






在人工智能的浪潮中,大型语言模型(LLMs)因其在自然语言处理领域的巨大贡献而广受欢迎。尽管如此,LLMs在实时获取外部数据方面存在局限。这些模型的训练是在特定时间点完成的,这就意味着它们无法获取到最新的信息,从而影响提供准确答案的能力。

为了解决这一问题,智能体(Agents)被引入,它是一种生成式人工智能(Generative AI)构建,可以将简单的问答或文本生成提升到一个新的层次。通过智能体,可以提供访问不同工具或API的权限,并允许模型本身推理出应该采取的正确行动。例如,通过提供访问天气API的权限,智能体可以检索必要的数据来回答相关问题。
1 音乐推荐用例
在音乐推荐的场景中,传统的推荐引擎或系统需要构建特定模型并经历训练。然而,对于简单的用例,一个不需要构建特定模型或经历训练的解决方案更为合适。LangChain提供了一种智能体驱动的方法,通过ReAct智能体(推理+行动),允许在采取行动之前进行观察和思考。
LangChain是一个流行的Python框架,它通过提供现成的模块来简化生成式AI应用程序,这些模块有助于提示工程、RAG实现和LLM工作流程编排。在这个特定的用例中,LangChain被用来构建ReAct智能体,并为它提供所需的必要工具。
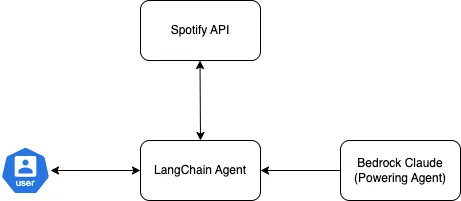
2 智能体驱动的解决方案
2.1 设置
在这个例子中,我们将在SageMaker Studio Notebook中使用一个ml.t3.medium实例进行工作。你可以选择喜欢的开发环境,只要能够安装以下库:
!pip install spotipy langchain
注意,在开始之前,如果还没有Spotify开发者账户,请创建。在你的Spotify开发者账户中,请确保已经创建了一个应用程序,这将显示与API一起使用所需的凭证。创建完成,你应该能够在仪表板的项目中可视化你的凭证(设置选项卡)和API请求。
 Spotify仪表板
Spotify仪表板
然后在笔记本中实例化用于与Spotify工作的客户端。

现在已经设置了Spotify客户端,准备进入智能体编排部分。
2.2 自定义工具类
LangChain智能体需要访问工具,这些工具将使它们能够与外部数据源一起工作。有许多内置工具,如Wikipedia,只需在LangChain中指定包即可,如下所示:

目前,还没有与Spotify API的原生集成,因此需要从BaseTool类继承并构建一个Spotify工具,然后将其交给我们的智能体。
我们定义一个扩展了BaseTool类的Spotify工具:

请注意,我们提供了何时使用此工具的描述,这允许LLM使用自然语言理解来推断何时使用该工具。我们还提供了工具应该期望的输入的模式。在这种情况下,指定了两个参数:
- 艺术家:感兴趣的艺术家列表,基于此,LLM将推荐该艺术家的更多热门曲目。
- 曲目数量:想要显示的建议曲目数量。

时使用此工具。" args_schema: Type[BaseModel] = MusicInput # 定义模式
现在已经了解了LLM在提示中应该寻找的输入,可以定义一些不同的方法来使用Spotipy包:

这些方法本质上是获取检索到的艺术家,并返回这些艺术家的顶级曲目。请注意,目前Spotipy API只能检索到前10首曲目。
然后我们定义了一个主执行函数,其中获取所请求艺术家的所有顶级曲目,并解析在我们的提示中请求的曲目数量:
主执行函数
def _run(self, artists: list, tracks: int) -> list:
num_artists = len(artists)
max_tracks = num_artists * 10
all_tracks_map = SpotifyTool.
all_top_tracks(artists) # 艺术家与前10首曲目的映射 all_tracks = [track for artist_map in all_tracks_map for artist, tracks in artist_map.items() for track in tracks] # 完整的曲目列表
# 每个艺术家只有10首曲目
if tracks > max_tracks:
raise ValueError(f"每个艺术家只有10首曲目,这么多艺术家的最大曲目数是:{max_tracks}")
final_tracks = random.sample(all_tracks, tracks)
return final_tracks
如果希望在API中加入额外的功能(构建自己的播放列表),可以在该工具本身中定义这些额外的方法。
2.3 智能体创建与调用
虽然已经定义了智能体需要的输入/输出规范,但我们必须定义LLM,它是操作的大脑。
在这种情况下,使用Anthropic Claude通过Amazon Bedrock:

然后可以实例化工具类,并将这个与LLM一起创建我们的智能体。注意,指定智能体类型为ReAct,根据您使用的智能体类型需要进行调整。
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
tools = [SpotifyTool()]
agent = initialize_agent(tools, llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
智能体构建完成之后,可以运行一个样本推理(随机混合艺术家),并看到我们已经启用的详细输出的思考链。
print(agent.run("""我喜欢以下艺术家:[Arijit Singh, Future, The Weeknd],我可以得到包含他们的12首歌曲推荐。"""))
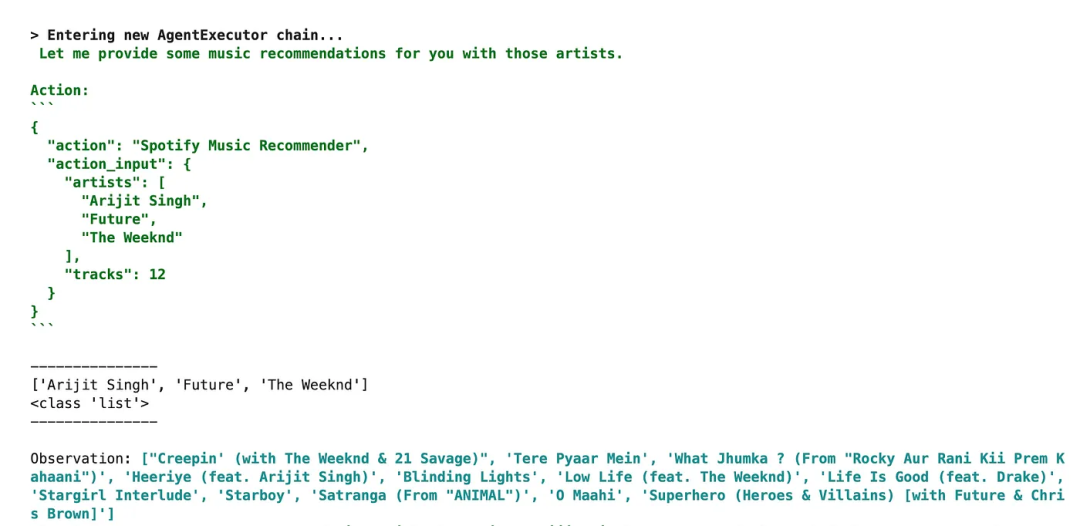 智能体响应一
智能体响应一
 智能体响应二
智能体响应二
请注意,智能体特别寻找我们指定用于使用此工具的两个参数,一旦它识别了这些参数,就能够采取逻辑上的行动,并正确执行推理,使用我们提交的值。
3 结语
智能体的力量在于你可以决定可以检索的后端功能。在这个示例中,我们只是检索艺术家的顶级曲目,但可以通过在你的工具中添加适当的API调用来扩展此示例,以直接在你的Spotify账户中创建播放列表。对于更现实或个性化的用例,也可以使用RAG让智能体访问自己的数据/音乐,并让它从那里获取的建议。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









