







1,首先SGDM不会被类似于极小点的地方卡住而停止更新.因为SGDM与SGD最大的不同在于v值中包括了过去走过的所有梯度.

如上图,该方法引入了momentum,最终的移动方向由梯度与monentum共同决定.而不单纯由梯度决定,从而使得更新不会停止.
2,本方法的主要作用是动态调整学习率,在过去梯度比较大的地方(说明该部分损失函数变化比较大),这时候就需要减小学习率,而在过去梯度比较小的地方,说明变化比较小,学习率可以放心前进,所以用大的学习率

3,
这个算法与adagram算法的不同之处在于vt不会急剧增大,来平衡过去的梯度与现在梯度的关系.但是本算法解决不了在梯度小的地方会停止更新的问题.
4,
SGDM方法改变梯度,rms方法改变学习率,这里对mt与vt都进行了处理,是因为不想让mt与vt变大速度太快.
5,

现在使用的较为常用的两种方法是sgdm与adam,简单来说,sgdm训练得到的最小值比较稳定,在训练集与测试集相差可能不大,而adam优势在于快速找到最小值,但是找到的最小值的过程可能太快,而导致尖锐,失之毫厘,差之千里.

上图这种方法,试图结合两种方法,先用adam再用sgdm,但是在切换时存在问题.


adam的问题在于:每一步无论梯度有多大,如上图100000,但是也最多只能能提供比较小的移动,容易被前面的小梯度1影响,而真正的大梯度被忽略.
6,
然后为了解决问题提出以上解法,让vt记住特别大的梯度,但是这种方法可能会导致被一个特别大的梯度影响,导致学习率不更新,走了回头路.这个方法其实解决了梯度都很小,而导致学习率太大的问题,因为该算法不会忘记前面的大梯度.前面的大梯度,就不会让学习率太大.
7,
这种方法强制规定了学习率的最大与最小范围,但是问题在于上下界与损失函数没有关系,学习率在大梯度与小梯度上也没有达到自动调整的状态.仅仅是人工规定.这个方法试图解决梯度都很小,学习率太大,以及梯度太大,学习率太小的问题.
8,以下来试图改进SGDM算法来使得其更加快速.
为什么SGDM算法收敛慢,因为adam算法使用自适应的学习率,在梯度小的地方,学习率大,从而可以快速通过梯度小的地方.
所以能否找到一个合适的学习率给sgdm算法.,以下这部分改进都是让学习率周期变化.然后用到sgdm算法上



9,adam需要预热.
因为在adam算法初期,学习率较为不稳定.如下图,在算法开始时,会不稳定.


这是算法实现的效果时,vt的方差越大,rt越小,使得梯度变化大的时候使用小的学习率.这样就解决了adam的预热问题.因为rt乘在学习率上.并且在pt<4的时候,也就是一开始的时候,用的是sgdm算法.

RADM与前面提到的SWATS算法,都涉及了算法切换,但是两种方法解决的问题不同,RADM算法主要解决adam算法在开始的时候不稳定,而SWATS算法解决的是:让sgdm收敛更快.其次两种算法的切换点也不同.
10,

这种改进方法适用于前面所用的算法,相当于在算法外进行一次处理,算法对应公式中的,optim.这个方法的思想是,向前走k步,之后向后退一步,然后再将退回来的点作为新的起点,往前走k步,如此循环.就像上图,蓝色的线表示向前走,然后退到红色线的某一点,再从该点继续循环.

这种方法避免收敛于崎岖的极点,而导致test数据测试下降很严重,有一定稳定性.
11,

这种方法改进了sgdm方法,不同之处在于多减去一个mt-1,这一项用来预测未来的走向,由于不知道mt所以只能代替.这样可以防止sgdm走过极小值太多.

有一个问题是,在计算参数时,会多保留前一步的数据.最终经过数学推演,发现可以省略,如上图.可以看出就是将sgdm中的mt-1改为mt就实现了超前部署.
12,

利用上面的思想,将adam也可以超前预测.就是将mt-1改为mt
13,

前面提到,在算法中可以使用正则化来防止参数太大,那么在sgdm与adam等算法中,mt计算时,需不需要加入到正则项呢?
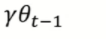

答案是不需要,只需要在计算参数时减去正则项,在mt(移动方向)上不需要添加.

以上技巧可以增加模型的随机性,学习到更多的知识.shuffling指每次打乱顺序输入data,

在模型刚训练时的数据对梯度走向有较大影响,因为刚开始学习率较大.这里可以刚开始用简单的数据,之后再用复杂的数据.也可以用现成的模型来减少训练时间.
14,总结

所有算法都可以与lookahead算法结合.

generalization指的是在训练集与测试集上变化情况.
15,建议

cv领域一般要用sgdm算法,强化学习两种都可能用到.















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









