






1. 前言
随着LLM的发展和应用,在LLM的预训练模型基础上做微调,使其适用于自己的业务场景的研究越来越多。与全参数SFT相比LoRA是在冻结LLM本身参数的基础上,在旁路增加两个可学习的矩阵,用于训练和学习,最后推理是LLM输出和可学习的矩阵的输出相加,得到最终的输出。它与全参数微调方法区别是:
资源上的差异:
- • 全参数微调:需要加载和更新全部LLM参数,需要更高的显存(需要的显存一般是单一参数的4倍),数据量上也需要更多的微调数据;
- • LoRA:只需要加载LLM参数,训练两个可学习的低秩矩阵,显存和数据量要求较低,训练速度也更快;
效果上差异:
- • 全参数微调:存在灾难性遗忘的风险,理论效果上限更高;
- • LoRA:和全参数微调效果差距不大,稳定性和扩展性更好;
2. LoRA原理
LoRA低秩适应微调,该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
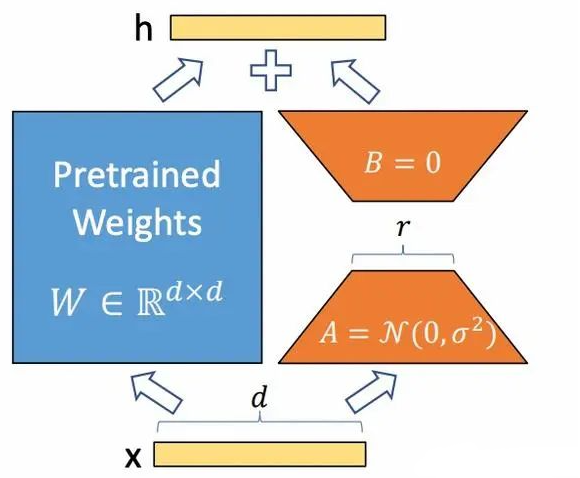
它的做法是:

3. LoRA的变种
QLoRA
与LoRA相比:LLM模型采用4bit加载,进一步降低训练需要显存。
QLoRA是进一步降低了微调需要的显存,QLoRA是将模型本身用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA可以锁定原模型参数不参与训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。
LoRA+
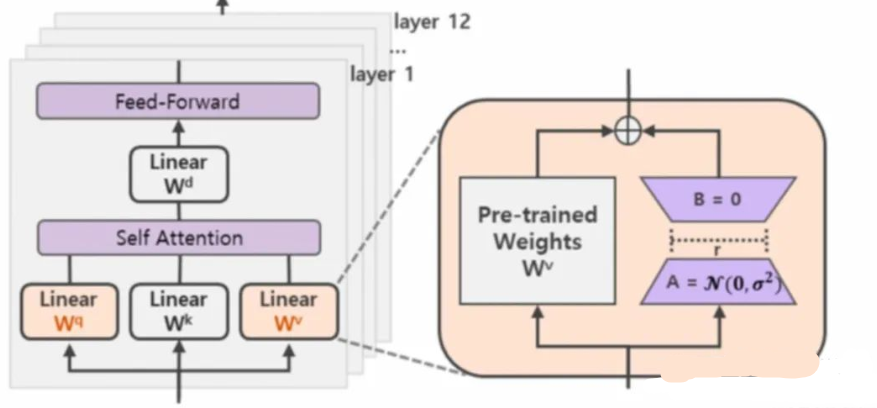
与LoRA相比:AB矩阵采用不同的学习率;AB矩阵应用到全部参数矩阵。
LoRA+通过为矩阵A和B引入不同的学习率,更有效的训练LoRA适配器。LoRA在训练神经网络时,学习率是应用于所有权重矩阵(包括embeded和normalization层)。而LoRA+的作者可以证明,只有单一的学习率是次优的。将矩阵B的学习率设置为远高于矩阵A的学习率,可以使得训练更加高效。

LoRA-FA
与LoRA相比:仅训练B矩阵。
LoRA-FA是LoRA与Frozen-A的缩写,在LoRA-FA中,矩阵A在初始化后被冻结,矩阵B是在用零初始化之后进行训练(就像在原始LoRA中一样)。这将参数数量减半,同时具有与普通LoRA相当的性能。
LoRA-drop
LoRA矩阵可以添加到神经网络的任何一层,LoRA-drop则引入了一种算法来决定哪些层由LoRA微调,哪些层不需要。
LoRA-drop步骤:
- • 1.对数据的一个子集进行采样,训练LoRA进行几次迭代;
- • 2.将每个LoRA适配器的重要性计算为BAx,其中A和B是LoRA矩阵,x是输入;
- • 3.如果这个输出很大,说明它会更剧烈地改变行为,如果它很小,这表明LoRA对冻结层的影响很小可以忽略;
- • 4.可以汇总重要性值,直到达到一个阈值(这是由一个超参数控制的),或者只取最重要的n个固定n的LoRA层;
- • 5.最后在整个数据集上进行完整的训练,其他层固定为一组共享参数,在训练期间不会再更改。
LoRA-drop算法允许只使用LoRA层的一个子集来训练模型。根据作者提出的证据表明,与训练所有的LoRA层相比,准确度只有微小的变化,但由于必须训练的参数数量较少,因此减少了计算时间。
AdaLoRA
在LoRA-drop中作者根据LoRA适配器的重要程度,选择部分不重要的LoRA不参与训练。而AdaLoRA作者则是根据重要程度,选择不同LoRA适配器调整秩的大小(原始LoRA所有层秩都一样)。另外AdaLoRA是根据LoRA矩阵的奇异值作为重要程度指标的。
AdaLoRA与相同秩的标准LoRA相比,两种方法总共有相同数量的参数,但这些参数的分布不同。在LoRA中,所有矩阵的秩都是相同的,而在AdaLoRA中,有的矩阵的秩高一些,有的矩阵的秩低一些,所以最终的参数总数是相同的。经过实验表明AdaLoRA比标准的LoRA方法产生更好的结果,这表明在模型的部分上有更好的可训练参数分布,这对给定的任务特别重要。
DoRA
通常认为LoRA等微调技术不如正常微调(Finetune)的原因是,LoRA被认为是对Finetune微调的一种低秩近似,通过增加Rank,LoRA可以达到类似Finetune的微调效果。但是作者发现LoRA的学习模式和FT很不一样,更偏向于强的正相关性,即方向和幅度呈很强的正相关,这可能对更精细的学习有害。
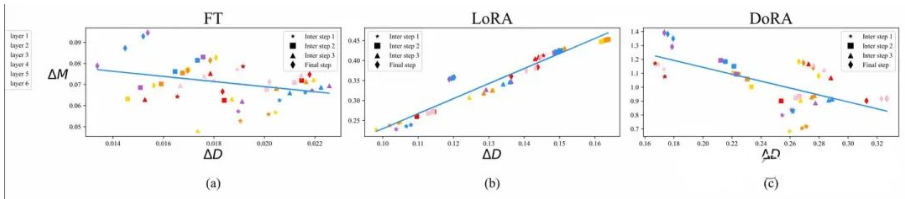
图中x轴是模型更新方向,y轴是幅度变化,图中的散点是每一层。可以看到FT的训练方式,更新的方向和幅度并没有太大关系(或者小的负相关),而LoRA存在较强的正相关性。
哪一种方向和幅度相关性更好?
这个不确定,但是LoRA的目的是利用较小参数达到和FT一致的效果,所以从相关性上应该LoRA的应该更像FT。所以作者将预训练参数矩阵进行分解,分解成包括大小(magnitude)和方向(directional)两个向量,只在方向上应用LoRA微调。
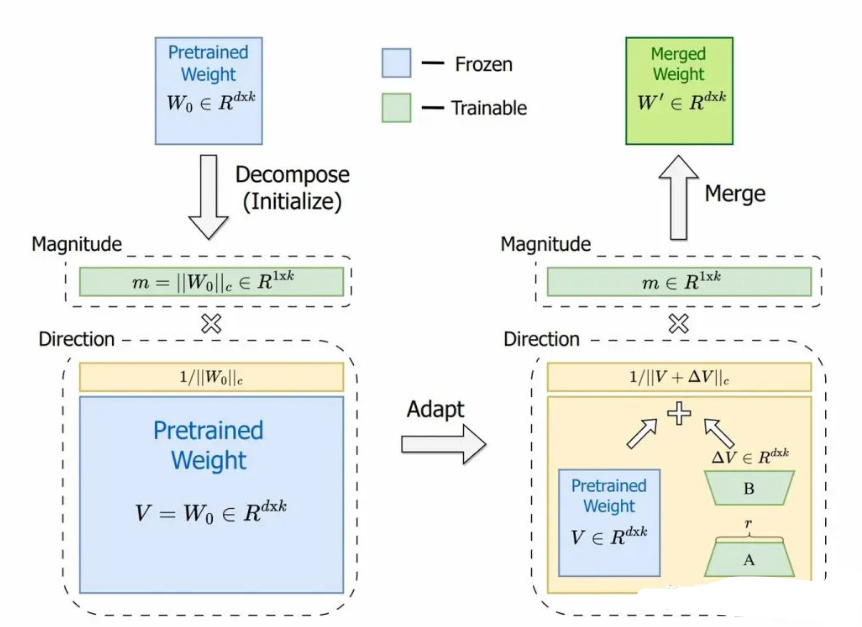
DoRA的作者通过将预训练矩阵W分解,得到大小为1 x d的大小向量m和方向矩阵V,从而独立训练大小和方向。然后方向矩阵V通过B* A增强(LoRA),然后m按原样训练。虽然LoRA倾向于同时改变幅度和方向(正如这两者之间高度正相关所表明的那样),DoRA可以更容易地将二者分开调整,或者用另一个的负变化来补偿一个的变化。所以可以DoRA的方向和大小之间的关系更像微调。代码如下
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import torch
import torch.nn as nn
import torch.nn.functional as F
# This layer is dropped into your pre-trained PyTorch model where nn.Linear is used
class DoRALayer(nn.Module):
def __init__(self, d_in, d_out, rank=4, weight=None, bias=None):
super().__init__()
if weight is not None:
self.weight = nn.Parameter(weight, requires_grad=False)
else:
self.weight = nn.Parameter(torch.Tensor(d_out, d_in), requires_grad=False)
if bias is not None:
self.bias = nn.Parameter(bias, requires_grad=False)
else:
self.bias = nn.Parameter(torch.Tensor(d_out), requires_grad=False)
# m = Magnitude column-wise across output dimension
self.m = nn.Parameter(self.weight.norm(p=2, dim=0, keepdim=True))
std_dev = 1 / torch.sqrt(torch.tensor(rank).float())
self.lora_A = nn.Parameter(torch.randn(d_out, rank)*std_dev)
self.lora_B = nn.Parameter(torch.zeros(rank, d_in))
def forward(self, x):
lora = torch.matmul(self.lora_A, self.lora_B)
adapted = self.weight + lora
column_norm = adapted.norm(p=2, dim=0, keepdim=True)
norm_adapted = adapted / column_norm
calc_weights = self.m * norm_adapted
return F.linear(x, calc_weights, self.bias)
LongLoRA
LongLoRA 是港中文和 MIT 在 23 年发表的一篇 paper,主要是为了解决长上下文的注意力机制计算量很大的问题。
LLM支持长文本的方法,包括利用NTK等方式进行外推和内插(可参考:位置编码(下)[1],但为了让模型表现更好,一般还会进行微调。LongLoRA的要点:
- • 1.S2-attn注意力:这一点与LoRA无关,是为解决长序列注意力成二次方增加的问题,S2-attn在训练时不计算全局的注意力,而是将所有token分组,每个token只计算该组和相邻组的注意力,降低显存消耗,提升训练速度。(和longformer、Big Bird等处理长文本注意力方法没有太大区别,都是只算该token附近的注意力);
- • 2.LoRA训练(变种):在潜入层、归一化层也都加入了LoRA权重进行训练;
总结
LoRA系列大模型微调方法是大模型PEFT非常重要的一个研究方向,也是目前工程届应用最广法的微调方法之一,基于LoRA的改进的论文和方法还在不断更新。
引用链接
[1] 位置编码(下): https://zhuanlan.zhihu.com/p/720755157
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
下面这些都是我当初辛苦整理和花钱购买的资料,现在我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









