







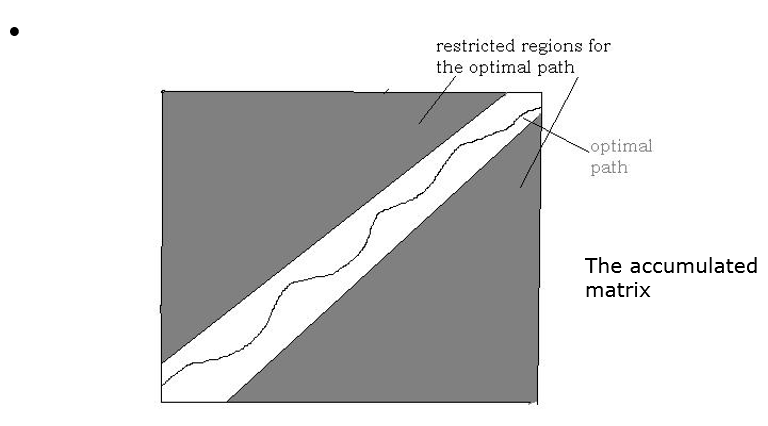
将AI课上学习的知识进行简单的整理,可以识别简单的0-9的单个语音。基本方法就是利用库函数提取mfcc,然后计算误差矩阵,再利用动态规划计算累积矩阵。并且限制了匹配路径的范围。具体的技术网上很多,不再细谈。
现有缺点就是输入的语音长度都是1s,如果不固定长度则识别效果变差。改进思路是提取有效语音部分。但是该部分尚未完全做好,只写了一个原形函数,尚未完善。

import wave
import numpy as np
import matplotlib.pyplot as plt
from python_speech_features import mfcc
from math import cos,sin,sqrt,pi
def read_file(file_name):
with wave.open(file_name,'r') as file:
params = file.getparams()
_, _, framerate, nframes = params[:4]
str_data = file.readframes(nframes)
wave_data = np.fromstring(str_data, dtype = np.short)
time = np.arange(0, nframes) * (1.0/framerate)
return wave_data, time
return index1,index2
def find_point(data):
count1,count2 = 0,0
for index,val in enumerate(data):
if count1 <40:
count1 = count1+1 if abs(val)> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 184
184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









