






01
概述
大模型概述
大模型是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数。大模型的设计目的是为了提高模型的表达能力和预测性能,能够处理更加复杂的任务和数据。大模型在各种领域都有广泛的应用,包括自然语言处理、计算机视觉、语音识别和推荐系统等。大模型通过训练海量数据来学习复杂的模式和特征,具有更强大的泛化能力,可以对未见过的数据做出准确的预测。
ChatGPT对大模型的解释更为通俗易懂,也更体现出类似人类的归纳和思考能力:大模型本质上是一个使用海量数据训练而成的深度神经网络模型,其巨大的数据和参数规模,实现了智能的涌现,展现出类似人类的智能。
- 小模型通常指参数较少、层数较浅的模型,它们具有轻量级、高效率、易于部署等优点,适用于数据量较小、计算资源有限的场景,例如移动端应用、嵌入式设备、物联网等。
- 相比小模型,大模型通常参数较多、层数较深,具有更强的表达能力和更高的准确度,但也需要更多的计算资源和时间来训练和推理,适用于数据量较大、计算资源充足的场景,例如云端计算、高性能计算、人工智能等。
大模型相关概念
大模型(Large Model,也称基础模型,即Foundation Model),是指具有大量参数和复杂结构的机器学习模型,能够处理海量数据、完成各种复杂的任务,如自然语言处理、计算机视觉、语音识别等。
超大模型:超大模型是大模型的一个子集,它们的参数量远超过大模型。
大语言模型(LLM,Large Language Model):通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI的GPT-3模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
GPT(Generative Pre-trained Transformer):GPT和ChatGPT都是基于Transformer架构的语言模型,但它们在设计和应用上存在区别:GPT模型旨在生成自然语言文本并处理各种自然语言处理任务,如文本生成、翻译、摘要等。它通常在单向生成的情况下使用,即根据给定的文本生成连贯的输出。
ChatGPT:ChatGPT则专注于对话和交互式对话。它经过特定的训练,以更好地处理多轮对话和上下文理解。ChatGPT设计用于提供流畅、连贯和有趣的对话体验,以响应用户的输入并生成合适的回复。
模型的泛化能力:是指一个模型在面对新的、未见过的数据时,能够正确理解和预测这些数据的能力。在机器学习和人工智能领域,模型的泛化能力是评估模型性能的重要指标之一。
模型微调(Fine Tune):给定预训练模型(Pre-trained model),基于模型进行微调。相对于从头开始训练(Training a model from scatch),微调可以省去大量计算资源和计算时间,提高计算效率,甚至提高准确率。模型微调的基本思想是使用少量带标签的数据对预训练模型进行再次训练,以适应特定任务。在这个过程中,模型的参数会根据新的数据分布进行调整。这种方法的好处在于,它利用了预训练模型的强大能力,同时还能够适应新的数据分布。因此,模型微调能够提高模型的泛化能力,减少过拟合现象。
大模型分类
按照输入数据类型的不同,大模型主要可以分为以下三大类:
语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT系列(OpenAI)、Bard(Google)、文心一言(百度)。
视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT系列(Google)、文心UFO、华为盘古CV、INTERN(商汤)。
多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了NLP和CV的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB多模向量数据库(九章云极DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、MidJourney。
按照应用领域的不同,大模型主要可以分为L0、L1、L2三个层级:
- 通用大模型L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于AI完成了“通识教育”。
- 行业大模型L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于AI成为“行业专家”。
- 垂直大模型L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
主流LLM介绍
近期大语言模型迅速发展,一些学者整理出了ChatGPT等语言模型的发展历程的进化树图,如下所示:
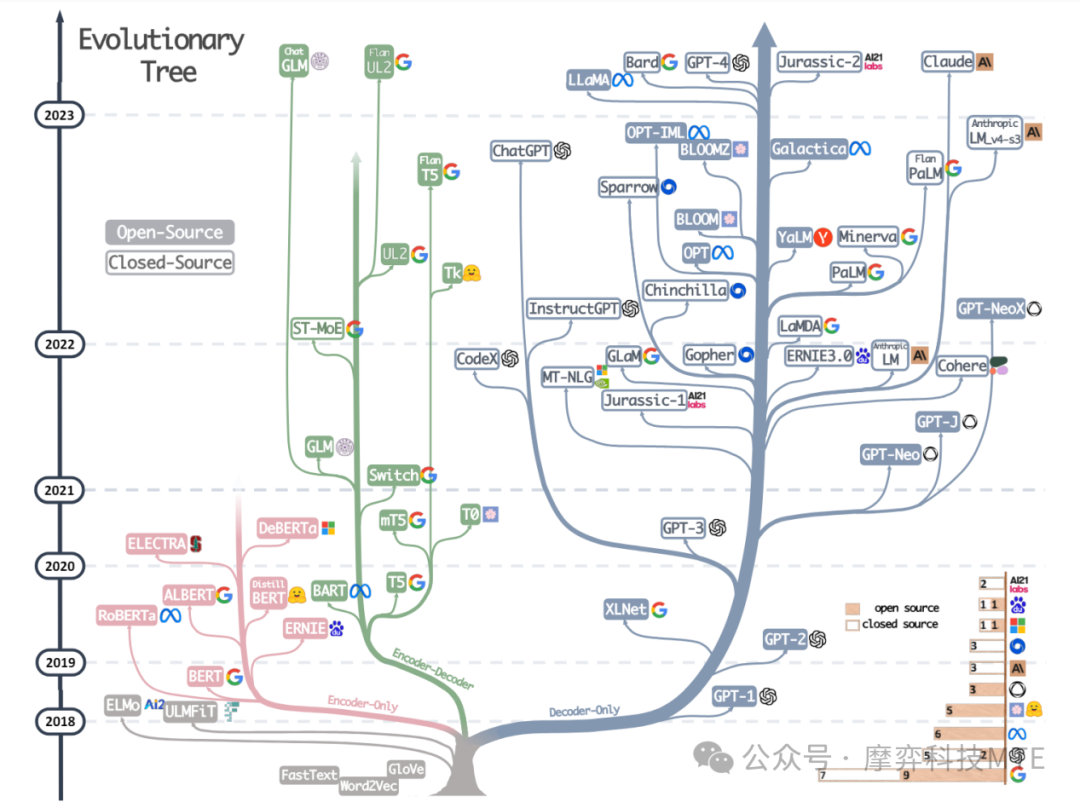
上图中,基于Transformer的模型显示为非灰色颜色:仅解码器模型显示为蓝色分支,仅编码器模型显示为粉红色分支,而编码器-解码器模型显示为绿色分支。时间轴上模型的垂直位置代表其发布日期。开源模型由实心方块表示,而闭源模型由空心方块表示。右下角的堆叠条形图显示来自各公司和机构的模型数量。
另一方面从开放程度来看可以分为闭源大模型和开源大模型,闭源大模型主要包括了GPT系列、Claude系列、PaLM系列、国产系列(文心一言、星火大模型)等;而开源大模型主要分为LLaMA系列和GLM系列。具体见下面的介绍:
- 闭源大模型:
(1) GPT系列:由于OpenAI开发的一系列自然语言处理模型,每一代模型都展示了自然语言处理技术的进步和突破。这些模型基于Transform的解码器结构,主要有于生成文本。OpenAI发布的模型主要包括了GPT-3、GPT-3.5、GPT-4、DALL-E、Sora(2024年2月),Sora是文本直接生成视频的大模型。
(2) Claude系列:美国人工智能初创公司Anthropic发布的大型语言模型家族,拥有高级推理、视觉分析、代码生成、多语言处理、多模态等能力,该模型对标ChatGPT、Gemini等产品。2024年3月4日,Claude 3系列正式发布。
(3)PaLM系列:Google发布的大模型系列,2022年8月推出PaLM模型,2023年5月发布了PaLM2和Bard,2023年12月推出Gemini,2024年2月推出Gemma。
(4) 文心一言:百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
(5) 星火大模型:科大讯飞推出的新一代认知智能大模型,拥有跨领域的知识和语言理解能力,能够基于自然对话方式理解与执行任务。
- 开源大模型:
(1) LLaMA系列:2023年7月,Meta公司发布了人工智能模型LLaMA 2的开源商用版本,意味着大模型应用进入了“免费时代”,初创公司也能够以低廉的价格来创建类似ChatGPT这样的聊天机器人。2024年4月发布了LLama3,号称是同类中“最强”开源大模型,包括8B和70B两个版本。
(2) GLM系列:是智谱AI(由清华大学计算机系知识工程实验室的技术转化而来)多年技术积累的成果,全称是General Language Model Pretraining with Autoregressive Blank Infilling,意为“基于自回归空白填充的通用语言模型预训练”,是一个开源的大模型。2023年10月智谱AI开源了Chat GLM3-6B(32K)、多模态CogVLM-17B、以及智能体Agent LM。
AI智能体(AI Agent)
LLM Agent是一种基于LLM的智能代理,它能够自主学习和执行任务,具有一定的“认知能力和决策能力”。LLM Agent打破了传统LLM的被动性,使LLM能够主动学习和执行任务,从而提高了LLM的应用范围和价值;它为LLM的智能化发展提供了新的方向,使LLM能够更加接近于人类智能。
AutoGPT 就是一个典型的 LLM Agent。在给定 AutoGPT一个自然语言目标后,它会尝试将其分解为多个子任务,并在自动循环中使用互联网和其他工具来实现该目标。它使用的是OpenAl的GPT-4或GPT-3.5 API,是首个使用GPT-4执行自主任务的应用程序实例。
AutoGPT最大的特点在于能根据任务指令自主分析和执行,当收到一个需求或任务时,它会开始分析这个问题,并且给出执行目标和具体任务,然后开始执行。
类似Agent架还有很多,比如HuggingGPT、GPT-Engineer、LangChain、FastGPT等。目前Agent主流的决策模型是ReAct框架,也有一些ReAct的变种,其对比如下:
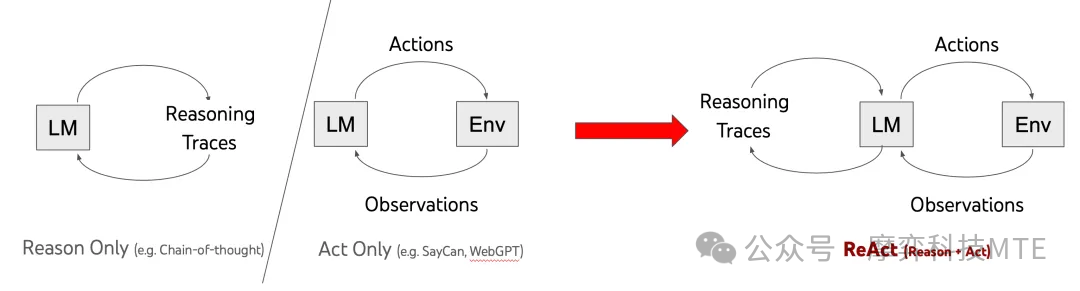
- 传统ReAct框架:Reason and Act
ReAct“=少样本prompt + Thought + Action + Observation”是调用工具、推理和规划时常用的prompt结构,先推理再执行,根据环境来执行具体的Action,并给出思考过程Thought,如下图所示:
- Plan-and-Execute ReAct框架
执行流程如下:一部分Agent通过优化规划和任务执行的流程来完成复杂任务的拆解,将复杂的任务拆解成多个子任务,再依次/批量执行。这种方式的优点是对于解决复杂任务、需要调用多个工具时,也只需要调用三次大模型,而不是每次工具调用都要调用大模型,其原理如下图所示:

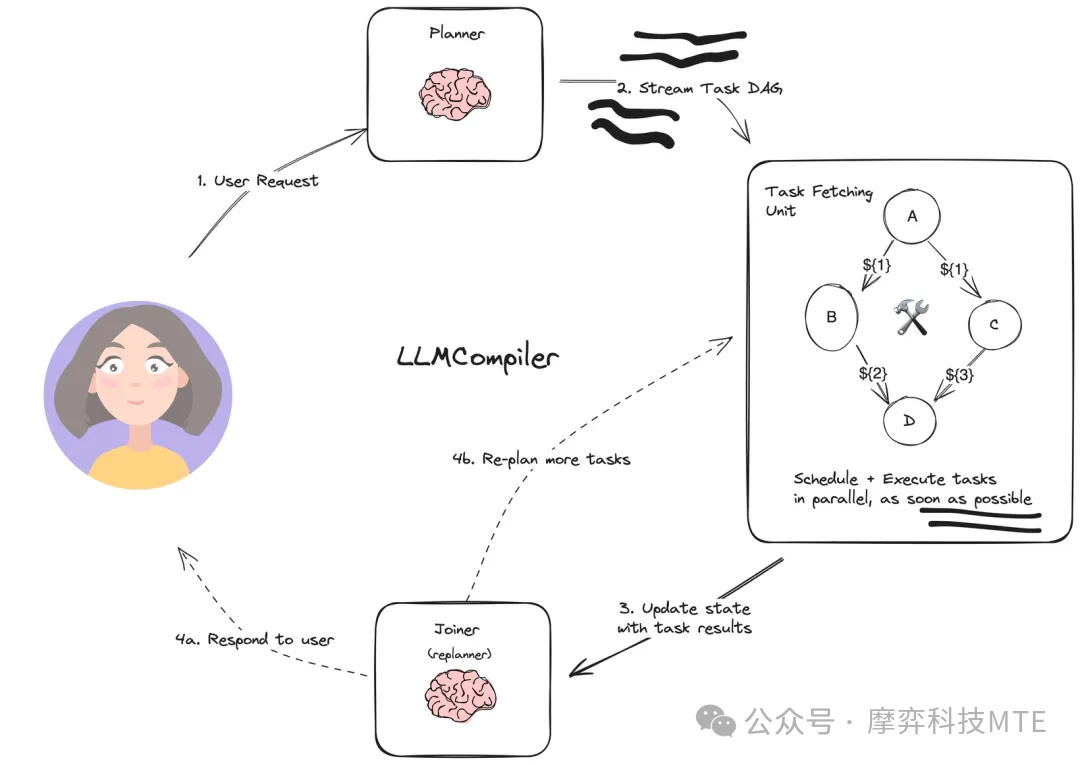
- LLMComiler框架
并行执行任务,规划时生成一个DAG图(有向无环图)来执行Action,可以理解成将多个工具聚合成一个工具执行,用图的方式执行某一个Action。
根据框架及实现方式的差异,可以将Agent框架分为两类:Single-Agent单智能体,和Multi-Agent多智能体;Multi-Agent使用多个智能体来解决更复杂的问题。
02
LLM核心技术及应用方案
LLM核心技术原理
大语言模型在很大程度上代表了一类称为Transformer网络(Google提出)的深度学习架构。Transformer模型是一个神经网络,通过跟踪序列数据中的关系来学习上下文和含义。在Transformer 出现之前,自然语言处理一般使用 RNN或CNN来建模语义信息。但RNN和CNN均面临学习远距离依赖关系的困难:RNN 的序列处理结构使较早时刻的信息到后期会衰减:而 CNN 的局部感知也限制了捕捉全局语义信息。这使 RNN 和 CNN 在处理长序列时,往往难以充分学习词语之间的远距离依赖。
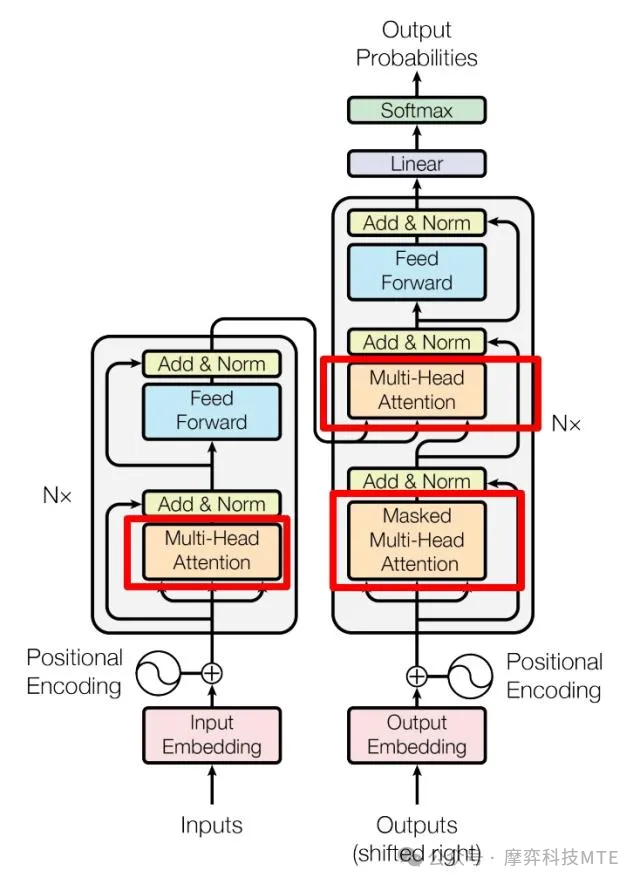
Transformer 注意力机制突破了 RNN 和 CNN 处理长序列的固有局限,使语言模型能在大规模语料上得到丰富的语言知识预训练。该模块化、可扩展的模型结构也便于通过增加模块数量来扩大模型规模和表达能力,为实现超大参数量提供了可行路径。Transformer 解决了传统模型的长序列处理难题,并给出了可无限扩展的结构,奠定了大模型技术实现的双重基础。下图是Transformer的内部结构,左侧为Encoder block,右侧为Decoder Block。红色圈中的部分为Multi-Head Attention,是由多个Self-Attention组成的,可以看到 Encoder block 包含一个Multi-Head Attention,而Decoder block包含两个Multi-Head Attention(其中有一个用到Masked)。Multi-Head Attention上方还包括一个Add&Norm层,Add表示残差连接(Residual Connection)用于防止网络退化,Norm表示Layer Normalization,用于对每一层的激活值进行归一化。关于Transformer的详细解释不是本文档的目的,读者可以通过网络地址:
(https://blog.csdn.net/xhtchina/article/details/128697238)进行详细的查看和了解。
大模型应用的核心技术
1.向量数据库/数据库向量支持
向量数据库是专门用于存储和检索向量数据的数据库,它可以为LLM提供高效的存储和检索能力。通过数据向量化,实现了在向量数据库中进行高效的相似性计算和查询。根据向量数据库的实现方式,可以将向量数据库大致分为两类:
- 原生向量数据库:专门为存储和检索向量而设计,所管理的数据是基于对象或数据点的向量表示进行组织和索引,包括Chroma、LanceDB、Milvus等。
- 添加“向量支持”的传统数据库:除选择专业的向量数据库外,对传统数据库添加“向量支持”也是主流方案,比如Redis、PostgreSQL、ElasticSearch等。
2.指令工程技术
指令工程(Prompt Engineering)是一个全面综合的过程,涵盖了人类与人工智能(AI)之间的整个交互过程。指令工程旨在确保清晰、高效、有效的与人工智能(AI)交互,同时提高用户体验。Prompt设计正在为具有明确目标的LLM创建最有效的提示。
提示具有三咱主要内容类型:输入、上下文和示例。“输入”指定模型需要生成响应的信息,可以用多种形式,例如问题、任务或实体;后两个是提示的可选部分。上下文提供有关模型行为的说明。示例是提示中的输入-输出对,用于演示预期的响应。
常见的提示设计策略可显着提高LLM的表现。提示设计策略包括清晰简洁的说明,以有效指导模型的行为。常用的先进的Prompt工程技术包括思路链(CoT)提示、思想树、主动提示、无观察推理等,具体可以参看Maithili Badhan的“Advanced Prompt Engineering Techniques”,地址如下:(https://www.mercity.ai/blog-post/advanced-prompt-engineering-techniques)。
3.表示学习和检索技术
表示学习和检索技术是互相配合的两种技术。表示学习是指将文本、图片等数据转化为数学向量,这些向量能够捕获原始数据背后中的语义信息。检索技术则是利用这些向量化后的数据进行高效查找相似内容的过程。

构建表示学习和检索系统的基本实施步骤如下:
第一步:准备知识库;
第二步:运用深度学习模型将文本或其他类型的数据转换为向量;
第三步:将这些向量存储在专属的向量数据库中;
第四步:当用户发起查询时,计算查询向量与数据库内所有向量的距离,找到最相近的结果返回结果。
4.Fine-Tuning技术
微调是在大模型框架基础上进行的一个关键步骤。在模型经过初步的大规模预训练后,微调是用较小、特定领域的数据集对模型进行后续训练,以使其更好地适应特定的任务或应用场景。这一步骤使得通用的大模型能够在特定任务上表现出更高的精度和更好的效果。微调的一般步骤:
1)选择预训练模型:选取一个已经在大量数据上进行过预训练的模型作为起点;
2)准备任务特定的数据:收集与目标任务直接相关的数据集,这些数据将用于微调模型;
3)微调训练:在任务特定数据上训练预训练的模型,调整模型参数以适应特定任务;
4)评估:在验证集上评估模型性能,确保模型对新数据有良好的泛化能力;
5)部署:将性能经验证的模型部署到实际应用中去。
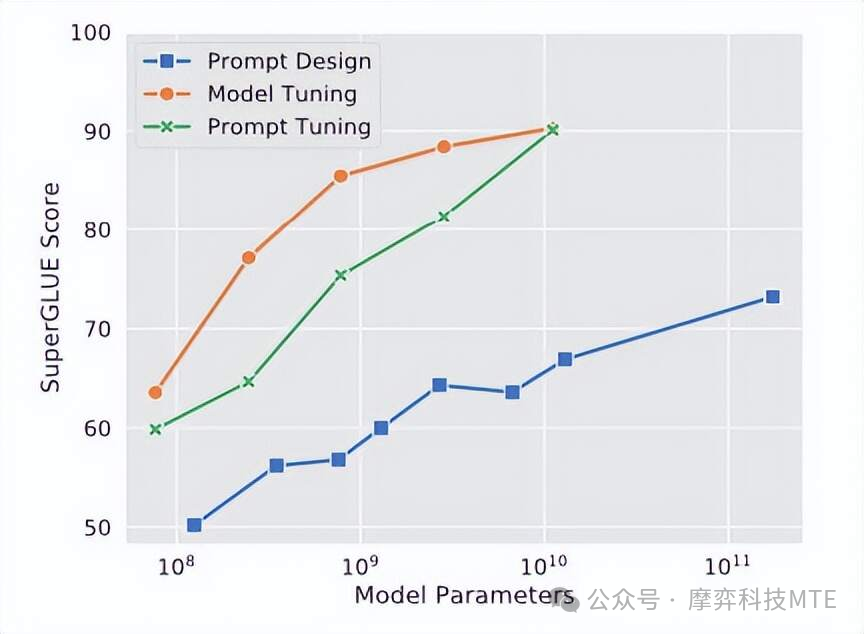
常用的一些微调方法包括LoRA(Low-Rank Adaptation)、Adapter、Prefix-tuning(前缀微调)、P-Tuning(Prompt-tuning),相应的效果如下:
私有化LLM介绍
目前,很多LLM都是通过互联网向终端用户提供服务的,但这种方式对于研究所、企业等来说可能存在着资料泄露的风险,这大大的阻碍了研究所、企业内部对LLM的研究热情和应用基础。
随着市场中对私有化部署的需要,出现了一些私有化LLM和相应部署实施方案。其中最为典型的有两个,一个是清华和智谱AI团队的ChatGLM系列,另一个是Meta的LLama系列,两者是在开源系统中目前最优秀的LMM。
1.ChatGLM3-6B
ChatGLM3是智谱AI和清华大学KEG实验室联合发布的对话预训练模型。ChatGLM3-6B是ChatGLM3系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B引入了如下特性:
a、更强大的基础模型:ChatGLM3-6B的基础模型ChatGLM3-6B-Base采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示, ChatGLM3-6B-Base具有在 10B以下的基础模型中最强的性能。
b、更完整的功能支持:ChatGLM3-6B采用了全新设计的Prompt格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和Agent任务等复杂场景。
c、更全面的开源序列:除了对话模型ChatGLM3-6B外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
2.LLama3
Llama 3是由Meta公司发布的大型语言模型,其在多个关键基准测试中性能优于业界先进同类模型,尤其在代码生成等任务上实现了全面领先。以下是关于Llama 3的详细介绍及其主要亮点:
Llama 3在技术层面实现了显著的突破。它采用了更为先进的预训练策略,使其在理解自然语言方面的能力得到了显著提升。此外,Llama 3还优化了其解码器,使得生成的文本更具逻辑性与连贯性。这些改进使得Llama 3在对话生成、问答系统等应用场景中表现出色,为用户提供了更为优质的体验。
超大规模训练数据:Llama 3基于超过15T token的训练数据,其规模相当于Llama2数据集的7倍还多。这种大规模的训练数据为模型提供了丰富的语料,使其能够更好地理解并生成自然、流畅的语言。
高效训练:与Llama 2相比,Llama 3的训练效率提高了3倍。这意味着在相同的时间内,Llama3可以完成更多的训练迭代,从而更快地提升模型的性能。
支持长文本处理:Llama3支持处理8K长文本,这使其在处理复杂、长篇的文本时具有更高的灵活性。同时,其改进的tokenizer具有128Ktoken的词汇量,可实现更好的性能。
增强的推理和代码能力:Llama 3在推理和代码生成方面表现出色,能够更遵循指令,进行复杂的推理,可视化想法并解决很多微妙的问题。
先进的安全性和信任工具:Llama 3配备了新版的信任和安全工具,包括Llama Guard 2、Code Shield和CyberSecEval 2,这些工具能够提升模型在处理各种任务时的安全性和准确性。
综合来看各类LLM的底层原理很类似,只是各家具有不同的数据集和基础设施能力,同时在一些细节的处理上会有不同的策略和方法,从而具有不同的能力。本文档后续相关内容将以ChatGLM3为标准LLM进行介绍和实践。
03
LangChain+ChatGLM3
LangChain介绍
LLMOps 平台专注于提供大模型的部署、运维和优化服务,旨在帮助企业和开发者更高效地管理和使用这些先进的 A1 模型快速完成从模型到应用的跨越,如LangChain。LangChain是一个帮助开发者使用 LLM 创建应用的开源框架,它可以将 LLM 与外部数据源进行连接,并允许与LLM进行交互。
LangChain是一个开源的语言模型工具链框架,旨在使研究人员和开发人员能够更轻松地构建、实验和部署以自然语言处理(NLP)为中心的应用程序。它提供了多种组件和工具,可帮助用户利用最近的语言模型进展,如大型 Transformer模型等,并且可以与Hugging Face等平台集成。LangChain的核心理念是将语言模型用作协作工具,通过它,开发者可以构建出处理复杂任务的系统,并且可以高效地对接不同的数据源和应用程序接口(APIs)。这个框架试图简化连接不同的输入和输出流,以及在流中实现语言模型的过程。
作为AI工程框架,LangChain实际是对LLM能力的扩展和补充。如果把LLM比作人的大脑,LangChain则是人的躯干和四肢,协助LLM完成“思考”之外的“脏活累活”。它的能力边界只取决于LLM的智力水平和LangChain能提供的工具集的丰富程度。
LangChain提供了LCEL(LangChain Expression Language)声明式编程语言,降低AI工程师的研发成本。LangChain提供了Models、Prompts、Indexes、Memory、Chains、Agents六大核心抽象,用于构建复杂的AI应用,同时保持了良好的扩展能力。
- Models模型:各种类型的模型和模型集成;LangChain中的模型主要分为三类:
1)大语言模型:这些模型将文本字符串作为输入并返回文本字符串作为输出。它们是许多语言模型应用程序的支柱。
2)聊天模型:由语言模型支持,但具有更结构化的API。他们将聊天消息列表作为输入并返回聊天消息。这使得管理对话历史记录和维护上下文变得容易。
3)文本嵌入模型(Text Embedding Models):这些模型将文本作为输入并返回表示文本购入的浮点列表。这些嵌入可用于文档检索、聚类和相似性比较等任务。
- Prompts提示:包括提示管理、提示优化和提示序列化,目前只支持字符形式的提示;
- Memory记忆:用来保存和模型交互时的上下文状态;
- Indexes索引:用来结构化文档,以便和模型交互;
- Chains链:一系列对各种组件的调用,就是将其他各个独立的组件串联起来;
- Agents智能体:决定模型采取哪些行动,执行并且观察流程,直到完成为止。
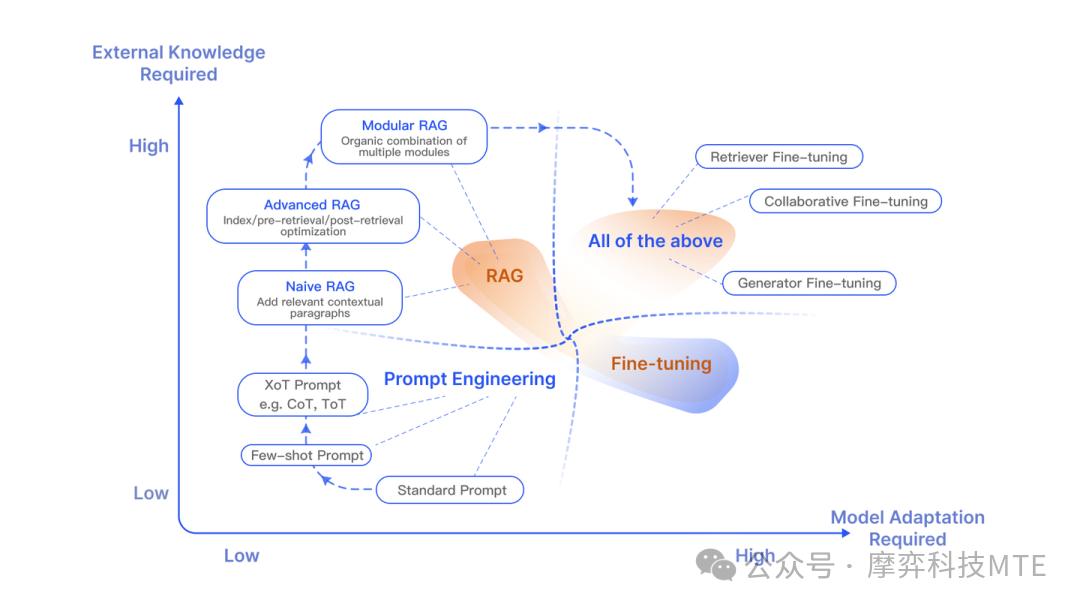
消除“幻觉”问题-RAG
拥有记忆后,确实扩展了AI工程的应用场景。但是在专有领域,LLM无法学习到所有的专业知识细节,因此在面向专业领域知识的提问时,无法给出可靠准确的回答,甚至会“胡言乱语”,这种现象称之为LLM的“幻觉”。
检索增强生成(RAG)把信息检索技术和大模型结合起来,将检索出来的文档和提示词一起提供给大模型服务,从而生成更可靠的答案,有效的缓解大模型推理的“幻觉”问题。如果说LangChain相当于给LLM这个“大脑”安装了“四肢和躯干”,RAG则是为LLM提供了接入“人类知识图书馆”的能力。

相比提示词工程,RAG有更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,即能生成比较符合用户预期的答案。相比于模型微调,RAG可以提升问答内容的时效性和可靠性,同时在一定程度上保护了业务数据的隐私性。
但由于每次问答都涉及外部系统数据检索,因此RAG的响应时延相对较高。另外,引用的外部知识数据会消耗大量的模型Token资源。因此,用户需要结合自身的实际应用场景做合适的技术选型。
RAG核心的最关键部分是通过context键注入向量存储(Vector Store)的查询器(Retriever),过程如下图所示:
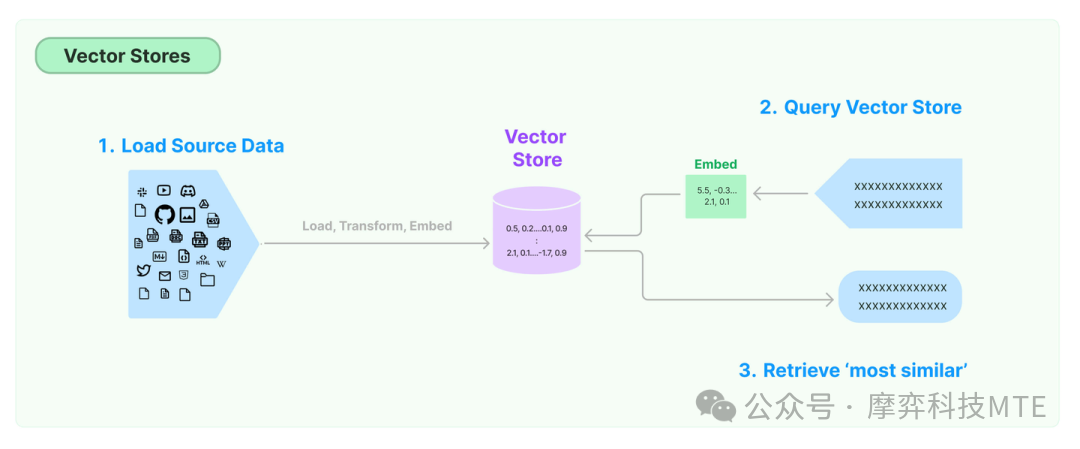
- DocumentLoader:从外部系统检索文档数据。简单起见,示例中直接构造了测试文档对象。实际上LangChain提供了文档加载器BaseLoader的接口抽象和大量实现,具体可根据自身需要选择使用。
- TextSplitter:将文档分割成块,以适应大模型上下文窗口。示例中采用了常用的RecursiveCharacterTextSplitter,其他参考LangChain的TextSplitter接口和实现。
- EmbeddingsModel:文本嵌入模型,提供将文本编码为向量的能力。文档写入和查询匹配前都会先执行文本嵌入编码。示例采用了OpenAI的文本嵌入模型服务,其他参考LangChain的Embeddings接口和实现。
- VectorStore:向量存储,提供向量存储和相似性检索(ANN算法)能力。LangChain支持的向量存储参考VectorStore接口和实现。示例采用了Meta的Faiss[14]向量数据库,本地安装方式:pip install faiss-cpu。需要额外提及的是,对于图数据库,可以将相似性搜索问题转化为图遍历问题,并具备更强的知识可解释性。蚂蚁开源的TuGraph数据库[15]目前正在做类似的技术探索。
- Retriever:向量存储的查询器。一般和VectorStore配套实现,通过as_retriever方法获取,LangChain提供的Retriever抽象接口是BaseRetriever。
走向智能-Agent
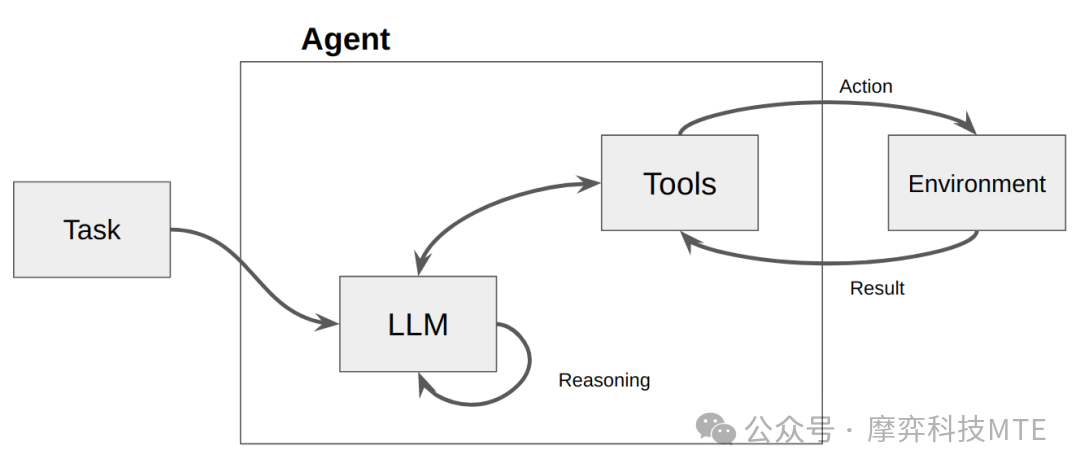
Agent的核心思想是使用大型语言模型(LLM)来选择要采取的行动序列。在Chain(链条)中行动序列是硬编码的,而Agent则采用语言模型作为推理引擎来确定以什么样的顺序采取什么样的行动。
Agent相比Chain最典型的特点是“自治”,它可以通过借助LLM专长的推理能力,自动化地决策获取什么样的知识,采取什么样的行动,直到完成用户设定的最终目标。
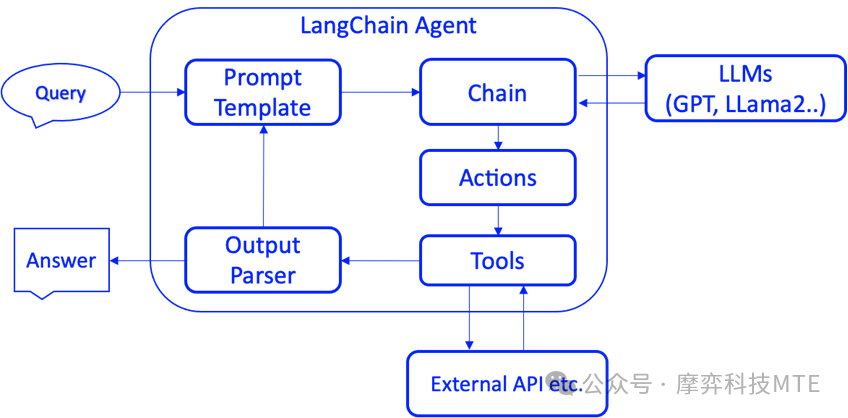
作为一个智能体,需要具备以下核心能力:
规划:借助于LLM强大的推理能力,实现任务目标的规划拆解和自我反思。
记忆:具备短期记忆(上下文)和长期记忆(向量存储),以及快速的知识检索能力。
行动:根据拆解的任务需求正确地调用工具以达到任务的目的。
协作:通过与其他智能体交互合作,完成更复杂的任务目标。
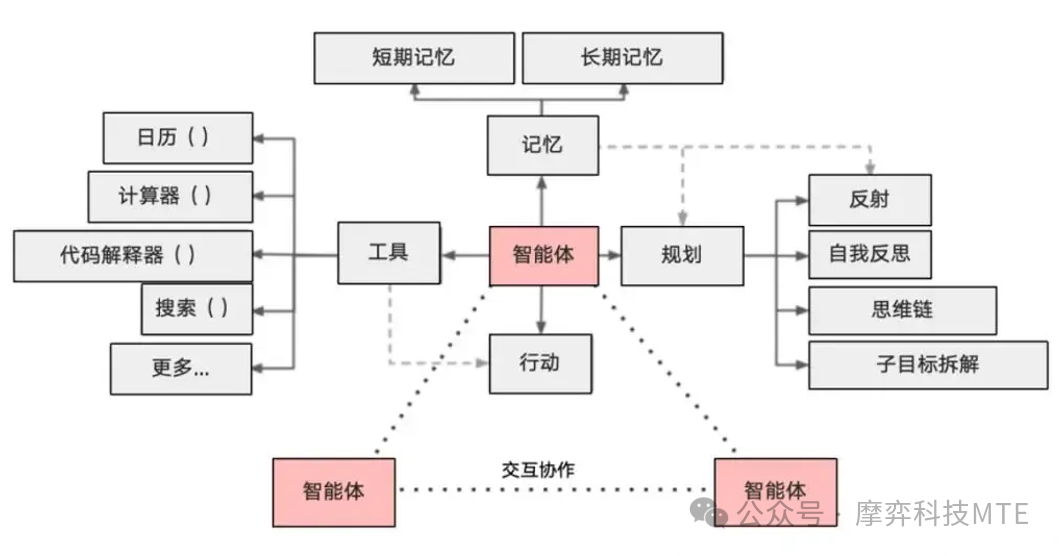
Agents 的工作流程:通过结合大型语言模型(LLM)的推理能力和外部工具的执行能力,接收任务后进行思考、行动、接收反馈并重复这些步骤,直至任务完成或达到终止条件。Agents 流程包含以下四个核心步骤:
接收任务:LLM Agent首先接收一个任务描述或问题。
思考:然后,它利用LLM进行推理和决策。例如,它可能会生成一个潜在的解决方案或行动计划。
行动:接下来,LLM Agent会执行一些操作以完成任务。这些操作可能包括调用API获取数据、查询数据库、执行计算等。
接收反馈:在执行操作后,LLM Agent会接收来自环境的反馈。这些反馈可能包括API的响应、数据库查询的结果等。
如果任务还没有完成,LLM Agent会重复上述步骤,直到任务完成或达到某个终止条件。
在LangChain中,Agent Types定义了不同类型的代理(Agents),这些代理使用不同的策略和方法来与用户和工具进行交互,以完成各种任务。
**Zero-shot ReAct**:****这种Agent使用ReAct(Retrieve-and-Act)框架,该框架通过理解工具的描述来选择最合适的工具执行任务。Zero-shot意味着Agent不需要针对特定任务进行训练,而是可以基于工具的描述直接进行推断。
**Structured tool chat**:****这种Agent支持使用具有复杂输入参数的工具。通过定义args_schema,Agent可以理解每个工具所需输入参数的结构和类型,从而与用户进行更结构化的对话以收集必要的信息。这有助于确保与工具的交互是准确和一致的。
**Conversational**:****与标准ReAct Agent相比,Conversational Agent更注重与用户进行自然对话。它的提示和响应设计得更加对话性,适合在聊天场景中使用。
**Self-ask with search**:****这种Agent类型集成了搜索功能,允许它自主地在搜索引擎中查找信息以回答问题。这增加了Agent的知识来源和回答问题的能力。
**ReAct document store**:****使用这种Agent,用户可以与一个文档存储进行交互。该Agent包含两个关键工具:“Search”用于在文档存储中搜索相关文档,“Lookup”用于在最近找到的文档中查找特定术语或信息。
**XML Agent**:****专门用于处理XML格式的数据。它使用XML格式来解析工具调用和最终答案,这使得它特别适合与返回XML响应的工具或服务进行交互。
LangChain+ChatGLM3方案
LangChain+ChatGLM3是一种利用LangChain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。该方案是一个可以实现“完全本地化”推理的知识库增强方案,重点解决数据安全保护,私域化部署的企业痛点。本开源方案采用ApacheLicense,可以免费商用,无需付费。目前支持市面上主流的本地大语言模型(可换成LLama3等)和Embedding模型,支持开源的本地向量数据库。
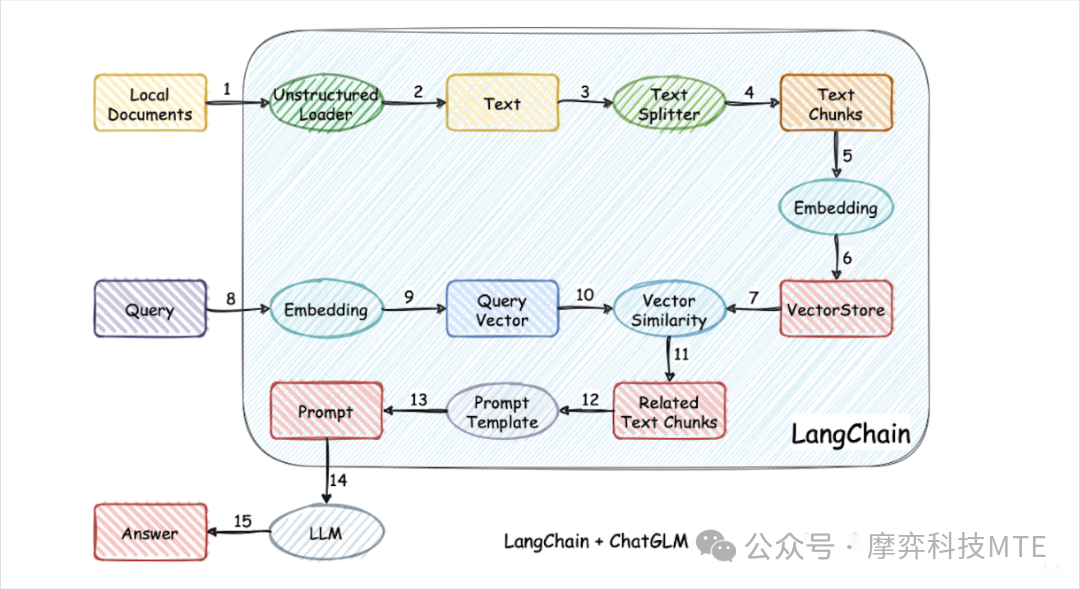
本方案实现原理如下图所示,过程包括加载文件->读取文本->文本分割->文本向量化->问句向量化->在文本向量中匹配出与问句向量最相似的topk个->匹配出的文本作为上下文和问题一起添加到 prompt中->提交给LLM生成回答。
04
系统安装及初步效果展示
系统搭建步骤
基于前面研究利用LangChain+ChatGLM3进行了系统的搭建,安装可以分为在线安装和离线安装。针对研究所的使用环境(无法连接互联网),下面主要以离线安装进行简要介绍,主要的步骤如下所示:
(1)下载相应的软件安装包和环境,包括cuda+cudnn(主要是GPU驱动和相关运行环境)、PyCharm(Python程序开发IDE)、LangChain-Chatchat-Master.rar(LangChain环境);
(2)使用Nvidia-smi查看cuda版本;解压并安装Cudnn(LLM推理使用);
(3)根据提示以管理员身份安装Anaconda和PyCharm;
(4)建立Python虚拟环境,将LangChain环境包拷贝并解压出来;
(5)解压Langchain-Chatchat-Master,并利用PyCharm打开Langchain-chatchat-master,并设置虚拟环境为LangChain。
运行startup.py,启动系统进入主界面。
LangChain-Chatchat默认使用的LLM模型为THUDM/chatglm2-6b,默认使用的Embedding模型为moka-ai/m3e-base为例。除本地模型外,本项目也支持直接接入OpenAI API,具体设置可参考configs/model_configs.py中的 llm_model_dict的openai-chatgpt-3.5配置信息。
知识库应用示例
(1)在搭建完成的系统上以“机电系统故障诊断”为主题下载了相关资料,并进行资料上传解析及相关效果的分析。点击知识管理,进入如下界面:
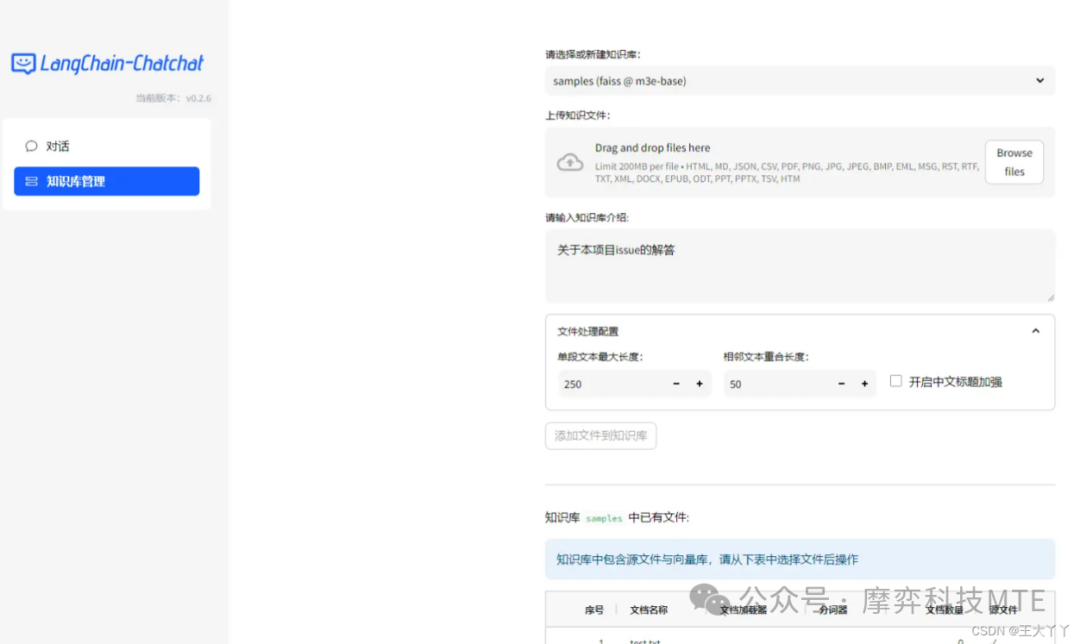
(2)在【请选择或新建知识库】中新建一个知识库,添加名称(目前仅支持英文);
(3)点击【上传知识文件】的【Browser Files】,在打开对话框中选择要解决的文件;
(4) 填写知识库介绍,并设置文件处理配置参数等后,点击【添加文件到知识库】;
(5)系统后台运行程序解析文件数据生成文本向量并存储到向量数据库;
(6)用户切换到对话模式中就可以选择构建的知识库进行问答,系统将给出知识库中答案和LLM的答案。
关于API或工具调用
大语言模型ChatGLM3和Langchain都支持对API和工具的调用,具体的体现如下:
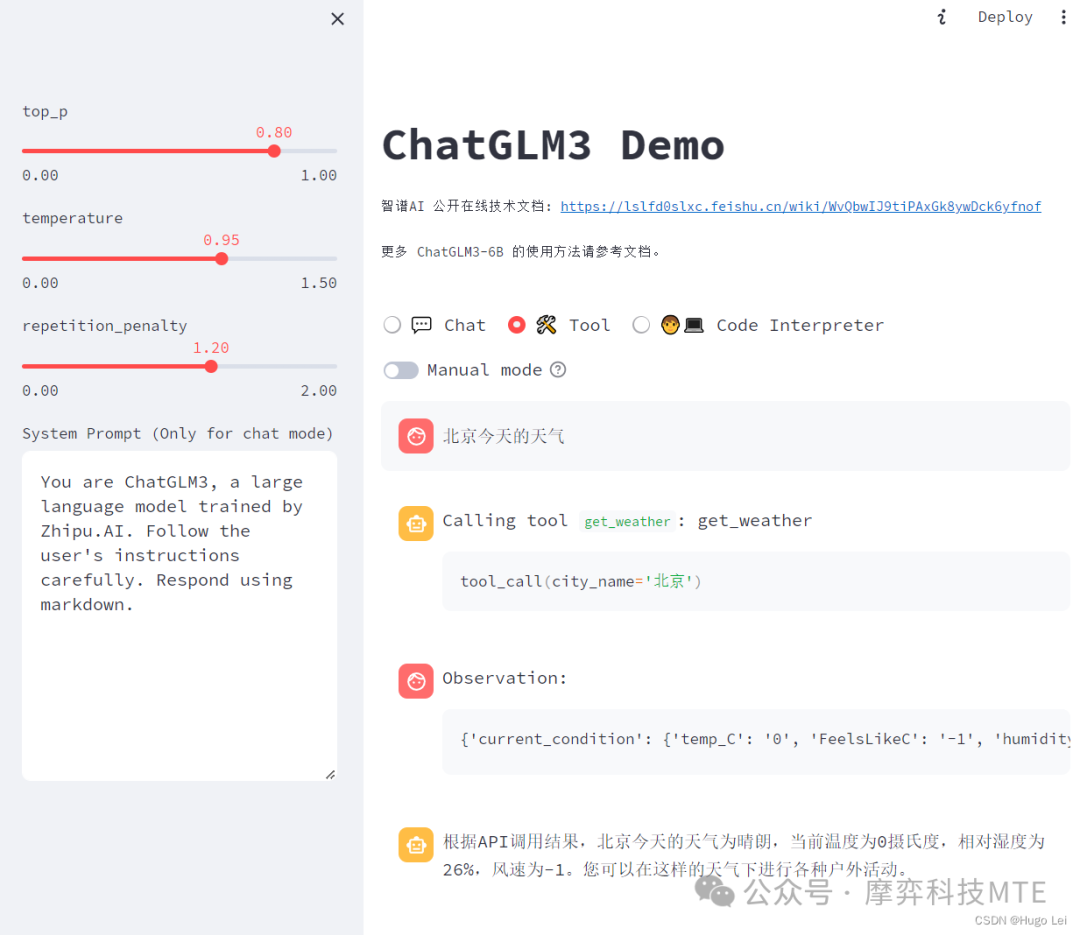
1.ChatGLM3-6B的函数调用模式示例
register_tool的功能是将自定义的函数,转化为大模型需要的格式
@register_tool
def get_weather(
city_name: Annotated[str, ‘The name of the city to be queried’, True],
) -> str:
“”"
Get the current weather for city_name
“”"
if not isinstance(city_name, str):
raise TypeError(“City name must be a string”)
key_selection = {
“current_condition”: [“temp_C”, “FeelsLikeC”, “humidity”, “weatherDesc”, “observation_time”],
}
import requests
try:
resp = requests.get(f"https://wttr.in/{city_name}?format=j1")
resp.raise_for_status()
resp = resp.json()
ret = {k: {_v: resp[k][0][_v] for _v in v} for k, v in key_selection.items()}
except:
import traceback
ret = “Error encountered while fetching weather data!\n” + traceback.format_exc()
return str(ret)
//函数注解@register_tool
register_tool的功能是将自定义的函数,转化为大模型需要的格式。
2.Langchain的Agent示例
使用LangChain库创建一个简单的代理(agent),该代理能够处理数学运算任务。
一、创建工具函数:通过装饰器 @tool 创建了三个工具函数:multiply(乘法)、add(加法)和exponentiate(指数运算)。这些函数接收整数作为参数,并返回运算结果。

二、创建提示模板:从LangChain Hub中获取一个提示模板。这个模板用于指导大型语言模型(LLM)如何生成响应。

三、创建代理和执行器:选择一个大型语言模型来驱动代理。使用所选的模型、工具函数和提示模板来构建OpenAI Tools代理。同时,创建一个代理执行器,将代理和工具函数传递给它。

四、调用代理: 代理会根据输入和提示模板动态地调用适当的工具函数来完成运算,并返回运算结果。
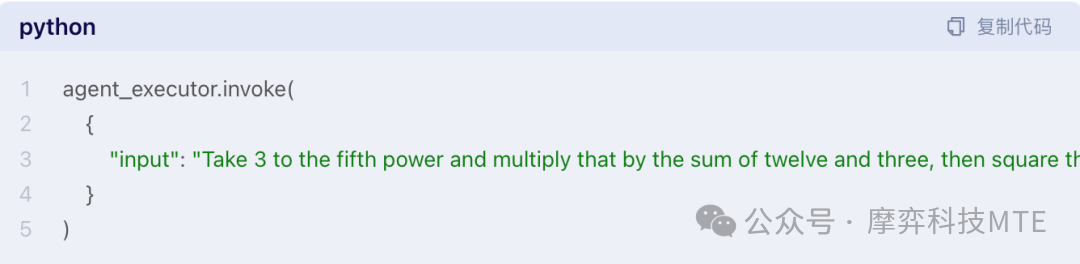
下面也是一个使用ChatGLM来理解问题,并通过LangChain的Agnets机制来调用外部工具的示例。
from langchain.llms import ChatGLM
from langchain.experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from tools import LlmModelTool, VectorSearchTool
#default endpoint_url for a local deployed ChatGLM api server
endpoint_url = “http://12.0.59.21:8888”
llm = ChatGLM(
endpoint_url=endpoint_url,
max_token=80000,
history=[],
model_kwargs={“sample_model_args”: False},
temperature=0.95
)
# when giving tools to LLM, we must pass as list of tools
tools = [LlmModelTool(), VectorSearchTool()]
#T计划执行代理人(Plan-and-execute agents)
planner = load_chat_planner(llm)
executor = load_agent_executor(llm, tools, verbose=True)
#工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.run(input=“请帮我制定一份8月去西藏旅游的计划?”)
05
小结及后续规划
通过前期对大语言模型、RAG、多智能体等进行了理论和框架的研究表明相关技术在工程应用中落地初步具备了一定的可行性。但这块涉及的内容很多,因此还有很多方面没有进行深入的研究和实践,接下来的主要任务包括:
1.深入RAG各环节中具体技术的适应情况的研究,明确采用哪些技术能够生成更好知识向量,并能够更加精准的进行检索等;
2.对LLM的函数调用、智能体代理对Tool调用进行深入研究,尝试结合实际业务需求进行相关控制调用。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 481
481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









