合模型中所有的高斯分布的参数即 和
和  。
。
2.利用假设的参数计算出样本由每个高斯分布所生成的概率。对于每个样本  来说,它由第 K个高斯分布生成的概率为
来说,它由第 K个高斯分布生成的概率为
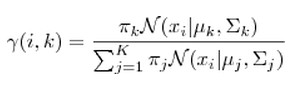
3.第二步的计算结果") 可以理解成第K个高斯分布在形成第i个样本时,所做的贡献(其实就是在给定观测数据和当前估计的参数的条件下,估计未关测数据的期望)。那么实际上可以看作这些高斯分布生成了
可以理解成第K个高斯分布在形成第i个样本时,所做的贡献(其实就是在给定观测数据和当前估计的参数的条件下,估计未关测数据的期望)。那么实际上可以看作这些高斯分布生成了x_1, \ldots, \gamma(N, k)x_N") 这些点,于是就可以用极大似然估计去, 和 (极大化未关测数据的期望)。
这些点,于是就可以用极大似然估计去, 和 (极大化未关测数据的期望)。

4.用新生成的参数去迭代,重复2,3步直到收敛。















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









