






什么是微调7
模型微调,是在通用大语言模型(比如deepseek,qwen,llama,豆包)基础上,针对特定任务,使用特定的数据来训练,让它在这个任务上表现更优秀。用人话来说就是,用目标数据来训练它让它更符合我们的目标。
为什么要微调
比如一个通用大语言模型在大规模通用文本上训练,能学习到通用语言特征。但电商评论情感分析场景下,直接使用效果不好。微调时加入电商评论数据,模型可学习到 “颜值高”,“物流慢”,“卖家秀” 等特定领域情感表达模式,从而更精准判断评论情感倾向。
虽然这篇文章写的是微调,但模型效果不好,需要分析原因,沿着下面这个思路来优化
-
提示词优化,在大语言模型提示词永远是第一位的,提示词是激发模型小宇宙的一把金钥匙。
-
利用RAG,整合自己的知识库,为模型提供私有领域的知识,比如说公司的管理制度和组织架构(董事长是谁,总经理是谁。。。)
-
智能体和工作流,最大程度把大模型和外部能力结合起来,比如,查询北京明天的天气,为用户制定北京的旅游计划。这里面【北京明天的天气】,是所有大模型都不知道的信息,要通过外部接口让模型知道了北京天气,然后根据天气情况来设计攻略。
如果前面的方法不管用,最后一步才是模型调优,而模型调优的首选方式就是微调。
顺便说一句,微调后的模型,依然可以和提示词优化,RAG,智能体和工作流一起使用。
开始动手
这个微调的案例来自于硅基流动,没错,就是这段时间因为deepseek广为人知的硅基。
但是这个案例我在硅基上居然训练失败,一开始以为是赠送金额不能用于微调,充了值以后还是不成功(心疼我的10块钱 ),提交了工单也没人理我。
),提交了工单也没人理我。
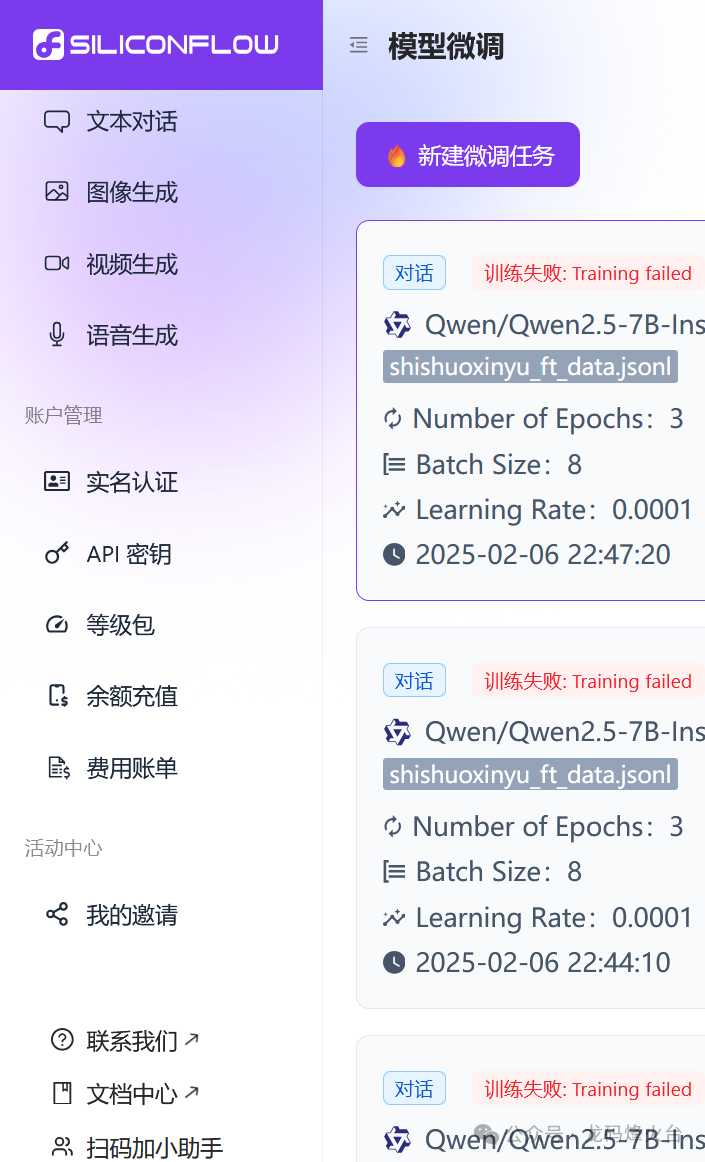
硅基不行,那就去找别人吧:阿里云百炼。
-
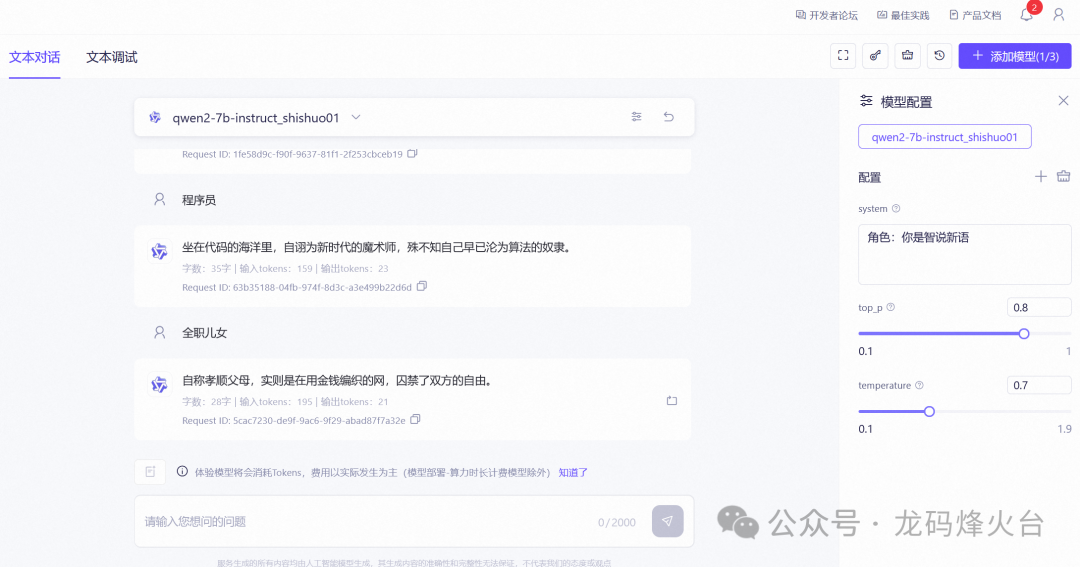
微调的目标
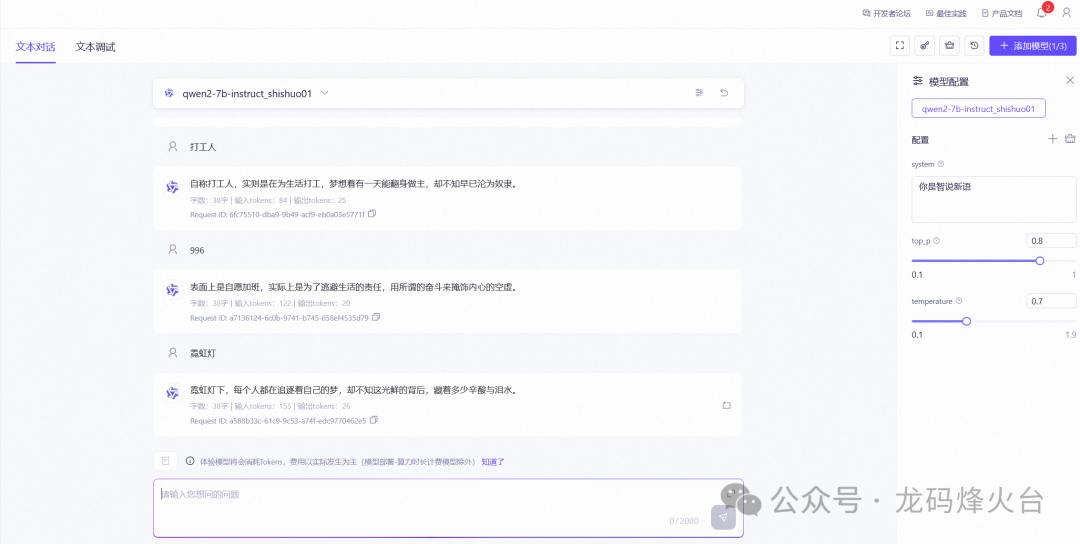
智说新语,让大模型为输入的名词自动造一个“金句”,下面是效果图
直接开干
训练数据长这样,完整的数据地址在下面
{"messages": [{"role": "system", "content": "你是智说新语生成器"}, {"role": "user", "content": "鞋易净"}, {"role": "assistant", "content": "鞋面光鲜亮丽,却掩不住脚下的泥泞之路。"}]}
{"messages": [{"role": "system", "content": "你是智说新语生成器"}, {"role": "user", "content": "提示词赛道"}, {"role": "assistant", "content": "赛道上人人争先恐后,以为奔跑就能抵达终点,却不知真正的胜负早已在起跑线上划定。"}]}{"messages": [{"role": "system", "content": "你是智说新语生成器"}, {"role": "user", "content": "产品经理"}, {"role": "assistant", "content": "产品经理,一边吹嘘着用户体验至上的圣歌,一边悄悄在后台数着广告点击的金币。"}]}
{"messages": [{"role": "system", "content": "你是智说新语生成器"}, {"role": "user", "content": "信息数字化科"}, {"role": "assistant", "content": "数据的洪流中,我们自以为驾驭了知识的航船,殊不知早已成了算法的奴隶。"}]}
微调要花钱,确保阿里云账户有钱,我有优惠券,这次微调账单才几毛钱。
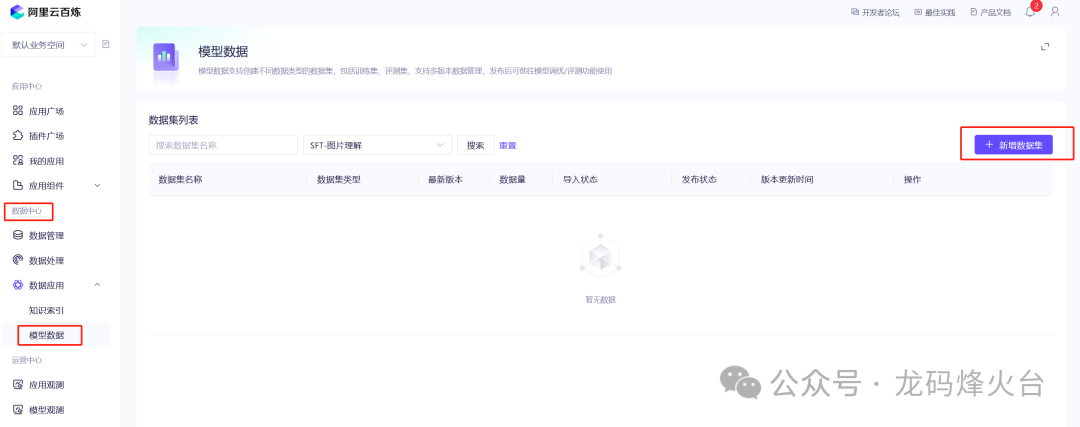
进入阿里云百炼控制台,
先到数据中心,把训练数据上传到百炼
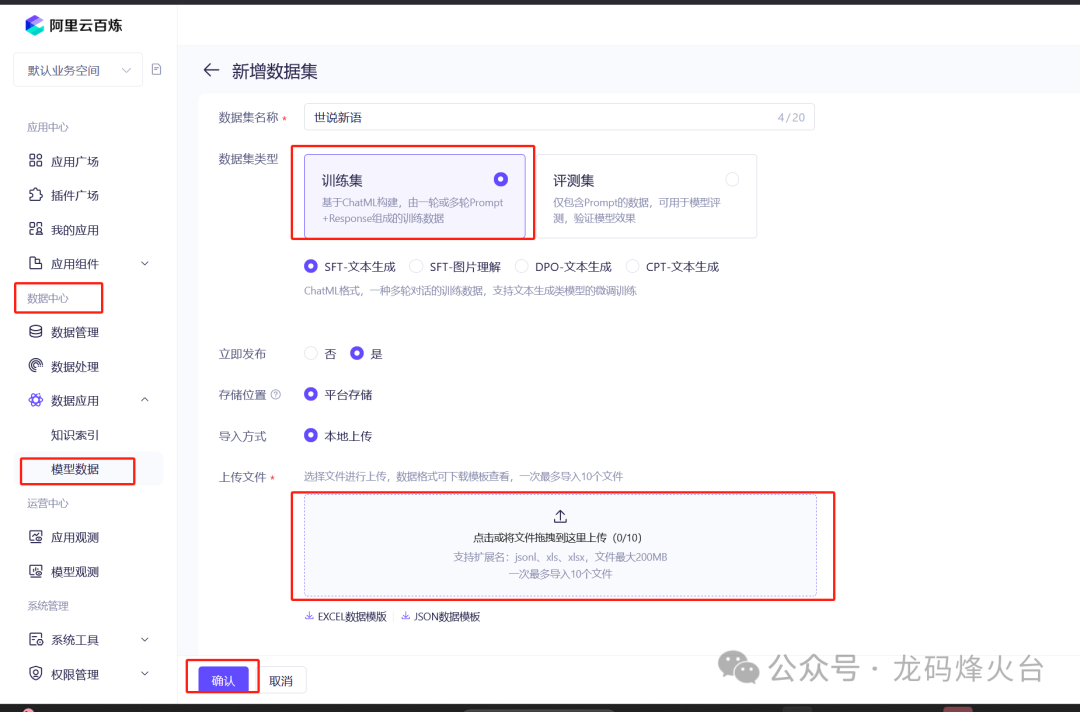
然后选择 模型工具-模型调优-训练新模型
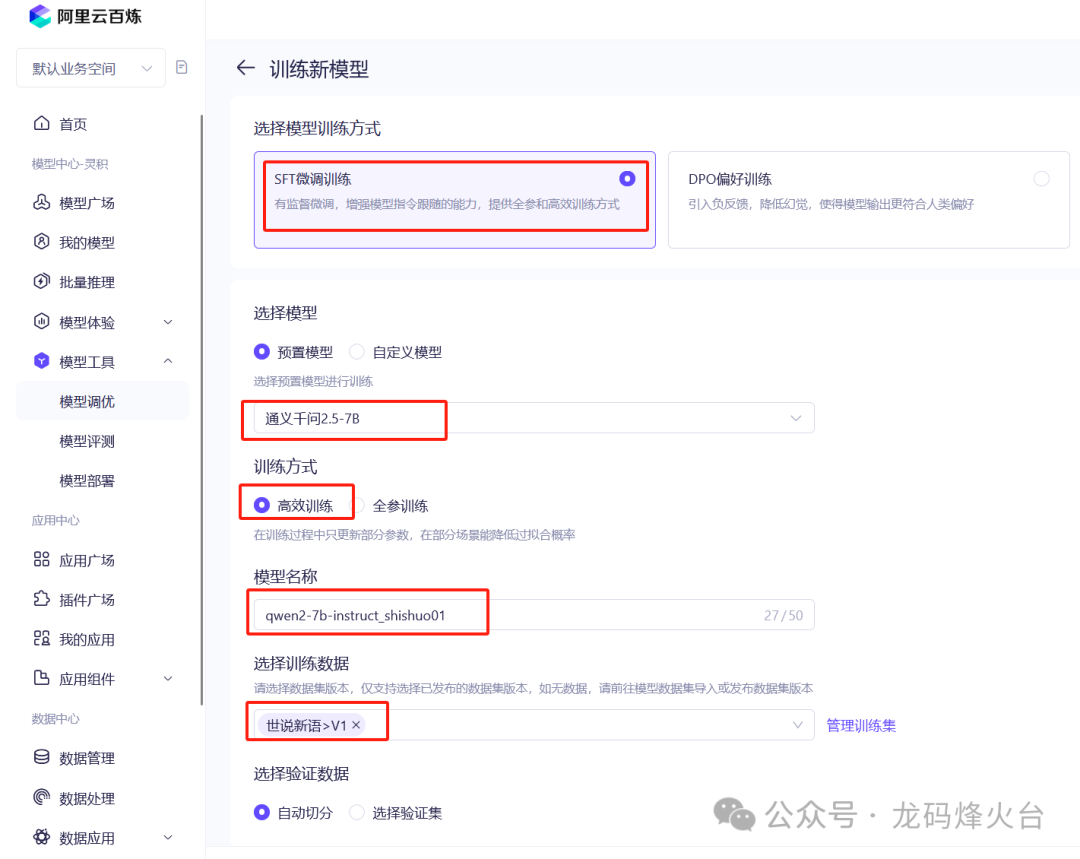
训练方案:必须是SFT微调训练
训练模型:通义千问2.5-7B。7B的小模型,训练费用便宜,模型太大了,耗费的token也多,费用也高。
训练方式:必须选择高效训练。为什么不用全参训练,后面再展开来说。
**模型名称:起一个容易理解的。
**
训练数据:就用刚刚上传的那份数据集。
其它训练超参数保持默认就行。
开始训练,等待训练成功
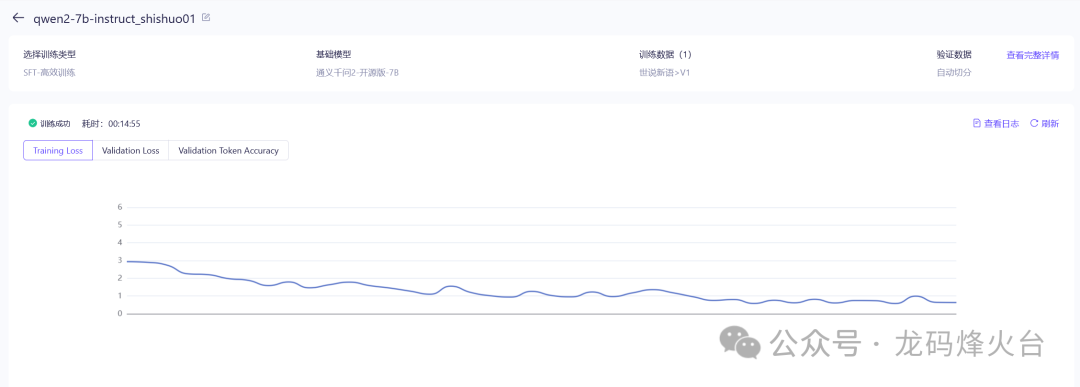
微调训练成功后,就有了一个“新模型” ,接下来就是部署。
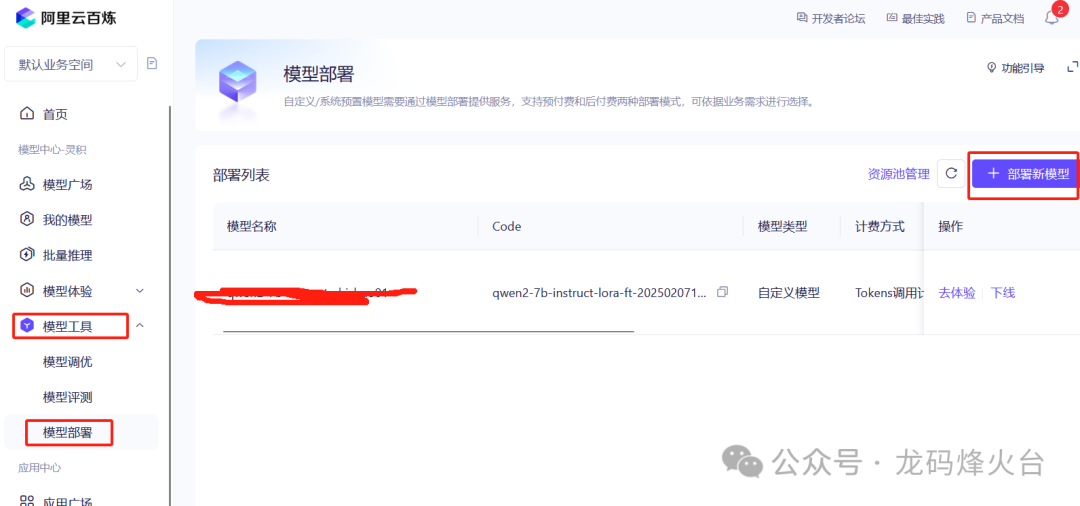
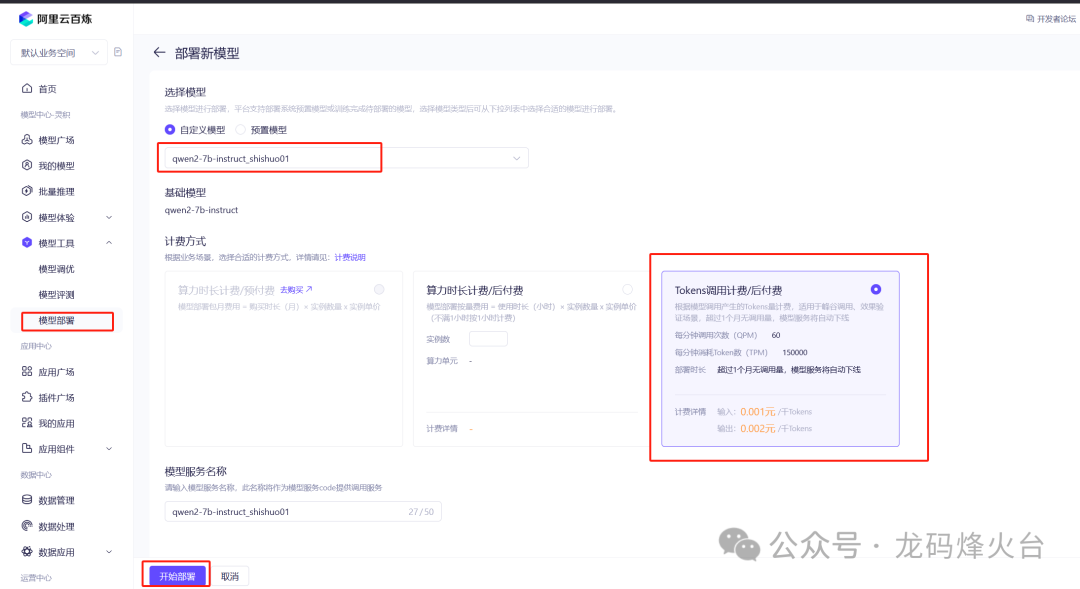
在百炼部署一个模型很简单,选择微调后的模型,计费方式选择token后付费,用多少给多少。高效训练策略的模型部署很快的,几分钟就成功。
部署成功了,可以在线体验
后话
- 训练方式为什么不选择全参
模型调优,有全参和微调,微调就是冻结一部分网络层,只需要调整少部分网络层。
全参,一般需要比较大量的数据,数量太少效果不好。全参也以为着全部参数会发生改变,训练后需要把整个大模型给部署起来,费用不低,阿里云针对**全参训练的模型不运行使用token后付费方式部署。
高效训练使用LoRA训练策略,
LoRA(Low-Rank Adaptation of Large Language Models),大语言模型的低秩适配,是一种高效的模型微调方法,微软 2021 年提出来的。
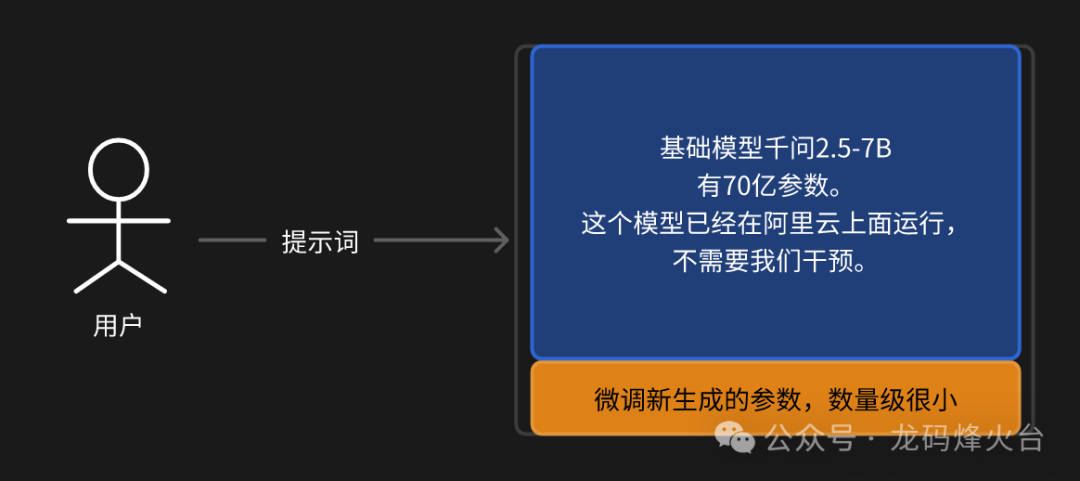
LoRA的原理很复杂,直观来理解就是,原先的基础模型保持不变,还是那些参数,比如我们用的千问2.5-7B模型,有70亿参数,这些参数不会改变,也不需要我们重新部署。
针对我们的微调任务,新生成了一批参数,数量很小。模型部署只需要把加载这批小参数。
模型在处理用户输入的提示词时,结合【新参数】和【基础模型】完成推理,得到输出。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









