






目录
torch.nn.parallel.DistributedDataParallel:数据并行化
torch.nn.parallel.DistributedDataParallel:数据并行化
什么是分布式训练? - Azure Machine Learning | Microsoft Learn
torch.nn.parallel.DistributedDataParallel: 快速上手 - 知乎 (zhihu.com)
数据并行
数据并行是两种分布式训练方法中较易实现的一个,对于大多数用例来说已经足够了。
在此方法中,数据划分到计算群集中的分区内,其中分区数等于可用节点的总数。 将在这些工作器节点的每一个中复制模型,每个工作器都操作和处理自己的数据子集。 请记住,每个节点都必须有能力支持正在进行训练的模型,也就是说,模型需要拟合每个节点。 下图直观地阐释了此方法。
每个节点独立计算其训练样本的预测结果与标记输出之间的误差。 每个节点又会基于该误差更新其模型,且必须将其所有更改传达给其他节点,以便其相应更新其自己的模型。 这意味着,工作器节点需要在批处理计算结束时同步模型参数或梯度,以确保其训练的是一致的模型。
load_state_dict
(15条消息) Pytorch保存和加载模型(load和load_state_dict)_木盏的博客-CSDN博客
scheduler
训练时的学习率调整:optimizer和scheduler - 知乎 (zhihu.com)
optimizer是指定使用哪个优化器,scheduler是对优化器的学习率进行调整,正常情况下训练的步骤越大,学习率应该变得越小。optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对。可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr进行调整。通常我们在scheduler的step_size表示scheduler.step()每调用step_size次,对应的学习率就会按照策略调整一次。
auxiliary loss(辅助损失)
(15条消息) 多任务学习中的auxiliary loss(辅助损失)_鱿鱼圈是真鱿鱼吗的博客-CSDN博客

多任务学习(Multi-Task Learning)
是通过在相关任务间共享表示信息,使得模型在原始任务上泛化性能更好。也就是说,一旦发现我们的目标是优化多于一个的目标函数,就可以通过多任务学习来有效求解;但即使对于优化目标只有一个的特殊的情况,辅助任务仍然有可能帮助我们改善主任务的学习性能。
inference(推理)
深度学习的宏观框架——训练(training)和推理(inference)及其应用场景_训练和推理
VGG迁移学习
vgg用以提取图像特征
(21条消息) pytorch迁移学习详解(提取整个网络or提取网络中的指定层+Segnet)_饿不坏的企鹅的博客-CSDN博客
class vgg16bn(torch.nn.modules):
def __init__(self, pretrained=False):
super(vgg16bn, self).__init__()
model = list(torchvision.models.vgg16(pretrained=pretrained).features.children())
model = model[:33] + model[34:43]
self.model = torch.nn.Sequential(*model)
def forward(self, x):
return self.model(x) 
ResNet迁移学习
残差神经网络,解决了模型退化问题
class resnet(torch.nn.Module):
def __init__(self, layers, pretrained=False):
super(resnet, self).__init__()
if layers == '18':
model = torchvision.models.resnet18(pretrained=pretrained)
elif layers == '34':
model = torchvision.models.resnet34(pretrained=pretrained)
elif layers == '50':
model = torchvision.models.resnet50(pretrained=pretrained)
elif layers == '101':
model = torchvision.models.resnet101(pretrained=pretrained)
elif layers == '152':
model = torchvision.models.resnet152(pretrained=pretrained)
elif layers == '50next':
model = torchvision.models.resnext50_32x4d(pretrained=pretrained)
elif layers == '101next':
model = torchvision.models.resnext101_32x8d(pretrained=pretrained)
elif layers == '50wide':
model = torchvision.models.wide_resnet50_2(pretrained=pretrained)
elif layers == '101wide':
model = torchvision.models.wide_resnet101_2(pretrained=pretrained)
else:
raise NotImplementedError
self.conv1 = model.conv1
self.bn1 = model.bn1
self.relu = model.relu
self.maxpool = model.maxpool
self.layer1 = model.layer1
self.layer2 = model.layer2
self.layer3 = model.layer3
self.layer4 = model.layer4
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x2 = self.layer2(x)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
return x2, x3, x4backbone与model的关系

Numpy.prod
(21条消息) Python 的np.prod函数详解_furuit的博客-CSDN博客
torch.nn.functional.interpolate(采样)
上采样:让输入图片变高清
torch.nn.functional.interpolate()函数解析
torch.cat

超参初始化
目录
torch.nn.parallel.DistributedDataParallel:数据并行化
torch.nn.functional.interpolate(采样)
torch.nn.init.kaiming_normal_:
torch.nn.init.constant_:
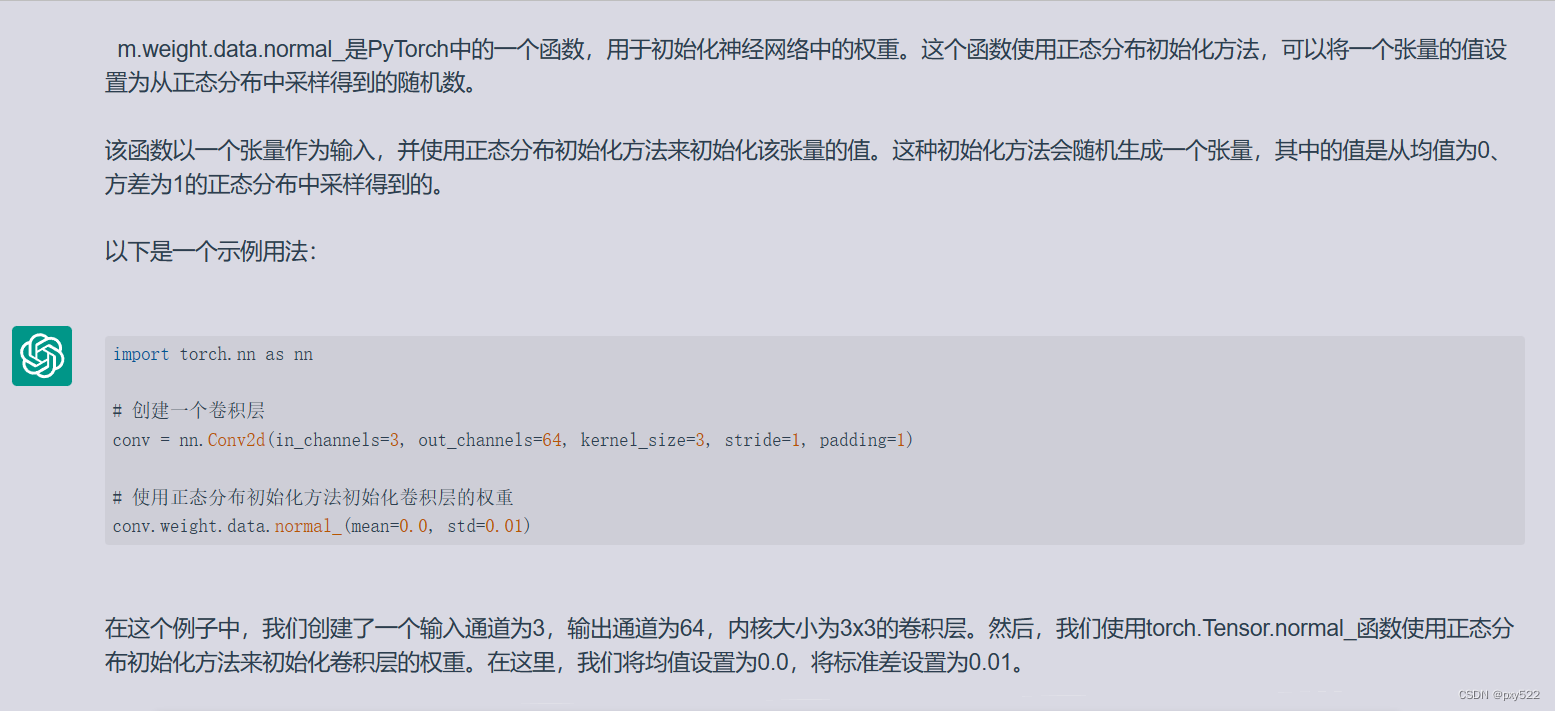
m.weight.data.normal_:















 2369
2369











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









