






1.引言
传统搜索系统基于关键字匹配,缺少对用户问题理解和答案二次处理能力。本文探索使用大语言模型(Large Language Model, LLM),通过其对自然语言理解(Natural Language Understanding,NLU)和生成(Natural Language Generation,NLG)的能力,深入理解用户意图,并对原始知识点进行汇总、整合,生成更贴切的答案。
大模型能够回答较为普世的问题,但是若要服务于垂直专业领域,也会存在知识深度、知识准确度和时效性不足的问题。为了满足汽车行业的需求,团队投入了大量的时间和精力,构建一个强大的汽车领域知识库。
2.方案分析
2.1
结合传统搜索技术构建基础知识库
为了构建基础知识库,我们可以利用传统的搜索技术进行查询。这种方法具有以下优势:
- 较高的问答可控性:通过使用传统搜索技术,可以更好地控制问题和回答的准确性。借助精确的搜索匹配,提供更准确和可靠的答案。
- 适应常见知识库应用场景:不论是处理大规模数据、实现快速查询还是及时更新,传统搜索技术都能满足常见知识库应用场景的需求。其成熟的技术栈可以提供稳定的性能和功能。
- 技术风险较低:传统搜索技术已经得到广泛应用并积累了丰富的实践经验,能够降低技术探索的风险。
同时,利用语言模型 (LLM) 作为用户与搜索系统之间的交互媒介,能够充分发挥其强大的自然语言处理能力:
- 实现对用户请求的理解:LLM可以进行纠错、关键点提取等预处理,从而更好地理解用户的意图和问题。
- 对搜索结果进行二次加工:在保证正确性的前提下,LLM可以进一步概括、分析和推理搜索结果,以提供更全面和深入的答案。
结合两者,能够优化基础知识库的构建和查询过程,从而更高效地处理业务问题。
2.2
方案设计
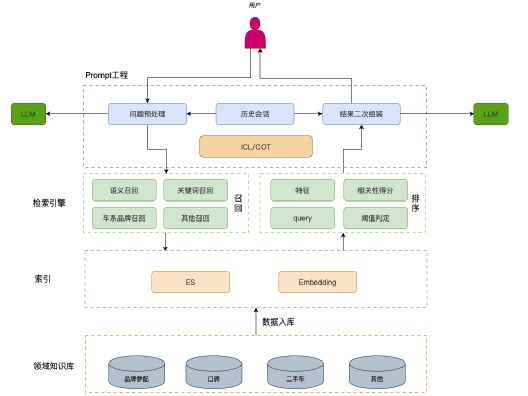
►2.3.1 LLM
LLM(Large Language Model)具有以下主要功能:
- 理解用户问题:LLM可以对用户的问题进行理解,包括纠错和提取关键词等操作。它还能引导用户提供更多信息,以便更好地理解用户意图。
- 对本地检索结果进行二次处理整合:LLM可以对本地检索的TopK答案进行二次加工。例如,可以概括、推理等操作,以提供更全面和深入的答案。
- 具备上下文交互能力:LLM能够处理各种类型的上下文交互,比如车系比较、油耗、加速性能等各类配置相关的问题。它可以根据上下文信息来给出更准确和个性化的回答。
►2.3.2本地搜索系统
-
本地搜索系统解决了查询匹配的问题,并具备以下功能:
-
ES Search:通过Elasticsearch(ES)的能力,将结构化数据接入系统,提供车系、关键词等的全文检索功能。
-
Embedding Search:将文字形式的查询请求转换为数值向量形式,并接入Milvus等向量数据库,提供在线相似度查询功能。
-
去重:在搜索结果中可能存在重复内容,去重操作可以增加大模型接收的信息量,避免重复答案的出现。
-
相关性排序:针对搜索结果,进行相关性排序,选取TopK最相关的答案,以提供更精准和有用的答案。
3.方案实现
3.1
工程架构
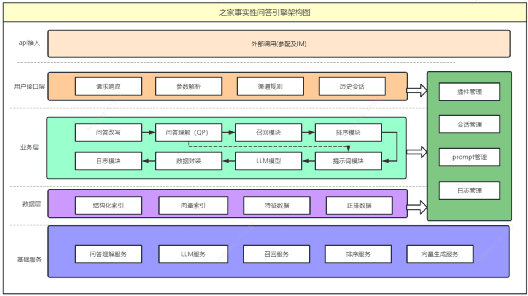
►3.1.1通用模块
通用模块包括以下功能:
-
问答改写:根据用户输入信息和上下文历史信息,对输入进行改写,以便更好地理解用户意图。
-
问答理解:对经过改写的用户输入进行理解,生成向量、关键词、标签、分类等信息,为后续处理提供基础。
-
召回模块:根据用户的意图和实体信息,召回相关内容,以提供更多可能的答案。
-
排序模块:通过相关性模型,对召回的内容进行排序,选择与问答最相关的topN内容,并进行数据抽取。
-
提示词模块:根据用户输入和处理流程,调用不同的提示词(prompt),为生成对话内容提供指导。
-
LLM模型:根据提示词和排序生成的相关数据,生成对话内容,以提供给用户。
-
日志模块:记录请求全流程日志,用于模型训练、性能分析和案例查询等目的。
►3.1.2管理模块
管理模块包括以下功能:
- 会话管理:保存用户的历史问答信息,以便在对话过程中进行上下文的保持和引用。
- Prompt管理:配置不同场景下的提示词信息,以适应不同的用户需求和使用场景。
- 插件管理:针对不同渠道的用户,可以使用不同的插件配置,例如IM用户可以选择是否访问产品库插件。
- 日志管理:管理请求日志、性能日志和结果日志,以便进行日志的存储、检索和分析。
►3.1.3知识入库
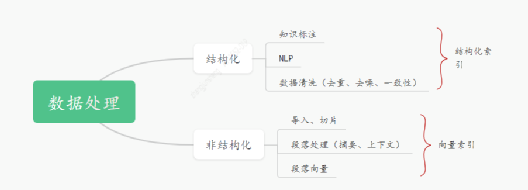
目前采用Elasticsearch(ES)作为结构化数据的存储支持,并利用ES的IK分词插件实现全文检索功能。
- 在数据向量化方面,我们使用了大语言模型生成的向量来更准确地捕捉语义相关性。向量化的处理流程如下:
- 数据导入:根据不同的数据源内容,如数据库、PDF、Word等,进行数据导入操作。
- 数据处理:对目录、无效信息等进行数据预处理,将文档切片以便更容易捕捉到语义相关的内容(文章长度越长,语义粒度越粗)。
- 段落处理:基于上下文相关性,生成段落信息。
- 模型处理:选择适配的模型对段落数据进行向量化。
在存储方面,尽管许多传统数据库或存储中间件已经提供了向量化支持,但专业的解决方案是使用向量数据库,例如Vearch、Milvus等。本文中我们选择了Milvus作为向量索引的存储,根据实际情况可以选择适合的向量索引数据库。
3.2
搜索
► 3.2.1召回
当前的召回设计分为两类:
- **明文召回:**首先,通过API对用户问题进行解析,提取关键词(例如车系、品牌、分类等)。然后,利用这些关键词从ES索引中进行全文检索,找到与之最匹配的N条记录。
- **非明文召回:**在这种方法中,我们使用嵌入模型将用户问题进行嵌入,并获取问题向量。接下来,使用问题向量在Milvus中进行检索,找到与之最匹配的N条记录。
通过这样的召回方式,我们可以针对用户问题进行全文检索或基于嵌入模型的向量检索,以获取与之最相关的记录。这种设计能够提高召回的准确性和效率,为后续的答案生成和排序提供更可靠的基础。
►3.2.2相关性(TopK选取)
目前,我们采用了基于Boosting算法集成的xgboost模型作为相关性模型,其重点在于确保最终结果的稳定性和可控性。这个模型的实现与传统搜索逻辑类似:
首先,我们将查询(Query)特征、物品(Item)特征和相关性特征进行组合,同时也考虑了查询和物品之间的交叉特征。经过特征转换模块,如归一化和取对数等操作,我们将这些特征输入到xgboost模型中进行预测得分。然后,我们选取TopK个预测结果作为最终的排序。
通过这样的优化设计,我们能够更好地利用xgboost模型的强大分类能力,并确保结果的稳定性和可控性。
3.3
大模型
***►*3.3.1模型介绍
我们构建了一个汽车领域的大语言模型仓颉,旨在解决看车、买车、用车、换车全流程问题。该模型基于先进的自然语言处理技术和深度学习算法,具备强大的语义理解和信息处理能力。无论是了解车型性能、比较品牌优劣,还是寻找购车建议或了解保养、维修等知识,我们的模型都能提供准确、全面的答案。
►3.3.2模型数据
为了满足汽车行业的需求,团队投入了大量的时间和精力,构建一个强大的汽车领域知识库。下面是是训练模型使用的部分数据介绍:
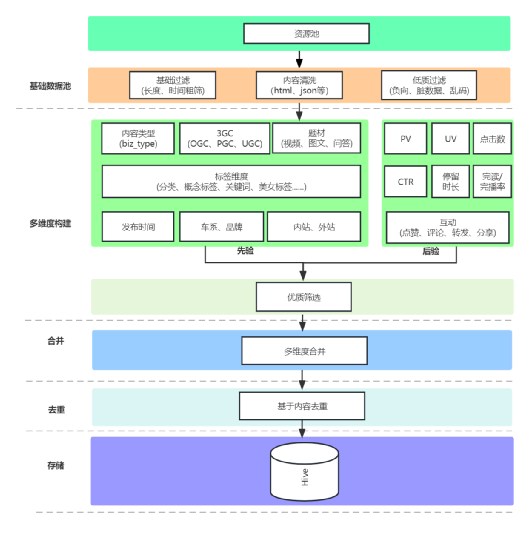
- 口碑文章:我们收集了大量的口碑文章,涵盖了各种汽车品牌和型号的评价和评论。这些文章包含了消费者对汽车性能、外观、舒适度等方面的真实反馈,为我们的模型提供了宝贵的参考。
- 问答数据:我们整理了大量的汽车领域问答数据,包括消费者提出的问题以及专家给出的回答。这些问答涉及到汽车购买、保养、维修等方面的知识,为我们的模型提供了广泛而丰富的信息。
- 参配品库:我们建立了一个详尽的汽车参配品库,包含了各种汽车配件和配置的信息。这些数据可以帮助用户了解不同汽车型号的配置选项,从而做出更明智的购买决策。
- 百科知识:我们清洗和过滤了大量的百科知识数据,包括来自公开领域的百科的高质量内容。这些数据涵盖了汽车行业的历史、技术、发展趋势等方面的知识,为我们的模型提供了全面而准确的背景信息。
- 网页和书籍数据:我们还整理了大量的网页和书籍数据,其中包含了关于汽车领域的专业知识和研究成果。这些数据来源广泛,覆盖了汽车行业的各个方面,为我们的模型提供了多样化的学习材料。
通过对以上数据的深度清洗和过滤,我们的模型已经取得了令人瞩目的训练效果。它能够准确理解和回答与汽车相关的问题,提供有用的建议和信息,帮助用户更高效地处理业务问题。
►3.3.3模型训练
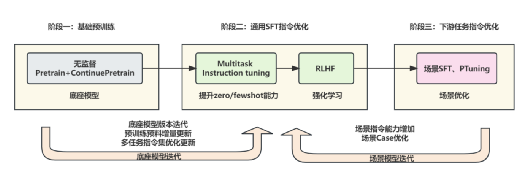
大语言模型训练采用了一系列创新的技术,包括 LoRA、QLoRA、RoPE scaling 插值、DPO training 以及 dataset streaming。
首先,采用了 LoRA 和 QLoRA 技术,这两种技术都能有效地减少内存和 GPU 的使用,从而缩短训练时间。这意味着我们可以更快地处理数据,为公司节省宝贵的时间和资源。
其次,使用了 RoPE scaling 插值技术来扩展 LLaMA 模型的上下文长度。这使得我们的模型能够更好地理解和处理复杂的语言环境,从而提供更准确的结果。
此外,还采用了 DPO training 技术来简化 RLHF。通过只需要训练单独的 DPO 模型,我们成功地替代了 RLHF 的奖励模型+PPO 强化模型,解决了 RLHF 训练极不稳定,超参敏感,调参困难的问题。这使得我们的模型训练过程更加稳定,也更容易进行参数调整。
最后,使用了 dataset streaming 技术实现大模型流式训练。这一技术解决了大模型数据集加载内存的开销问题,明显提升了训练速度。这意味着我们可以更快地处理大量数据,带来更高的效率。
3.4
效果评测
为了满足汽车领域的特有评测指标,通过构建了汽车领域的专业评测集,自研大模型在汽车领域远超开源模型,并在通用领域与主流开源模型持平。以下是我们部分评测项:
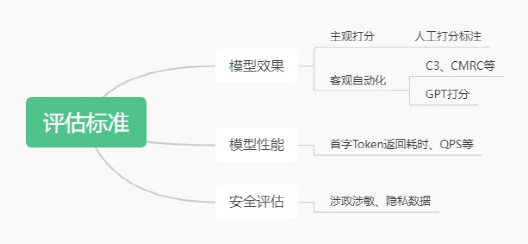
►3.4.1评估标准
►3.4.2汽车领域评测集
-
exam:涵盖车系品牌、参配等相关信息,判断是否能够准确理解和回答相关问题能力。
-
领域情感:对于用户在汽车领域的情感表达,判断情感分析和信息反馈能力。
-
类目:针对汽车领域的不同类目,判断是否具备丰富的知识和理解能力。
-
auto_rc、qcr_rc:这两个评测项用于判别汽车领域的阅读理解任务。
-
领域问答:涵盖领域内各方向问题
***►*3.4.3通用领域评测集
除了在汽车领域的评测,在通用领域的评测集上也做了相关对比评测。以下是一些评测集的示例:
- afqmc:句子对匹配任务,判断两个句子之间的关系能力。
- ocnli:自然语言推理任务,对给定的前提和假设进行推理和判断。
- weibo:微博文本分类任务,对微博文本进行准确分类判断。
- c3:中文阅读理解任务,理解并回答相关问题能力。
- cmrc:机器阅读理解任务,阅读理解的能力。
- harder_rc:更具挑战性的阅读理解任务,判断应对复杂的问题和场景的能力。
- 通用问答:涵盖知识问答、写文章、推理、娱乐等问答知识
在汽车垂直领域取得了明显的效果,当然,在评测时也出现了一些模型幻觉、格式异常等情况,我们也在对模型进行持续的迭代和优化。
3.5
结果整合
结果整合,可以对本地搜索系统返回的结果进行进一步加工和优化,充分发挥LLM的多项能力,从而使文章表述更加精炼明确,提高文章的可读性和信息传达效果:
-
总结和概括:对搜索结果进行总结和概括,提取出关键信息,使其更具有可读性和易理解性。
-
格式整理:进行格式化整理,使其呈现方式更加清晰和统一,提高用户阅读体验。
-
去重和翻译:排除搜索结果中的重复内容,确保给用户呈现唯一性的答案。同时,LLM还支持翻译功能,可以将搜索结果翻译为用户需要的语言,满足多语言环境下的需求。
-
上下文分析和处理:通过分析会话历史和提取上下文信息,LLM能够更好地理解用户意图,并在结果整合过程中考虑到上下文的影响。这使得生成的答案更加准确和个性化。
4.示例展示
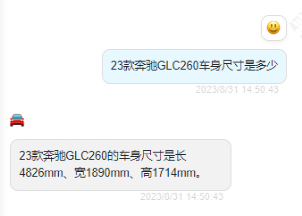
以参配场景为例:
23 款奔驰 GLC260 车身尺寸是多少?
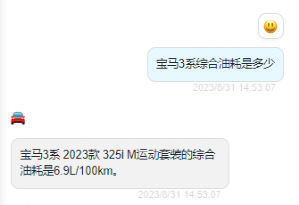
宝马 3 系综合油耗是多少?
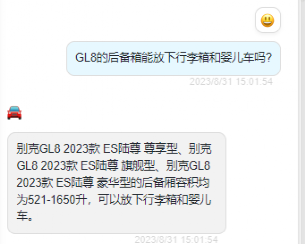
GL8 的后备箱能放下行李箱和婴儿车吗?
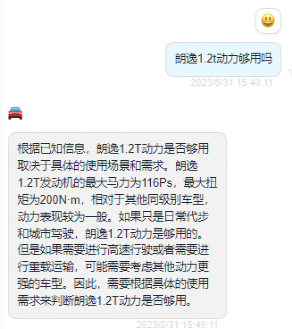
朗逸 1.2t 动力够用吗?
5. 总结
LLM+搜索架构融合了意图理解、智能搜索、结果增强等模块。深入理解用户指令,精确驱动查询词的搜索,结合大语言模型技术来优化模型结果生成的可靠性。通过这一系列协同作用,大模型实现了更精确、智能的模型结果回答,通过这种方式减少了模型的幻觉。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1617
1617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









