







2022.5.3 天气晴,白天热晚上冷。
physics,2008.
《Fast unfolding of communities in large networks》
一、出发点
community detection:将大图分割成小图,小图内的节点紧密关联,小图间几乎没有关联。
分割的测度或者也是优化目标:modularity,定义如下:
Q
=
1
2
m
∑
i
,
j
[
A
i
j
−
k
i
k
j
2
m
]
δ
(
c
i
,
c
j
)
.
Q = \frac{1}{2m}\sum_{i,j}[A_{ij}-\frac{k_ik_j}{2m}]\delta(c_i,c_j).
Q=2m1i,j∑[Aij−2mkikj]δ(ci,cj).
但是存在问题:计算复杂,因此很难处理大图(但是现实生活中应用的几乎都是大图)。
提出简化计算进行拟合的方法并没有很好解决问题。
因此我们关注于community detection,几乎所有的大网络都有自然的集体,我们希望我们的算法能够自然地找到这些分层结构。
二、方法
我们提出的算法的网络大小限制不是因为计算时间而是受制于存储空间。
我们的算法可以大致分为两个重复多次进行的步骤。假设存在一个N个节点的带权的网络。
步骤一:
开始的时候我们将网络中的节点都赋予一个不同的community(在算法一开始,community的数目和节点数目一样)。然后,对于节点i,我们考虑它的邻居j,我们计算将邻居j放入i的community的模块度的提升。将节点放入可以使模块度最大化的community之中。这个过程重复被进行,知道整个网络的模块度没有提升了,第一个步骤就结束了。
需要注意的是:算法的输出和探测节点的顺序相关,但是对于模块度的影响不大,对于计算时间的影响很大。因此选择出探测节点的顺序很重要,关乎计算时间。
算法的效率高的一部分原因在于the gain in modularity
Δ
Q
\Delta Q
ΔQ的计算通过将一个独立的节点i移入community C,计算如下:

步骤二:
建立一个新的网络,网络的节点是在步骤一中形成的community,links的权重是相关联的两个community之间的nodes的权重之和。在同一个community的节点之间的links将是新网络中的self-loops。
步骤二构建的新网络又可以应用步骤一。我们将步骤一+步骤二成为一个pass。在每个pass之中community的数目逐渐减少,最多的计算时间消耗在第一个pass之中。不断地执行passes,知道没有更多的改变以及获得了模块度的最大值。pass示意图如下所示: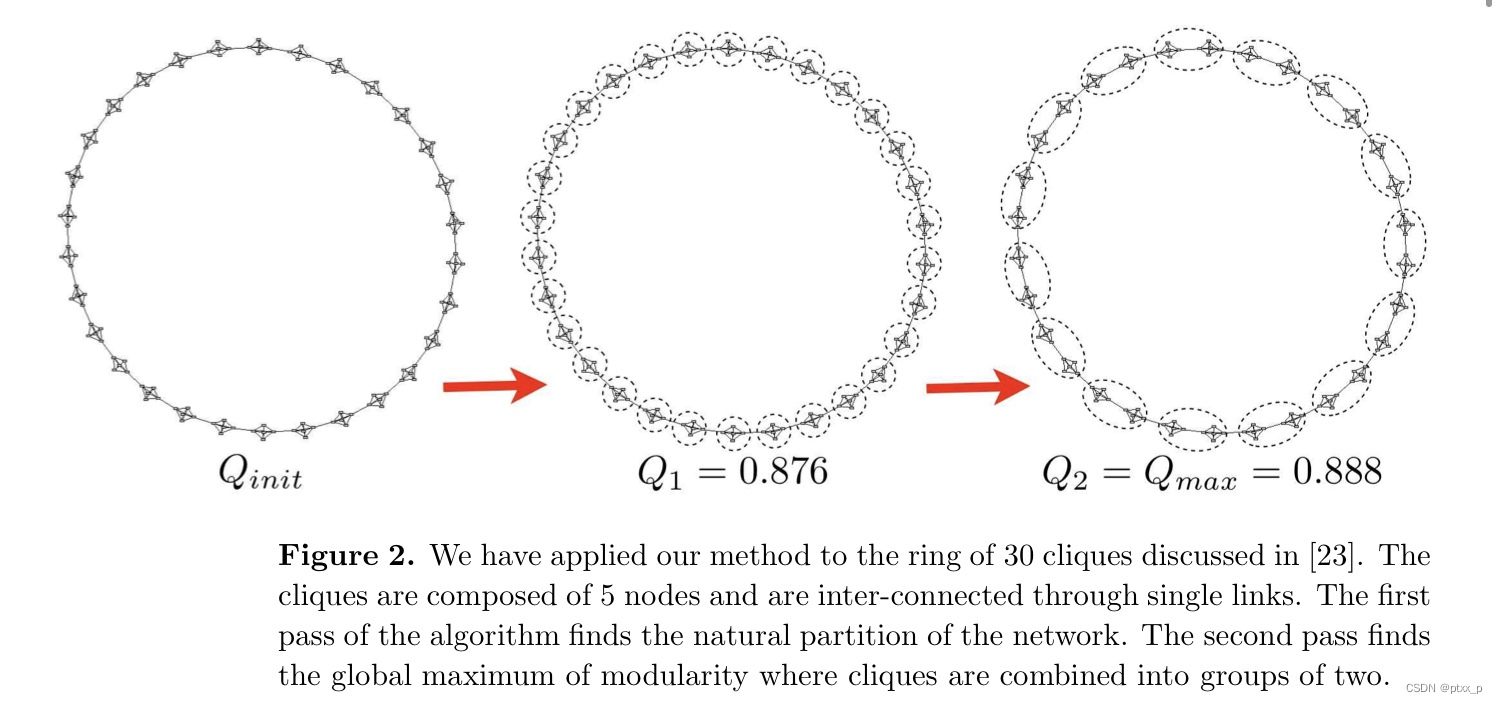
三、对方法的分析
方法是intuitive(直觉的),很容易实现,非监督的结果,计算很快。计算模拟结果发现对于典型的稀疏数据,复杂度是线性的(模块度增加量很容易计算、少数几次的pass之后,community的数目大大下降,且时间大部分花在第一个pass里了)。
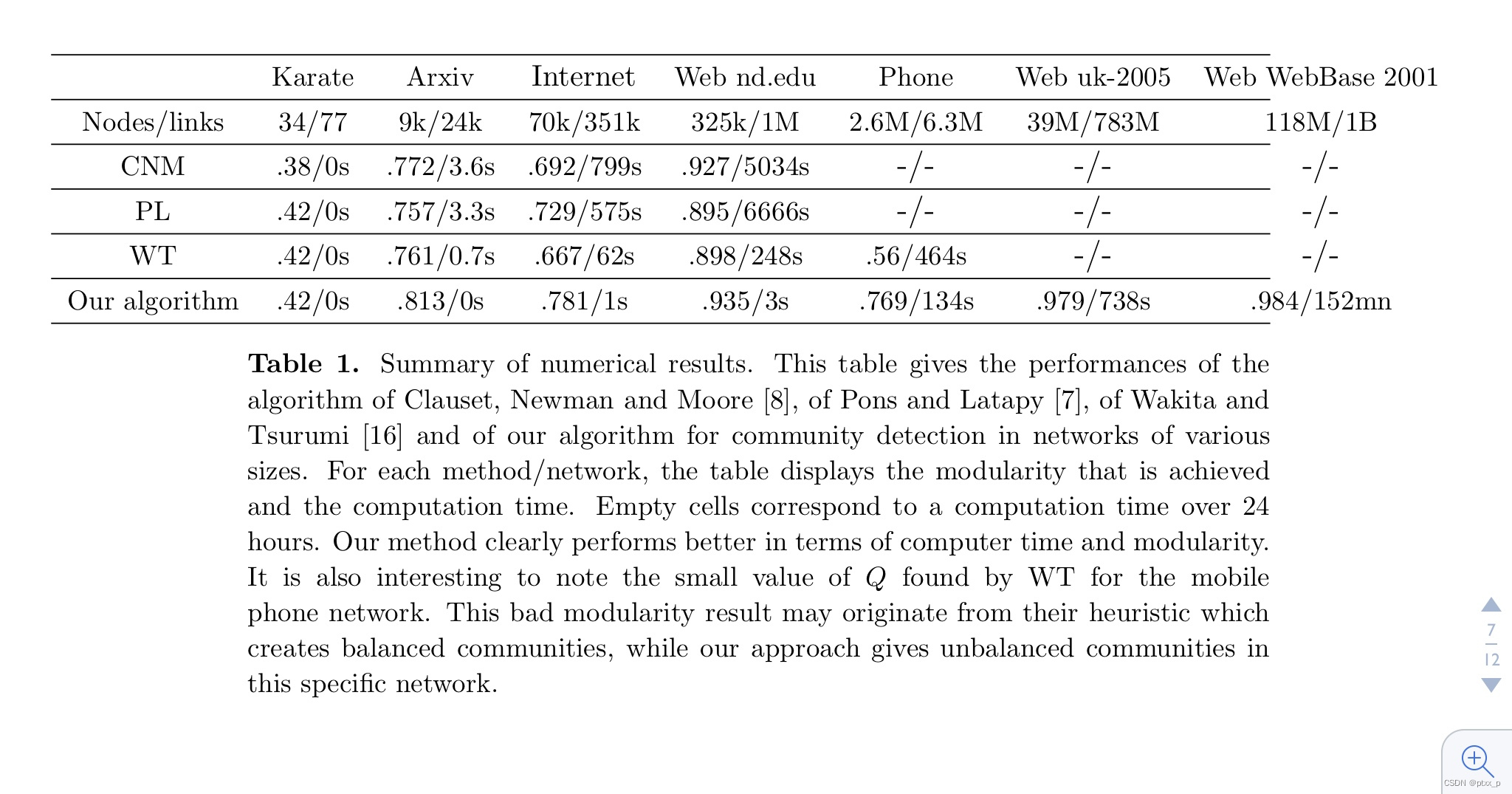
四、在大型网络上的应用(application to large networks)
切分准确度高+计算时间很短。















 4460
4460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









