







ACNet是什么?
[1]X. Ding, Y. Guo, G. Ding etal.“ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks” in ICCV 2019
推荐博客:https://blog.csdn.net/practical_sharp/article/details/114671943
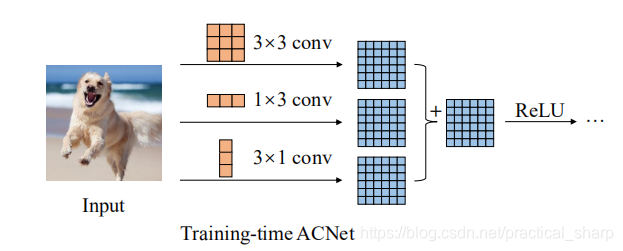
Overview of ACNet. For example, we replace every 3 × 3 layer with an ACB comprising three layers with 3 × 3, 1×3 and 3×1 kernels, respectively, and their outputs are summed up. When the training is completed, we convert the model back into the same structure as the original by adding the asymmetric kernels in each ACB onto the skeleton, which is the crisscross part of the square kernel, as marked on the figure. In practice, this conversion is implemented by building a new model with the original structure and using the converted learned parameters of the ACNet to initialize it.
总结来说ACnet就是非对称卷积,能够学习到更多特征,以ACNet构建的backbone能提高网络在 CIFAR-10, CIFAR-100, and ImageNet上的分类性能。
接下来我准备使用ACNet构造ResNet50的backbone来训练目标检测模型,测试一下模型能否存在性能提升问题。
import torch
from torch import nn as nn
# 去掉因为3x3卷积的padding多出来的行或者列
class CropLayer(nn.Module):
# E.g., (-1, 0) means this layer should crop the first and last rows of the feature map. And (0, -1) crops the first and last columns
def __init__(self, crop_set):
super(CropLayer, self).__init__()
self.rows_to_crop = - crop_set[0]
self.cols_to_crop = - crop_set[1]
assert self.rows_to_crop >= 0
assert self.cols_to_crop >= 0
def forward(self, input):
return input[:, :, self.rows_to_crop:-self.rows_to_crop, self.cols_to_crop:-self.cols_to_crop]
# 论文提出的3x3+1x3+3x1,其中3*3卷积还是由self.conv2来实现
# 实现一个AC卷积块只包含1*3和3*1这两个不对称卷积,这两个部分是没有与预训练权重的
# 使用这个模块的时候 padding必须先定义为 = 1
class ACBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(ACBlock, self).__init__()
self.deploy = deploy
if deploy:
self.fused_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(kernel_size,kernel_size), stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True, padding_mode=padding_mode)
else:
center_offset_from_origin_border = padding - kernel_size // 2
ver_pad_or_crop = (center_offset_from_origin_border + 1, center_offset_from_origin_border)
hor_pad_or_crop = (center_offset_from_origin_border, center_offset_from_origin_border + 1)
if center_offset_from_origin_border >= 0:
self.ver_conv_crop_layer = nn.Identity()
ver_conv_padding = ver_pad_or_crop
self.hor_conv_crop_layer = nn.Identity()
hor_conv_padding = hor_pad_or_crop
else:
self.ver_conv_crop_layer = CropLayer(crop_set=ver_pad_or_crop)
ver_conv_padding = (0, 0)
self.hor_conv_crop_layer = CropLayer(crop_set=hor_pad_or_crop)
hor_conv_padding = (0, 0)
self.ver_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 1),
stride=stride,
padding=ver_conv_padding, dilation=dilation, groups=groups, bias=False,
padding_mode=padding_mode)
self.hor_conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=(1, 3),
stride=stride,
padding=hor_conv_padding, dilation=dilation, groups=groups, bias=False,
padding_mode=padding_mode)
self.ver_bn = nn.BatchNorm2d(num_features=out_channels)
self.hor_bn = nn.BatchNorm2d(num_features=out_channels)
# forward function
def forward(self, input):
if self.deploy:
return self.fused_conv(input)
else:
# square_outputs = self.square_conv(input)
# square_outputs = self.square_bn(square_outputs)
# print(square_outputs.size())
vertical_outputs = self.ver_conv_crop_layer(input)
vertical_outputs = self.ver_conv(vertical_outputs)
vertical_outputs = self.ver_bn(vertical_outputs)
# print(vertical_outputs.size())
horizontal_outputs = self.hor_conv_crop_layer(input)
horizontal_outputs = self.hor_conv(horizontal_outputs)
horizontal_outputs = self.hor_bn(horizontal_outputs)
# print(horizontal_outputs.size())
return vertical_outputs + horizontal_outputs
# this is the original ResNet Block, uesing the ACBlock replace the 3*3 conv
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channel, out_channel, stride=1, downsample=None, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# 1*1 的卷积 不需要使用 ACBlock
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=1, stride=1, bias=False) # squeeze channels
self.bn1 = norm_layer(out_channel)
# -----------------------------------------
# 3*3 的卷积 需要使用 ACBlock
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size=3, stride=stride, bias=False, padding=1)
self.ACBlock = ACBlock(in_channels = out_channel,out_channels= out_channel,
kernel_size = 3, stride=stride, padding=1, dilation=1,
groups=1, padding_mode='zeros', deploy=False)
self.bn2 = norm_layer(out_channel)
# -----------------------------------------
# 1*1 的卷积 不需要使用 ACBlock
self.conv3 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel * self.expansion,
kernel_size=1, stride=1, bias=False) # unsqueeze channels
self.bn3 = norm_layer(out_channel * self.expansion)
self.relu = nn.ReLU(inplace=True)
# some ResNet Block maybe need downsample to decrease the size of feature map(usually 2X)
# the definition of downsample module in class ResNet
self.downsample = downsample
# original ResNet Block
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
square_outputs = self.conv2(out)
other_outputs = self.ACBlock(out)
out = square_outputs + other_outputs
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
x = torch.Tensor(8,3,256,256)
ac = ACBlock(in_channels = 3, out_channels = 64, kernel_size = 3, stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False)
print(ac)
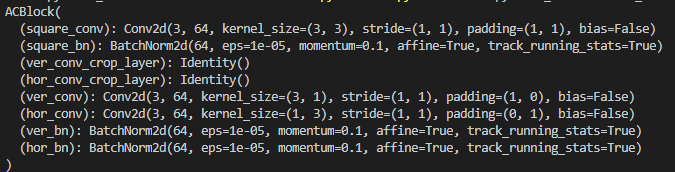
ACBlock的原本结构
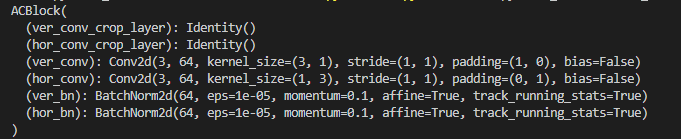
但是为了预训练权重方便,还是保留了BottleBlock的conv2,所以ACBBlock只剩下了13和31的预训练权重。
如何用ACBlock构建ResNet50,使用ACBlock这个类代替普通的3*3的卷积就好了
## 接上面的代码
## 完全不需要改变
class ResNet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000, include_top=True, norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.include_top = include_top
self.in_channel = 64
# 输入图像都是3个通道的,最开始进入ResNet的网络channel = 3
# 第一个卷积层也是一个下采样,stride = 2 会造成下采样X2
self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = norm_layer(self.in_channel)
self.relu = nn.ReLU(inplace=True)
# 池化层,会损失很多信息,stride = 2 会造成下采样X2
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) # 这里传入的stride = 2,需要下采样
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) # 这里传入的stride = 2,需要下采样
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) # 这里传入的stride = 2,需要下采样
# 图像分类需要有最后的全连接层,定义目标检测模型时候 self.include_top = False
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channel, block_num, stride=1):
norm_layer = self._norm_layer
downsample = None
# 如果需要下采样了,self.in_channel == channel * block.expansion就不满足了
if stride != 1 or self.in_channel != channel * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False),
norm_layer(channel * block.expansion))
# 先判断第一个block是否需要下采样
layers = []
layers.append(block(self.in_channel, channel, downsample=downsample,
stride=stride, norm_layer=norm_layer))
self.in_channel = channel * block.expansion
# 从1开始循环而不是从0开始循环
for _ in range(1, block_num):
layers.append(block(self.in_channel, channel, norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
# eg. x = torch.Tensor(8,3,256,256)
x = self.conv1(x)
# after the first conv,torch.Size([8, 64, 128, 128])
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
# after maxpooling :torch.Size([8, 64, 64, 64])
x = self.layer1(x)
# torch.Size([8, 256, 64, 64])
x = self.layer2(x)
# torch.Size([8, 512, 32, 32])
x = self.layer3(x)
# torch.Size([8, 1024, 16, 16])
x = self.layer4(x)
# torch.Size([8, 2048, 8, 8])
# object detection module need not this if sentence
if self.include_top:
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
"""
x = torch.Tensor(8,3,256,256)
net = ResNet(Bottleneck,[3,5,6,3],include_top=False)
print(net)
out = net(x)
print(out.size())
"""
具体的backbone在目标检测中是否有效果,还是等实验之后再来完善。
有一个疑问就是,这样定义卷积没有预训练模型,不知道是否如意。

















 3879
3879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









