






 本文详细阐述了YOLOv8的Pose检测模块及其在关键点检测中的应用,涉及代码移植、模型导出和C/C++接口的编写,以及实例分割功能的介绍。
本文详细阐述了YOLOv8的Pose检测模块及其在关键点检测中的应用,涉及代码移植、模型导出和C/C++接口的编写,以及实例分割功能的介绍。
YOLOv8关键点检测算法移植
YOLOv8关键点检测
YOLOv8的Pose检测头用于检测人体骨骼点,稍加改造可用于人脸检测、车牌定位等场景。
YOLOv8的Pose模型定义了检测头的缺省参数,模型定义文件位于ultralytics/cfg/models/v8/yolov8-pose.yaml
nc: 1 # number of classes
kpt_shape: [17, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
scales: # 省略
backbone: # 省略
head:
# 中间省略
- [[15, 18, 21], 1, Pose, [nc, kpt_shape]] # Pose(P3, P4, P5)
以上配置表示:
- 使用Pose网络头
- 类型数量nc为1:表示只检测一种类型
- 关键点数量为17,
- 对于数据集,每个关键点是三元组xyv,xy是关键点坐标(归一化),v表示关键点是否可见
- 对于预测结果,每个关键点是三元组xyc,xy是关键点坐标(归一化),c表示关键点置信度
Pose检测头的源代码位于文件ultralytics/nn/modules/head.py中的Pose类
类型定义class Pose(Detect)表示Pose检测头从Detect检测头继承得到,因此也有cv2和cv3分支:
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
其中cv2分支用于预测bounding box,cv3用于预测类型置信度
Pose检测头在Detect检测头的基础上增加cv4分支用于预测关键点
self.cv4 = nn.ModuleList(nn.Sequential(Conv(x, c4, 3), Conv(c4, c4, 3), nn.Conv2d(c4, self.nk, 1)) for x in ch)
尺度1的三个分支的网络结构如下所示(尺度2和尺度3相应也有三个输出)
| 目标框分支 | 分类分支 | 关键点分支 |
|---|---|---|
| 每个GRID输出4x16 | 每个GRID输出1个分类置信度 | 每个GRID输出17x3个关键点数据 |
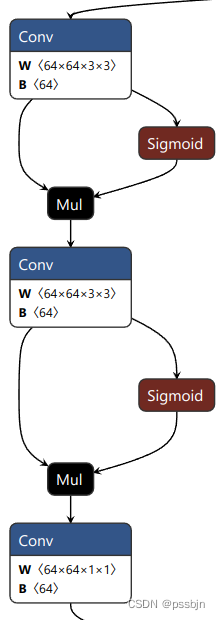 | 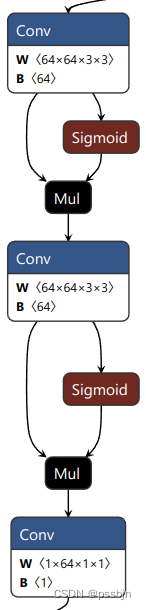 | 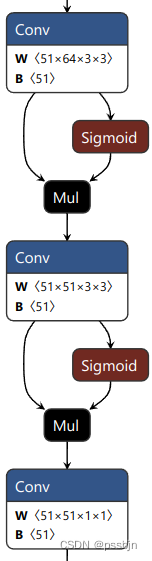 |
导出和裁剪
Pose.forward调用Detect.forward,因此先按照YOLOv8目标检测算法移植修改Detect.forward,然后修改Pose.forward
def forward(self, x):
"""Perform forward pass through YOLO model and return predictions."""
bs = x[0].shape[0] # batch size
#### 删除开始 ####
#kpt = torch.cat([self.cv4[i](x[i]).view(bs, self.nk, -1) for i in range(self.nl)], -1) # (bs, 17*3, h*w)
#### 删除结束 ####
#### 增加开始 ####
kpto = [ self.cv4[i](x[i]) for i in range(self.nl) ]
kpt = torch.cat([k.view(bs, self.nk, -1) for k in kpto], -1)
#### 增加结束 ####
x = self.detect(self, x)
#### 增加开始 ####
if self.export:
export_cut = []
if len(x) == 0: return export_cut
for in in range(self.nl):
export_cut += x[2*i:2*i+2]
export_cut.append(kpto[i].permute(0, 2, 3, 1)) # 方便C/C++计算缓存偏移
return export_cut
#### 增加结束 ####
#### 以下不变 ####
if self.training:
return x, kpt
执行脚本导出onnx模型文件
python3 yolo export pose model=yolov8n-pose.pt format=onnx imgsz=416,736 opset=12
测试
目标框和分类置信度相关的部分与目标检测算法相同,只需要额外计算关键点分支的输出。
for x, y, c in kps[idx]:
# 关键点的基准是GRID左上角
x = (col + 0 + x * 2) / w
y = (row + 0 + y * 2) / h
# 关键点置信度用sigmoid归一化到(0, 1)
# 关键点的置信度阈值为0.5,这里不计算sigmoid,用0作为阈值效果一样
c = 1 / (1 + np.exp(-c)) # sigmoid
C/C++调用代码
目标框和分类置信度相关的部分与目标检测算法相同,只需要额外计算关键点分支的输出。
/**
* kb [in] 关键点缓存
* col: 当前grid列序号
* row: 当前grid行序号
* w: 当前尺度输出宽度(GRID列数)
* h:当前尺度输出高度(GRID行数)
* scale:量化系数
*
* 这里没有对置信度计算sigmoid
*/
keypoint yolov8cut_convertor::convert_kp(const int16_t* kb, ulong col, ulong row, ulong w, ulong h, float scale)
{
float x = (kb[0] * scale * 2 + col) / w;
float y = (kb[1] * scale * 2 + row) / h;
float conf = kb[2] * scale;
return keypoint{x, y, conf};
}
下节预告:YOLOv8中的实例分割(Segment)同时完成两个任务:1. 检测目标框及目标分类 2. 对每个像素点进行二分类:前景或背景。Segment除了输出bounding box和类型置信度外,同时每尺度输出一个mask特阵图,和一个所有尺度共享的mask proto特征图,用于计算bouding box对应的mask。由于mask尺寸是输入尺寸的1/4,输出mask信息(例如在原始图像上叠加)时要同时考虑resize和padding的影响。















 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









