






1停车位数据集类 停车场停车位检测数据集 2类 1200张 违停 带标注 voc yolo
停车场停车位检测数据集介绍
数据集概述
此数据集主要用于停车场内的停车位检测任务,涵盖了两类不同的状态:占用(occupied)和空闲(empty)。该数据集包含1230张高清JPG图像,每张图像对应一个VOC XML格式的标签文件或YOLO TXT格式的标签文件。数据集按照标准VOC和YOLO格式标注,可以直接用于基于这两种格式的目标检测算法模型训练。
数据集特点
数据集统计
|状态|类别ID|图片数量|标注个数
|------
|占用|0|1035|2634
|空闲|1|1131|4280
|总计|1230|6914
数据集结构
ParkingSpotDetectionDataset/
├── images/ # 图像文件
│ ├── train/ # 训练集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ ├── val/ # 验证集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ └── test/ # 测试集图像(如果存在)
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
└── annotations/ # 标注文件夹
├── annotations_voc/ # VOC/Pascal VOC格式标注
│ ├── train/ # 训练集标注
│ │ ├── image_00001.xml
│ │ ├── image_00002.xml
│ │ └── ...
│ ├── val/ # 验证集标注
│ │ ├── image_00001.xml
│ │ ├── image_00002.xml
│ │ └── ...
│ └── test/ # 测试集标注(如果存在)
│ ├── image_00001.xml
│ ├── image_00002.xml
│ └── ...
└── annotations_yolo/ # YOLO格式标注
├── train/ # 训练集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
├── val/ # 验证集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
└── test/ # 测试集标签(如果存在)
├── image_00001.txt
├── image_00002.txt
└── ...
标注格式示例
VOC/Pascal VOC格式
每个XML文件包含图像信息和标注信息:
<annotation>
<folder>images</folder>
<filename>image_00001.jpg</filename>
<path>/path/to/images/image_00001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>occupied</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>100</xmin>
<ymin>150</ymin>
<xmax>200</xmax>
<ymax>300</ymax>
</bndbox>
</object>
<object>
<name>empty</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>300</xmin>
<ymin>250</ymin>
<xmax>400</xmax>
<ymax>350</ymax>
</bndbox>
</object>
</annotation>
YOLO格式
每行表示一个物体的边界框和类别:
class_id cx cy w h
例如:
0 0.453646 0.623148 0.234375 0.461111
1 0.553646 0.723148 0.134375 0.361111
使用该数据集进行模型训练
- 数据预处理与加载
首先,我们需要加载数据并将其转换为适合YOLOv5等模型使用的格式。假设你已经安装了PyTorch和YOLOv5。
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import xml.etree.ElementTree as ET
class ParkingSpotDetectionDataset(Dataset):
def __init__(self, image_dir, annotation_dir, transform=None):
self.image_dir = image_dir
self.annotation_dir = annotation_dir
self.transform = transform
self.image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = self.image_files[idx]
img_path = os.path.join(self.image_dir, img_name)
annotation_path = os.path.join(self.annotation_dir, img_name.replace('.jpg', '.xml'))
# 加载图像
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
# 加载标注
tree = ET.parse(annotation_path)
root = tree.getroot()
boxes = []
labels = []
for obj in root.findall('object'):
category = obj.find('name').text.lower()
if category == 'occupied':
class_id = 0
elif category == 'empty':
class_id = 1
else:
continue
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
boxes.append([xmin, ymin, xmax, ymax])
labels.append(class_id)
boxes = torch.tensor(boxes, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.int64)
return image, boxes, labels
# 数据增强
transform = transforms.Compose([
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
# 创建数据集
train_dataset = ParkingSpotDetectionDataset(image_dir='ParkingSpotDetectionDataset/images/train/', annotation_dir='ParkingSpotDetectionDataset/annotations_voc/train/', transform=transform)
val_dataset = ParkingSpotDetectionDataset(image_dir='ParkingSpotDetectionDataset/images/val/', annotation_dir='ParkingSpotDetectionDataset/annotations_voc/val/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=4)
- 构建模型
我们可以使用YOLOv5模型进行目标检测任务。假设你已经克隆了YOLOv5仓库,并按照其文档进行了环境设置。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
创建数据配置文件 data/parking_spot_detection.yaml:
train: path/to/ParkingSpotDetectionDataset/images/train
val: path/to/ParkingSpotDetectionDataset/images/val
test: path/to/ParkingSpotDetectionDataset/images/val # 如果没有单独的测试集,可使用验证集作为测试集
nc: 2 # 类别数
names: ['occupied', 'empty']
- 训练模型
使用YOLOv5进行训练。
python train.py --img 640 --batch 16 --epochs 100 --data data/parking_spot_detection.yaml --weights yolov5s.pt --cache
- 评估模型
在验证集上评估模型性能。
python val.py --img 640 --batch 16 --data data/parking_spot_detection.yaml --weights runs/train/exp/weights/best.pt --task test
- 推理
使用训练好的模型进行推理。
python detect.py --source path/to/test/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.5
实验报告
实验报告应包括以下内容:
- 项目简介:简要描述项目的背景、目标和意义。1. 数据集介绍:详细介绍数据集的来源、规模、标注格式等。1. 模型选择与配置:说明选择的模型及其配置参数。1. 训练过程:记录训练过程中的损失变化、学习率调整等。1. 评估结果:展示模型在验证集上的性能指标(如mAP、准确率)。1. 可视化结果:提供一些典型样本的检测结果可视化图。1. 结论与讨论:总结实验结果,讨论可能的改进方向。1. 附录:包含代码片段、图表等补充材料。
依赖库
确保安装了以下依赖库:
pip install torch torchvision
pip install -r yolov5/requirements.txt
总结
这个停车场停车位检测数据集提供了丰富的标注数据,非常适合用于训练和评估停车位检测模型。通过YOLOv5框架,可以方便地构建和训练高性能的停车位检测模型。实验报告可以帮助你更好地理解和分析模型的表现,并为进一步的研究提供参考。由于数据集规模较大且多样,建议在训练过程中使用数据增强技术以提高模型的泛化能力。
2.监控航拍视角停车位数据集 停车位识别系统+模型+界面 停车位数据集12416xml和txt标签 yolo
停车场停车位检测数据集与系统
数据集概述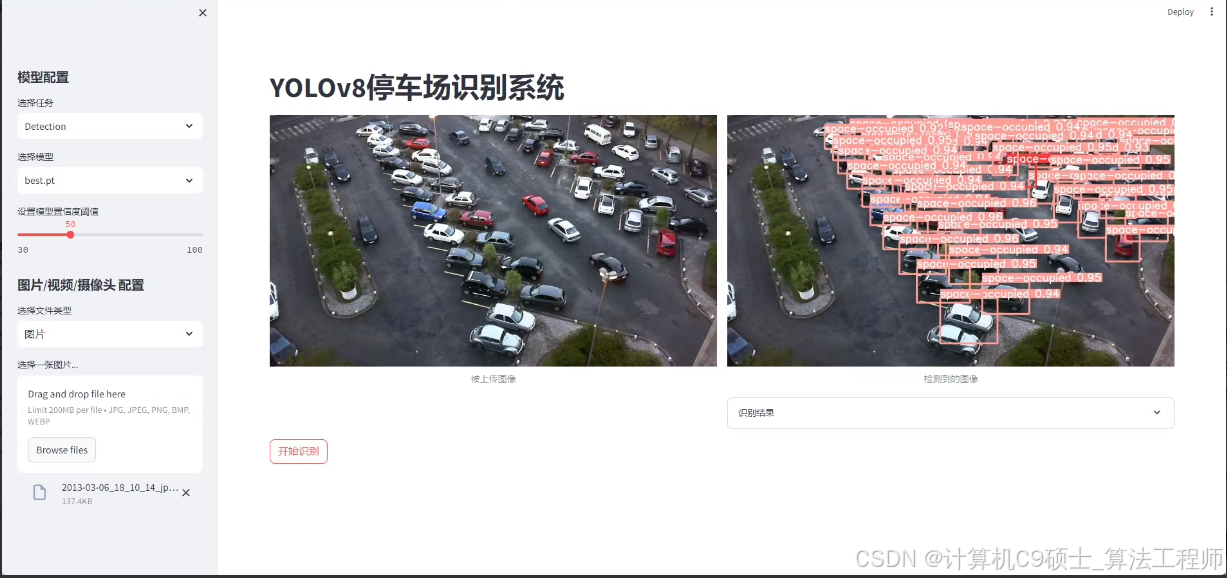
此数据集专为停车场停车位检测设计,包含了从监控摄像头帧中提取的12,416张停车场图像,涵盖晴天、阴天和雨天等多种天气条件下的图像。图像中的停车位被明确标记为“space-empty”(空闲)或“space-occupied”(占用)两种状态。数据集提供了VOC XML和YOLO TXT两种格式的标注文件,可以直接用于基于这两种格式的目标检测算法模型训练。
数据集特点
数据集统计
|状态|类别ID|图片数量|标注个数
|------
|空闲|0|未知|未知
|占用|1|未知|未知
|总计|12,416|未知
数据集结构
ParkingSpaceDetectionDataset/
├── images/ # 图像文件
│ ├── train/ # 训练集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ ├── val/ # 验证集图像
│ │ ├── image_00001.jpg
│ │ ├── image_00002.jpg
│ │ └── ...
│ └── test/ # 测试集图像(如果存在)
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
└── annotations/ # 标注文件夹
├── annotations_voc/ # VOC/Pascal VOC格式标注
│ ├── train/ # 训练集标注
│ │ ├── image_00001.xml
│ │ ├── image_00002.xml
│ │ └── ...
│ ├── val/ # 验证集标注
│ │ ├── image_00001.xml
│ │ ├── image_00002.xml
│ │ └── ...
│ └── test/ # 测试集标注(如果存在)
│ ├── image_00001.xml
│ ├── image_00002.xml
│ └── ...
└── annotations_yolo/ # YOLO格式标注
├── train/ # 训练集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
├── val/ # 验证集标签
│ ├── image_00001.txt
│ ├── image_00002.txt
│ └── ...
└── test/ # 测试集标签(如果存在)
├── image_00001.txt
├── image_00002.txt
└── ...
标注格式示例
VOC/Pascal VOC格式
每个XML文件包含图像信息和标注信息:
<annotation>
<folder>images</folder>
<filename>image_00001.jpg</filename>
<path>/path/to/images/image_00001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>space-empty</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>100</xmin>
<ymin>150</ymin>
<xmax>200</xmax>
<ymax>300</ymax>
</bndbox>
</object>
<object>
<name>space-occupied</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>300</xmin>
<ymin>250</ymin>
<xmax>400</xmax>
<ymax>350</ymax>
</bndbox>
</object>
</annotation>
YOLO格式
每行表示一个物体的边界框和类别:
class_id cx cy w h
例如:
0 0.453646 0.623148 0.234375 0.461111
1 0.553646 0.723148 0.134375 0.361111
数据集与系统的购买选项
使用该数据集进行模型训练
- 数据预处理与加载
首先,我们需要加载数据并将其转换为适合YOLOv5等模型使用的格式。假设你已经安装了PyTorch和YOLOv5。
import os
from PIL import Image
import torch
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import xml.etree.ElementTree as ET
class ParkingSpaceDetectionDataset(Dataset):
def __init__(self, image_dir, annotation_dir, transform=None):
self.image_dir = image_dir
self.annotation_dir = annotation_dir
self.transform = transform
self.image_files = [f for f in os.listdir(image_dir) if f.endswith('.jpg')]
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_name = self.image_files[idx]
img_path = os.path.join(self.image_dir, img_name)
annotation_path = os.path.join(self.annotation_dir, img_name.replace('.jpg', '.xml'))
# 加载图像
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
# 加载标注
tree = ET.parse(annotation_path)
root = tree.getroot()
boxes = []
labels = []
for obj in root.findall('object'):
category = obj.find('name').text.lower()
if category == 'space-empty':
class_id = 0
elif category == 'space-occupied':
class_id = 1
else:
continue
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
boxes.append([xmin, ymin, xmax, ymax])
labels.append(class_id)
boxes = torch.tensor(boxes, dtype=torch.float32)
labels = torch.tensor(labels, dtype=torch.int64)
return image, boxes, labels
# 数据增强
transform = transforms.Compose([
transforms.Resize((640, 640)),
transforms.ToTensor(),
])
# 创建数据集
train_dataset = ParkingSpaceDetectionDataset(image_dir='ParkingSpaceDetectionDataset/images/train/', annotation_dir='ParkingSpaceDetectionDataset/annotations_voc/train/', transform=transform)
val_dataset = ParkingSpaceDetectionDataset(image_dir='ParkingSpaceDetectionDataset/images/val/', annotation_dir='ParkingSpaceDetectionDataset/annotations_voc/val/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False, num_workers=4)
- 构建模型
我们可以使用YOLOv5模型进行目标检测任务。假设你已经克隆了YOLOv5仓库,并按照其文档进行了环境设置。
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
创建数据配置文件 data/parking_space_detection.yaml:
train: path/to/ParkingSpaceDetectionDataset/images/train
val: path/to/ParkingSpaceDetectionDataset/images/val
test: path/to/ParkingSpaceDetectionDataset/images/val # 如果没有单独的测试集,可使用验证集作为测试集
nc: 2 # 类别数
names: ['space-empty', 'space-occupied']
- 训练模型
使用YOLOv5进行训练。
python train.py --img 640 --batch 16 --epochs 100 --data data/parking_space_detection.yaml --weights yolov5s.pt --cache
- 评估模型
在验证集上评估模型性能。
python val.py --img 640 --batch 16 --data data/parking_space_detection.yaml --weights runs/train/exp/weights/best.pt --task test
- 推理
python detect.py --source path/to/test/image.jpg --weights runs/train/exp/weights/best.pt --conf 0.5
可视化界面
该选项包括了一个用户友好的可视化界面,用户可以通过该界面上传图片或者视频流,实时查看停车位的状态。界面设计通常包括:
应用场景
实验报告
实验报告应包括以下内容:
- 项目简介:简要描述项目的背景、目标和意义。1. 数据集介绍:详细介绍数据集的来源、规模、标注格式等。1. 模型选择与配置:说明选择的模型及其配置参数。1. 训练过程:记录训练过程中的损失变化、学习率调整等。1. 评估结果:展示模型在验证集上的性能指标(如mAP、准确率)。1. 可视化结果:提供一些典型样本的检测结果可视化图。1. 结论与讨论:总结实验结果,讨论可能的改进方向。1. 附录:包含代码片段、图表等补充材料。
依赖库
确保安装了以下依赖库:
pip install torch torchvision
pip install -r yolov5/requirements.txt
🔥计算机视觉、图像处理、毕业辅导、作业帮助、代码获取,远程协助,代码定制,私聊会回复!
🚀B站项目实战:https://space.bilibili.com/364224477
😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏
📂QQ+加:673276993
🤵♂代做需求:@个人主页
总结
这个停车场停车位检测数据集和系统提供了丰富的标注数据和现成的应用方案,非常适合用于训练和部署停车位检测模型。通过YOLOv5框架,可以方便地构建和训练高性能的停车位检测模型。实验报告可以帮助你更好地理解和分析模型的表现,并为进一步的研究提供参考。由于数据集规模较大且多样,建议在训练过程中使用数据增强技术以提高模型的泛化能力。


















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











