







RNN(循环神经网络)主要处理序列数据
LSTM就是循环神经网络,GRU也是一个循环神经网络
我们下面使用循环神经网络对航空评论数据集进行处理
航空评论数据集是这个名为Tweets的csv文件

我们打开看一下
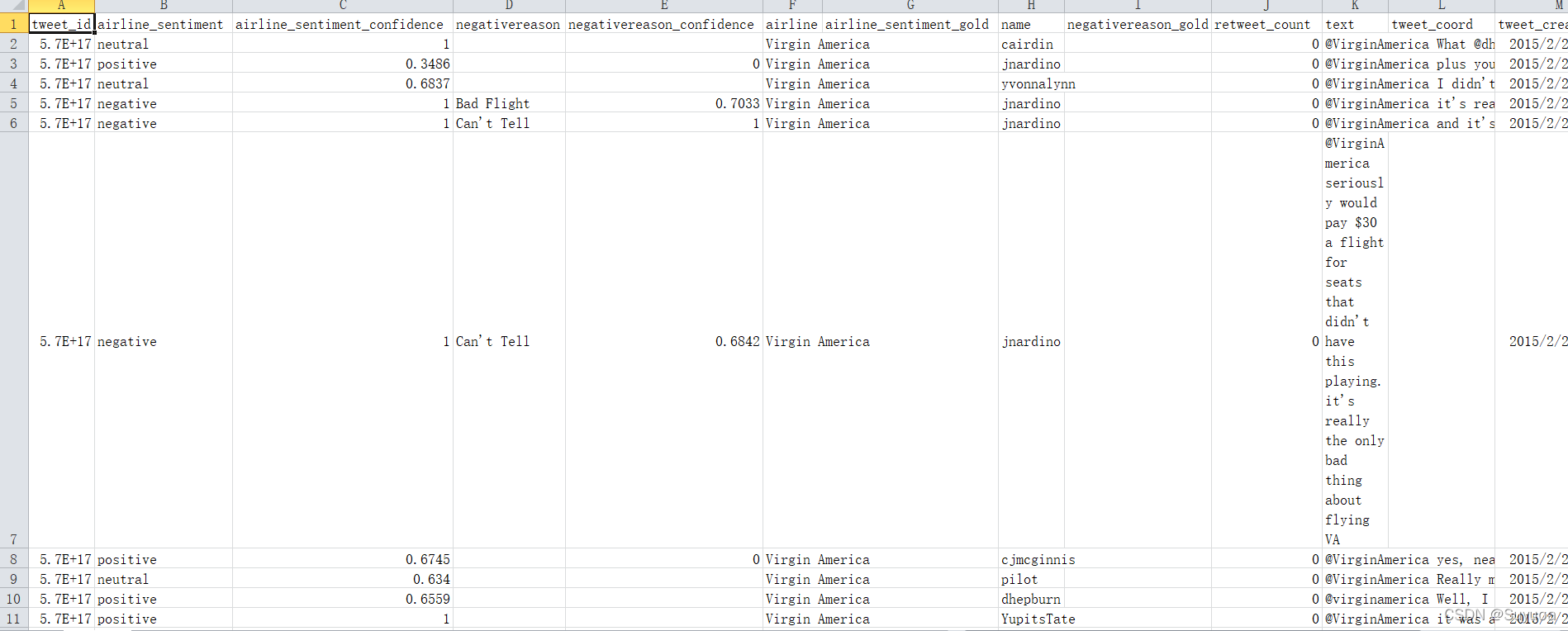
数据集是脱敏处理过的,他的内容包含下列部分
- tweet_id 推特id
- airline_sentiment 对航空公司的情绪(积极[postive],消极[negative],中性[neutral])
- airline_sentiment_confidence 该航班的评分,该值用浮点数进行表示
- negativereason 消极情绪的原因,这个是用户的留言,有的直接说是一次不好的飞行,有的说不能告诉你

- negativereason_confidence 消极情绪的程度
- airline 航空公司的名字,基本上都是Virgin America(维珍美国航空)
- airline_sentiment_gold 航空情绪金。这一列是空的
- name 这一列应该是推特的昵称
- retweet_count 转发数量
- text 文本

- tweet_coord 推特坐标,这个应该是经纬度那种

- tweet_created 发推特的时间
- tweet_location 推特位置

- 用户时区

我们使用上面提到的test与airline_sentiment,来预测一段评论是积极情绪还是消极情绪
下面是代码部分
目录
1 导入库
![]()
2 读取数据集
![]()
3 处理数据集
3.1 取出需要的两列
读取后我们取出airline_sentiment和test这两列
![]()
我们看一下现在的data
![]()
发现只有这两列内容了

我们用unique看一下是否在这一列只有三种值
![]()
发现只有这三种值
![]()
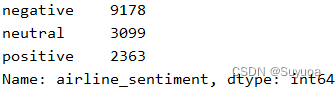
之后我们使用value_counts,看一下每个值的数量
![]()
发现消极评论居多,其次是中性,最后是好评
3.2 平衡积极与消极数据数量
我们在本次训练只判断是积极情绪或是消极情绪,现在我们需要保证数据的均衡,消极评论远大于积极评论是对训练结果有影响的,所以我们现在取出2363个消极评论与积极评论

- iloc是取该列的前若干行
这样我们积极数据与消极数据都是2363个了,现在我们把两种评论合起来
![]()
之后我们看一下data的shape
![]()
发现有4726行,2列
![]()
3.3 乱序数据集
我们现在使用sample对其进行乱序
![]()
3.4 处理 airline_sentiment
下面我们对数据集进行处理,我们用0表示negative,用1表示positive
![]()
现在data中就加入了attitude这一列,这一列的0是消极评论,1是积极评论,之后我们就可以把airline_sentiment删掉了
![]()
我们看一下当前的data
![]()

3.5 处理 text
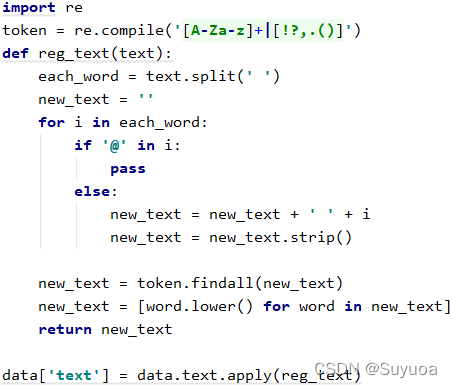
3.5.1 删去@内容,并将其正则化
这些@是字符是不影响评论是积极还是消极的,所以我们要把他消除掉

我在这里做个例子

这样就能得到消除了所有@内容的字符
![]()
之后我们再使用正则,提取字符A-Z,a-z,和另外六个字符,之后我们再将其赋值给data中的text
我们现在看一下data
![]()

发现前面是处理好的语句,后面是对应的态度
3.5.2 用一个数字代表评论中的每一个单词
我们先看一下评论有多少个英文单词(包括叹号这种符号)
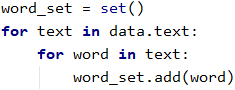
我们看一下当前word_set的长度,此处要加1,因为后面我们会把未正则的字符归到0
![]()
是6789个,由于每次随机的评论内容不同,所以单词量也会有所变化
![]()
之后我们给每一个单词一个索引值,之后做成一个字典,由于我们会有不在正则范围内的字符,我们将其归到索引0,所以我们在字典中从1开始索引,之后我们看一下word_dict

我们要给这里print出来的结果复制出来,之后预测的时候我们要用

然后我们把索引后的值给到一个新的变量data_comment


3.5.3 统一所有评论长度
我们首先找到最大评论的长度
![]()
![]()
之后我们把评论填充到longest_comment这样长
![]()
4 创建网络
Embedding的50是神经元个数,LSTM的64也是神经元个数,我们可以自定

我们看一下这个模型
![]()

5 编译模型
![]()
6 训练模型
![]()
- validation_split的意思是指定一部分数据作为测试数据,我当前使用的是0.2,也就是20%的数据作为测试数据
我们的数据量不大,速度很快,所以就不加入检查点了,只训练了10个epoch,我们直接看给出的结果就行了
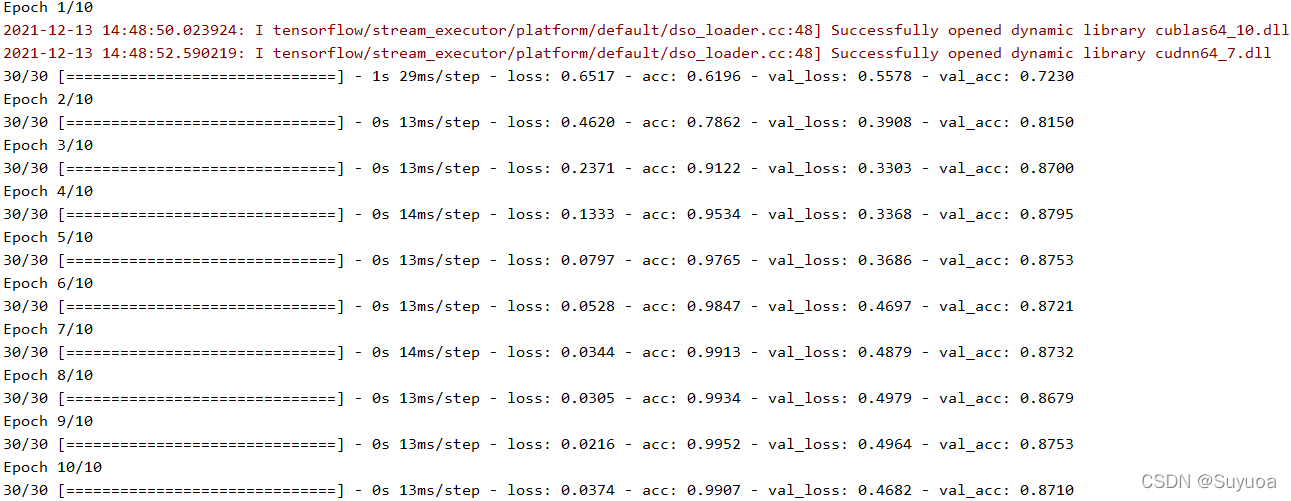
最终发现准确度是0.87左右,还能看
7 保存模型
![]()

8 预测模型


我们发现每一个词都有它的情感趋向,我们定义的是0为消极,1为积极
我们可以对这三个结果进行处理
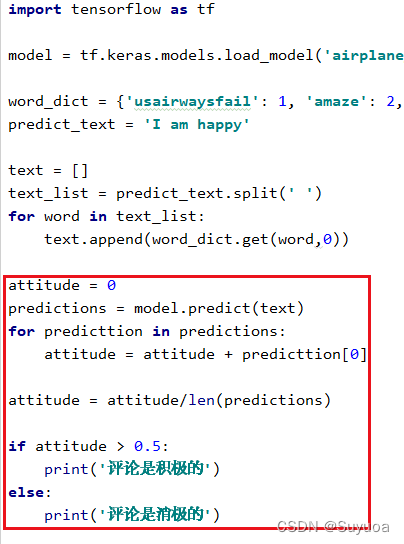
![]()
我们再加上not看一下
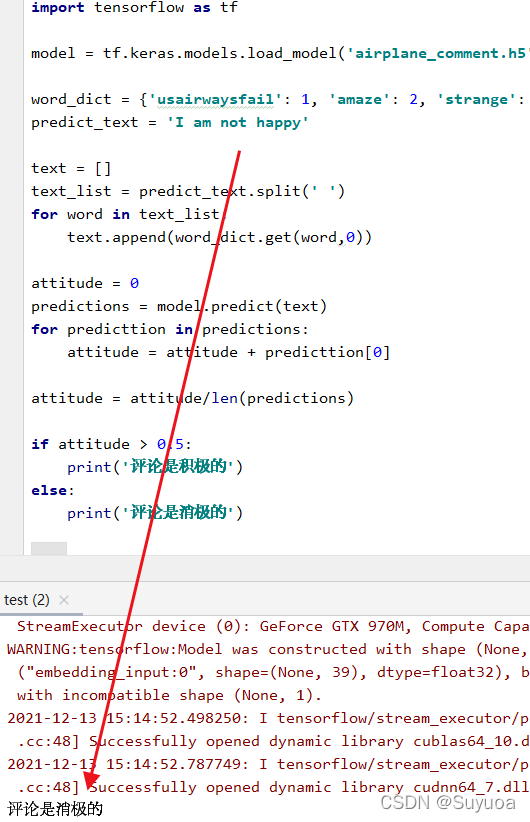


















 3660
3660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











