







在help文档中查看方法的参数时:
- 在'/'之前的参数都是位置参数
- 在'/'与'*'之间的参数可以被用作位置参数和关键字参数
- 在'*'之后的参数只能是关键字参数
我们可以使用dir(__builtin__)查看内建库中的所有方法[从abs到zip])
dir(__builtin__)目录
1.2 如果迭代器中有一个布尔值为True的元素则返回True any()
1.3 若字符在ascii码中返回该字符本身,若不在ACSII中则返回其他编码 ascii()
1.4 显示Python版权与致谢 copyright()与credits()
1.6 返回当前运行的ipynb对象 get_ipython()
1.10 给指定对象创建一个memoryview对象 memoryview()
2.8 将变量转换为classmethod类型 classmethod()
2.21 将变量转变为不可变的无需集合 frozenset()
2.31 判断对象1是否为对象2的子类 issubclass()
2.52 将方法转变为静态方法 staticmethod()
1 不常用的
1.1 如果迭代器中没有负值则返回True all()

#all()如果迭代器中所有数值为True则返回True
a = [1,2]
b = all(a)
print(b)
a = [0,1,2]
b = all(a)
print(b)
#如果迭代器为空返回True
a = []
b = all(a)
print(b)![]()
1.2 如果迭代器中有一个布尔值为True的元素则返回True any()

#any()如果迭代器中有任意值的布尔量为True则返回True
a = [0,1,2]
b = any(a)
print(b)
#如果为空则返回False
a = []
b = any(a)
print(b)![]()
1.3 若字符在ascii码中返回该字符本身,若不在ACSII中则返回其他编码 ascii()

#ascii()若字符在ascii码中返回该字符本身,若不在ACSII中则返回其他编码
a = '🔫'
b = ascii(a)
print(b)
a = 'A'
b = ascii(a)
print(b)![]()
1.4 显示Python版权与致谢 copyright()与credits()
这两个方法,还有下面的license方法在帮助文档中的解释是一样的
- copyright()
![]()
- credits()
![]()
#copyright()显示版权所有
copyright()
print(82*'*')
#credits()致谢
credits()
1.5 使用指定方法过滤元素 filter()

#filter()过滤出迭代器中符合要求的元素并返回变量类型为filter
def filt(n):
return n % 2 == 0
b = range(0,20)
c = filter(filt,b)
print(c)
print(type(c))
for i in c:
print(i)
1.6 返回当前运行的ipynb对象 get_ipython()
- 此方法是jupyter notebook独有方法,在Pycharm中无法使用

get_ipython()![]()
1.7 返回已存在的所有全局变量 globals()
- 与关键字的global用法不同,与关键字global配合使用

global 二零二零
a = 1
b = globals()
print(b)
1.8 返回版权 license()
![]()
a = 1
b = license()
print(b)![]()
1.9 查看已存在的本地变量 locals()

你好吗 = 1243
b = locals()
print(b)
1.10 给指定对象创建一个memoryview对象 memoryview()
![]()
#给定对象形式只能为与字节类型相似的变量
a = 'hello world'
b = bytearray(a,'utf-8')
c = memoryview(b)
print(c)
for n in range(0,5):
print(c[n])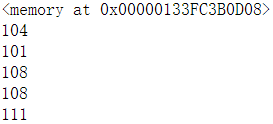
1.11 返回object对象 object()

#object为最基本的类型,object()为返回object类型
a = object()
print(a)![]()
1.12 返回property对象 property()
可以在property对象中获取,设置,删除,属性值

class a:
age = 18
b = property(a)
print(b)![]()
2 常用的
2.1 返回变量绝对值 abs()

#abs()返回变量绝对值
a = -1
b = abs(a)
print(b)![]()
2.2 将变量转换为二进制 bin()

#bin()将变量转换为二进制
a = 2
b = bin(a)
print(b)![]()
2.3 将变量转换为布尔量 bool()

#bool()将变量转换为bool量
a = 1
b = bool(a)
print(b)![]()
2.4 将变量转换为字节数组 bytearray()

#bytearray()将变量转换为字节数组
a = 1
b = bytearray(a)
print(b)![]()
2.5 将变量转变为bytes形式 bytes

#bytes()将变量转换为字节
a = 1
b = bytes(a)
print(b)
print(type(b))![]()
2.6 查看变量是否可调用 callable()
- 调用这个词不是很准确,在这里我们称方法或者类是可调用的,一个普通变量是不可调用的

#callable()如果变量可调用则返回True
a = 0
b = callable(a)
print(b)
def function():
print(1)
c = callable(function)
print(c)
class apple():
pass
d = callable(apple)
print(d)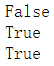
2.7 返回值对应的ascii字符 chr()

#chr()参数为ASCII字符对应的值,返回ASCII字符
a = 100
b = chr(a)
print(b)![]()
2.8 将变量转换为classmethod类型 classmethod()

#classmethod()返回变量类型为classmethod
a = 1
b = classmethod(a)
print(b)
print(type(b))![]()
2.9 编译 compile()

compile() 函数将一个字符串编译为字节代码。
参数顺序如下
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
必选参数
- source -- 在函数中为需要编译的对象,变量类型为字符串
- filename -- 可以为文件的路径,也可以为任意字符,当编译出现报错时会出现filename的内容,这个就是一个备注信息,可以设置为任意值
- mode -- 指定编译代码的种类。可以指定为 exec, eval, single。如果source为单个表达式则使用eval,如果source为语句块则用exec,如果source为单个交互式语句则用single
我现在想编译一个单个表达式 3 * 5
a = '3 * 5'
b = compile(a,'wrong_information','eval')
print(b)![]()
我现在像编译一个语句块
a = '15'
b = compile(a,'wrong_information','exec')
print(b)![]()
交互式语句:在控制台上执行的Python语句就叫交互式语句,我们可以在Anaconda Prompt上写

默认参数:
- flags 默认为0
- dont_inherit 默认为False
- optimize 默认为-1
可选参数flags和dont_inherit是用来控制编译源码时的标志,可以查看PEP236文档来了解这些参数,以及相关编译的说明。如果两者使用缺省参数(也即两者都是零值),在调用本函数编译时,主要使用代码中指明的编译特征来对待;如果flags参数设置有值,而dont_inherit没有设置(即是零值),那么编译代码时,不仅源码的编译特征起作用,而且flags指明的特征也起作用,相当两者的并集;如果参数dont_inherit设置有值(即是非零值),编译语句时只有参数flags指明的编译特征值起作用,即是不使用源码里指明的特征。
可选参数optimize是用来指明编译器使用优化的等级;缺省值是-1,表示使用命令行参数-O中获取的优化等级为准;如果设置值为0(即是不用优化,debug是设置true),是没有优化;如果设置值为1,assert语句被删除,debug设置为false;如果设置值为2,除了设置值为1的功能之外,还会把代码里文档说明也删除掉,达到最佳优化结果。
————————————————
版权声明:本文为CSDN博主「caimouse」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
2.10 返回变量复数形式 complex()
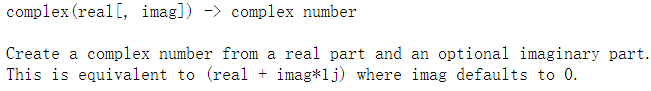
#complex()返回变量复数形式
a = 1
b = complex(a)
print(b)
print(type(b))![]()
2.11 删除属性 delattr()

#delattr()删除object属性
class a():
age = 18
b = a.age
print(b)
c = delattr(a,'age')
d = a.age
print(d)
2.12 生成字典 dict()

#dict()生成字典
a = {'one':1,'two':2,'three':3}
b = dict(a)
print(b)![]()
2.13 显示变量所有属性 dir()

#dir()显示变量的所有属性
class a():
age = 18
name = 'Suyu'
b = dir(a)
print(b)
2.14 显示对象 display()



display函数在help文档中写的很详细,我没有在上面展示help文档中的所有内容,help文档中有例子,现在我们看一下help文档中的内容
先看一下文档中对此函数的介绍
在所有前端显示Python对象。 默认情况下,所有表示都将被计算并发送到前端。 前端可以决定使用哪种表示法以及如何使用。 在终端IPython中,这将类似于使用:func:
display的参数如下
display(*objs, include=None, exclude=None, metadata=None, transient=None, display_id=None, **kwargs)
display函数没有必选参数,所以我们可以无参数调用,就是会什么也不显示,那此处是与Print()函数的一个区别,当空调用时print()默认尾缀是/n
obj 可显示若干变量
a = 'hello'
b = 1
c = 1.5
d = [1,2,3]
e = (1,2,3)
f = {'one':1,'two':2}
display(a,b,c,d,e,f)
raw
要显示的对象是否已经模拟键入了原始显示数据的dict,
或者在显示之前需要格式化的Python对象[默认值:False]
这个是一个布尔量,上面两行是文档的内容,但是在参数中我并没有看见raw

默认raw的值为False,现在改为True也能运行,但是看不见了
其余参数就不一一展示了,等我在项目中遇到合适的例子再丰富display其余参数的内容
2.15 变量相除 divmod()
![]()
#divmod()返回一个元组,第一个元素为商,第二个元素为余数
a = 10
b = 3
c = divmod(a,b)
print(c)![]()
2.16 变量枚举 enumerate()

#enumerate()返回变量类型为enumerate,将每个变量给个标号形成元组
a = ('zero','one','two')
b = enumerate(a)
print(type(b))
for c in b:
print(c)
print(type(c))
a = ['zero','one','two']
b = enumerate(a)
print(type(b))
for c in b:
print(c)
print(type(c))
2.17 变量评估后转换为最合适的变量 eval()

#eval()联系globals与locals结合给定的资源进行评估
#第一个参数source,其类型必须为str,bytes或code object
#eval()会估计出变量类型并返回
a = 'hello'
hello = 'good morning'
E = eval(a)
print(type(E))
print(E)
b = 1
c = 1.5
d = [1,2,3]
e = (1,2,3)
f = {'one':1,'two':2}
for i in b,c,d,e,f:
j = str(i)
E = eval(j)
print(E)
print(type(E))
#source也可为表达式
E = eval('b+1.5')
print(E)
print(type(E))
#第二个参数globals与第三个参数locals默认为None
#globals必须为字典类型,locals可以为任意的映射
#变量优先级为locals>globals
one = 1
glo = {'one':2}
loc = {'one':3}
E = eval('one+1')
print(E)
E = eval('one+1',glo)
print(E)
E = eval('one+1',glo,loc)
print(E)
我在项目中有两个实际使用eval的案例,我们可以看一下
- 计算器逻辑实现
92.最后的综合案例_potato123232的博客-CSDN博客 中的4.2.3下图的位置

- opencv遍历不同的模板匹配方法
7.模板匹配_potato123232的博客-CSDN博客 中的2.1

2.18 把变量转换为合适的语句然后执行 exec()

a = 'print(3)'
b = exec(a)
print(b)![]()
a = '1'
b = exec(a)
print(b)![]()
def func():
print(2)
return 1
b = exec(func())
print(b)
- exec的参数必须是字符串,字节字节或代码对象
- exec的返回值永远为None
2.19 将变量转变为浮点型 float()
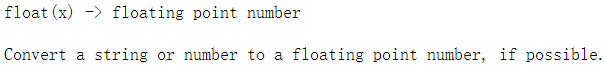
#float()返回float型变量
a = 1
b = float(a)
print(b)
print(type(b))![]()
2.20 将变量转变为指定格式 format()

#format()使用方式不同于.format,format()函数返回变量的指定形式
a = 2
b = format(a,'b')
print(b)![]()
2.21 将变量转变为不可变的无需集合 frozenset()
![]()
#frozenset()构建唯一元素不可变无序集合(冻结迭代器)
a = [1,1,2,3,4]
b = frozenset(a)
print(b)
print(type(b))![]()
2.22 获取对象属性 getattr()

#getattr()获取对象的属性,第一个参数为对象,第二个参数为属性名称
class a:
age = 18
b = getattr(a,'age')
print(b)![]()
2.23 判断类中是否有指定属性 hasattr()

#hasattr()如果对象中有指定属性返回True,否则返回False
class a:
age = 18
gender = 'Male'
name = 'Suyu'
b = hasattr(a,'age')
print(b)
c = hasattr(a,'school')
print(c)![]()
2.24 返回变量哈希值 hash()

#hash()返回变量的哈希值,哈希值相同则变量相同
a = 10
b = hash(a)
print(b)
c = 10
d = hash(c)
print(d)![]()
2.25 查看帮助文档 help()

#help()参数为方法,返回该方法的使用信息
a = help(eval)
print(a)
print(type(a))
2.26 返回变量16进制的值 hex()

#hex()参数为整形,返回变量的hex值
a = 10
b = hex(a)
print(b)![]()
2.27 查看变量的标识 id()

#id()返回变量的标识,标识相同则变量相同
a = 1
b = id(a)
print(b)
c = 1
d = id(c)
print(d)![]()
2.28 让用户输入一段字符串 input()

#input()输入字符并返回字符,参数为提示内容
a = input('输入值')
print(a)
print(type(a))![]()

2.29 返回变量整形形式 int()

#int()返回变量整形形式
a = '1'
b = int(a)
print(b)
print(type(b))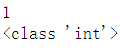
2.30 判断变量是否为指定类型 isinstance()

#isinstance()查看变量是否为指定类型,若是返回True,若不是返回False
a = 1
b = isinstance(1,str)
print(b)![]()
2.31 判断对象1是否为对象2的子类 issubclass()

#issubclass()判断1号参数是否为2号参数的子类
class father():
pass
class child(father):
pass
a = issubclass(father,child)
print(a)
b = issubclass(child,father)
print(b)
2.32 生成迭代器 iter()

#iter()生成迭代器
a = [1,2,3]
b = iter(a)
print(b)
print(type(b))
for i in b:
print(i)
2.33 返回迭代器中的元素数量 len()
![]()
#len()返回变量长度
a = ('hello',(1,2,3),[1,2,3,4],{'age':18})
for i in a:
b = len(i)
print(b)![]()
2.34 将变量转换为列表 list()
![]()
#list()生成列表
a = 1,2,3,4
b = list(a)
print(b)
print(type(b))![]()
2.35 让两组迭代器做为两个变量同时参与运算 map()

#map()执行定义的函数,当最短列表使用完之后结束
def a(n,m):
return n + m
f = map(a,[1,2],[77,777,7777])
print(f)
for i in f:
print(i)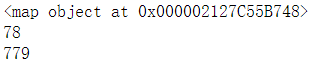
我们有的时候使用map来传递参数,下面是我项目中的一个例子
![]()
park是我们实例化后的工具类,select_rgb_white_yellow是工具类中的一个方法,此时我们就将上图的test_imges作为select_rgb_white_yellow的参数image传了进来

2.36 获取指定内容中的最大值 max()

#max()不加入其他参数时返回变量中的最大值
a = [1,2,3,4,5,6,7]
c = max(a)
print(c)
#可选参数为key,key代替max的方法
#例子为返回小于7的第一个值
def b(n):
return n < 7
c = max(a,key = b)
print(c)
#如不满足key的条件,返回变量的第一个值
def b(n):
return n > 8
c = max(a,key = b)
print(c)
#另一个可选参数为默认值,当迭代器为空时返回该值
a = []
c = max(a,default = 9,key = b )
print(c)![]()
2.37 获取指定内容中的最小值 min()

a = 1,2,3,4,5
b = min(a)
print(b)
def c(n):
return n < 5
b = min(a,key = c)
print(b)![]()
2.38 返回迭代器中下一个元素 next()

#next()从迭代器中返回变量
a = iter([1,2,3,4,5])
b = next(a)
print(b)
b = next(a)
print(b)
b = next(a)
print(b)
b = next(a)
print(b)
b = next(a)
print(b)
#如果迭代器读取完毕且给定默认值,默认值将代替提示的StopIteration
b = next(a,8)
print(b)![]()
2.39 返回变量的8进制值 oct()

#oct()将指定整型变量返回八进制
a = 8
b = oct(a)
print(b)
print(type(b))![]()
2.40 打开一个文件流 open()

#open()打开文件并返回一个流,失败时会引发IOerror
a = open('python_test.txt')
print(a)
print(type(a))
b = a.read()
print(b)
print(type(b))

#open()最常见的使用方法为:
with open('python_test.txt','r') as f:
print(f)
print(type(f))
a = f.read()
print(a)
print(type(a))
#这样就可以读出文本中的内容
2.41 返回一个字符在ascii码中对应的值 ord()
![]()
#返回变量Unicode编码对应的值,变量只能为一个字符
a = ord('a')
print(a)![]()
2.42 平方运算 pow()

#pow()平方运算,第一个参数为底数,第二个参数为指数
a = pow(2,3)
print(a)
#第三个参数为可选参数,为平方结果的除数,运算结果返回余数
a = pow(2,3,7)
print(a)![]()
2.43 打印一个值 print()

print()第一个参数为值,其余为可选关键字参数
sep 添加间隔字符
end 添加末尾字符,默认为换行符

后面两个参数可以将字符写入txt文件
file为指定的文件流,flush为是否强行介入流,如果flush为False则不会将字符写入
![]()

- 如果file没有在指定路径下,系统会自动创建一个你指定的文件,然后写进去
- 读取txt文件内容的方法在上面的open()中有提到
我们也可以使用with...as...写入一些东西,也有使用pickle(是一个库)进行写入的,使用pickle写入在我的这篇文章中有提到 16.停车场车位识别_potato123232的博客-CSDN博客
下面这个可以使用print来模拟进度条

2.44 生成有序整形数组 range()

#range()返回可迭代的range类变量,例中的变量内容为1-9
a = range(1,10)
print(a)
print(type(a))
for n in a:
print(n)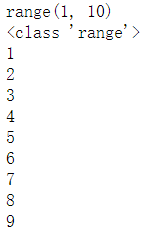
2.45 返回变量的字符串类型 repr

#repr()返回规范的字符串类型
a = 1
b = repr(a)
print(b)
print(type(b))![]()
2.46 使迭代器逆序 reversed()

#reversed()根据不同指定变量类型,返回不同的变量_reverseiterator类型
#如指定变量为list,则返回变量为list_reverseiterator
#返回变量可迭代,内容与指定变量顺序相反
a = [1,2,3,4,5]
b = reversed(a)
print(b)
print(type(b))
for n in b:
print(n)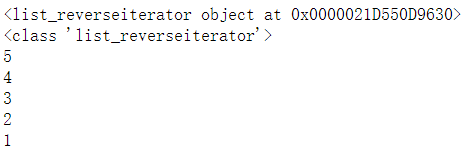
2.47 五舍六入 round()

#round()五舍六入讲变量变为指定形式
for a in range(0,11):
for b in range(0,10):
a = str(a)
b = str(b)
c = float(a + '.' + b)
print(c,round(c),end = '|')
#可规定小数位数,如有小数位数则返回float,如没有则返回int
#小数位数可以为负数,为负数时小数点向前指定位数
a = 12.11
for n in [1,-1]:
b = round(a,n)
print(b)
print(type(b))
print()
2.48 返回变量set形式 set()

#返回变量set形式
a = 1,2,3
b = set(a)
print(b)
print(type(b))![]()
2.49 给指定对象一个属性 setattr()

#setattr()给指定对象一个属性
class Suyu():
pass
setattr(Suyu,'age',18)
print(Suyu.age)![]()
2.50 迭代器切片 slice()
- 截取部分元素

#set类型不可以使用slice(),tuple与list类型可以使用
#slice()有两种使用方式
#第一种:slice(stop),截取从起始侧的指定元素
a = 1,2,3,4,5,6,7,8,9
print(a)
b = slice(5)
print(b)
print(type(b))
c = a[b]
print(c)
print(type(c))
print()
#第二种slice(start, stop[, step]),使用第一个参数start是不包含指定的元素
b = slice(3,5)
c = a[b]
print(c)
#参数step表示隔指定位一显示,例为隔两位
b = slice(1,8,2)
c = a[b]
print(c)
#参数start与step如不想使用时可用None代替
b = slice(None,8,2)
c = a[b]
print(c)
2.51 迭代器排序 sorted()

#sorted()生成一个新的列表,新的列表按指定顺序排序
#当只有参数iterable时,将指定迭代器进行排序
a = 3,5,7,8,3
b = sorted(a)
print(b)
#参数key为比较方法,默认为None,例中为比较元组列表中元组的第二个数值
def than(num):
return num[1]
a = ('小王',18),('小李',20),('小张',16)
b = sorted(a,key = than)
print(b)
#参数reverse为是否反向,默认为False,
b = sorted(a,key = than,reverse = True)
print(b)
2.52 将方法转变为静态方法 staticmethod()

def add_one(num):
num = num + 1
staticmethod(add_one)
a = 1
b = a.add_one
print(b)
2.53 返回变量字符串形式 str()

#str()返回变量字符串形式
a = 1
b = str(a)
print(a)![]()
2.54 求和 sum()

#sum()将列出的所有元素求和
a = 1,3,4,6
b = sum(a)
print(b)
#如果一个元素也没有列则返回参数start所设定的值
a = ()
b = sum(a,2)
print(b)![]()
2.55 继承父类的方法 super()

#super()继承父类方法
class father():
def father_func(self,x):
y = x + 1
print(y)
class child(father):
def child_func(self,x):
super().father_func(x)
son = child()
son.child_func(1)![]()
2.56 返回变量tuple形式 tuple()

#tuple()返回变量tuple形式
a = [1,2,3,4]
b = tuple(a)
print(b)
print(type(b))![]()
2.57 查看对象类型 type()

#type()返回对象的类型,返回类型为type
a = 1
b = type(a)
print(b)
print(type(b))
2.58 返回一个键值对,内容为类的属性 vars()

#vars()返回mappingproxy形式的变量,其中包含类的属性
class Suyu():
name = 'Suyu'
age = '18'
a = vars(Suyu)
print(a)
print(type(a))
b = Suyu()
c = vars(b)
print(c)
print(type(c))
2.59 打包成zip对象 zip()

#zip()将两个迭代器打包,返回变量类型为zip
a = ['one','two','three']
b = [1,2,3]
c = zip(a,b)
print(c)
print(type(c))
for n in c:
print(n)
我们如果遇到元组嵌套的时候我们可以选择匹配压缩或非匹配压缩
- 匹配压缩(加*)
a = ((1,2,3,4),(5,6,7,8))
for i in zip(*a):
print(i)
- 不匹配压缩
我们先正常遍历一遍
a = ((1,2,3,4),(5,6,7,8))
for i in a:
print(i)
下面是使用zip的结果
a = ((1,2,3,4),(5,6,7,8))
for i in zip(a):
print(i)![]()
zip最多的应用场景就是遍历两个可遍历的对象,比如我现在像找出来两个list中第一个不同的元素,那么我就可以把i与j进行比对
a = [1,2,3,4]
b = [1,2,5,7]
for i,j in zip(a,b):
print('i',i,'j',j)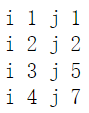
















 1775
1775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











