







本文介绍使用LlamaIndex框架,只要通过10行代码,就可以实现更好地本地大模型知识库RAG智能问答,且具备更好的可扩展性。
1. 了解LlamaIndex
LlamaIndex是一个数据框架,专门为构建检索增强生成(RAG)系统而设计,基于企业数据构建生产级LLM应用。

Source: https://www.llamaindex.ai/
LlamaIndex提供了实现RAG的一系列组件,包括:
-
数据连接器(Data connectors),对接API、PDF、SQL等来源获取数据
-
数据索引(Data indexes),对数据进行结构化,使其易于为LLM高效使用
-
检索引擎(Query engines),用于知识增强输出的强大检索接口
-
聊天引擎(Chat engines),用于与数据进行多轮消息交互的对话接口
-
数据代理(Data agents),从简单的辅助功能到API集成等更多功能
-
应用程序集成(Application integrations ),集成LangChain、Flask、Docker、ChatGPT等生态系统

Source:Build a chatbot with custom data sources, powered by LlamaIndex
上图展示LlamaIndex框架如何实现RAG,其过程包括两个阶段:
-
索引阶段:这是LlamaIndex构建知识库的过程,首先提取数据并将其转换为文档(Documents),然后解析这些文档中的元数据(如文本、关系等)到节点(Nodes),并基于块(Chunks)创建可查询的索引。
-
查询阶段:从知识库中检索相关上下文,并提供给大模型进行回答。在这一阶段,大模型可以获取和使用其原本训练数据中未包含的数据,从而增强回答的准确性。
2. 安装LlamaIndex和LLM组件
我们可以通过以下一条命令,安装LlamaIndex的主要组件。其中,包括常用的llama-index-core组件。
pip install llama_index
由于我们不使用OpenAI的API,而是通过Ollama使用本地部署的LLM,因此我们还需要安装相关组件。
pip install llama_index.llms.ollama
3. 选择嵌入模型
我们这次选择一个对中文支持更好的嵌入模型,智源研究院发布的BAAI/bge-small-zh-v1.5。
LlamaIndex通过与LangChain的集成,可以从HuggingFace下载和使用各种模型。所以,我们先安装LangChain,后面会用到其中的langchain_community组件。它提供与第三方如LlamaIndex的集成。
pip install langchain
由于运行时要从HuggingFace下载模型,请预先在电脑上设置HuggingFace的国内镜像地址hf-mirror.com。
export HF_ENDPOINT=https://hf-mirror.com
5. 知识库管理
为了演示方便,我们简化了知识库管理的功能。我们只需要把相应的PDF、DOCX文档放在指定的文件夹下。
比如,我创建一个文件夹,名称“data”。
我把之前写《大卫说流程》系列文章的DOCX文件,复制到data文件夹中。后面我可以根据这些文章中的内容,向大模型提问。你可以使用你自己电脑上的任何知识文档。
6. 十行代码实现RAG
现在,创建了一个文件app.py,编写如下10行Python代码,并确保把app.py 和“data“放在同一个目录下。
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.ollama import Ollama
# 配置ollama的LLM模型,这里我们用gemma:7b
Settings.llm = Ollama(model="gemma", request_timeout=600.0)
# 配置HuggingFaceEmbeddings嵌入模型,这里我们用BAAI/bge-small-zh-v1.5
from langchain_community.embeddings import HuggingFaceEmbeddings
Settings.embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 将data文件夹下的文档建立索引
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
# 创建问答引擎,并提一个简单的问题
query_engine = index.as_query_engine()
response = query_engine.query("流程有哪三个特征?")
print(response)
以上代码,我给出了注释。重点说一下LLM和嵌入模型的选择与配置。
1)LLM配置
LLM选用的是谷歌最新开源的gemma:7b模型。该模型效果较好,在我的笔记本电脑上推理的时间比较长,所以要把超时设置得比较大,600秒。
若使用更小的模型,例如gemma:2b,推理速度更快,但是我发现效果会差很多。你也可以尝试Ollama提供的qwen:7b、llama2:7b等模型。
2)嵌入模型配置
嵌入模型选用的是BAAI/bge-small-zh-v1.5。如果你用的是GPU服务器,而不是笔记本电脑,在性能足够支撑的情况下,推荐采用规模更大的模型,比如最新的BAAI/bge-m3。同样,LLM也推荐采用百亿参数以上的开源模型。
3)文档问答
“流程有哪三个特征”。
如果大模型RAG运行良好的话,应能回答出”目标性、重复性、过程性“这三个特征。你需要针对你所选用的知识文档来提问。
现在,可以通过以下命令运行程序。
python app.py
由于运行时需要下载嵌入模型,对文档进行索引,在笔记本电脑上运行需要等待数分钟,请保持耐心:-)
你也可以在app.py开头添加如下代码,观察输出的日志信息。
import logging
import sys
# 增加日志信息
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
等待片刻后,终端上会输出大模型给出的回答。

可以看出,大模型获取到了本地文档中的上下文信息,并给出了准确的回答!
7. 选用Moonshot API
在笔记本电脑上运行gemma:7b比较慢,我们可以尝试使用月之暗面的Moonshot API,更快地实现文档问答。
这与直接使用kimi的不同点在于,我们无需将全部文档发给kimi。而是将数据全部保存在本地,仅仅把检索到的信息发给大模型来回答。这样更好地保护数据安全。
请将app.py代码中,原本使用Ollama的LLM的部分,更换为如下代码。

请提前在Moonshot开放平台(https://platform.moonshot.cn/)申请API key,输入在以上代码中。
运行app.py后的结果如下。

可以看到,针对文档中有明确答案的问题,本地运行的gemma:7b相比Moonshot API的回答生成,也毫不逊色。
8. 构建Web应用
LlamaIndex提供了API,以及Python和TypeScript开发包,可以与Flask、Streamlit、Chainlit等框架集成,从而很方便地创建类似ChatGPT的Web界面,进一步构建生产级的RAG系统。
作为示例,我们采用Streamlit,修改app.py并增加相关代码,构建一个简单的Web UI,方便进行多轮对话。以下是完整的示例代码,总共也才需要50行!
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, ServiceContext, Document
from llama_index.llms.ollama import Ollama
# 配置ollama的LLM模型,这里我们用gemma:7b
llm = Ollama(model="gemma", request_timeout=600.0)
# 配置HuggingFaceEmbeddings嵌入模型,这里我们用BAAI/bge-small-zh-v1.5
from langchain_community.embeddings import HuggingFaceEmbeddings
embed_model = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
# 配置Streamlit Web应用
import streamlit as st
st.set_page_config(page_title="本地大模型知识库RAG应用", page_icon="🦙", layout="centered", initial_sidebar_state="auto", menu_items=None)
st.title("本地大模型知识库RAG应用")
st.info("By 大卫", icon="📃")
if "messages" not in st.session_state.keys(): # 初始化聊天历史记录
st.session_state.messages = [
{"role": "assistant", "content": "关于文档里的内容,请随便问"}
]
@st.cache_resource(show_spinner=False)
def load_data():
with st.spinner(text="Loading and indexing the Streamlit docs – hang tight! This should take 1-2 minutes."):
reader = SimpleDirectoryReader(input_dir="./data", recursive=True) # 将data文件夹下的文档建立索引
docs = reader.load_data()
service_context = ServiceContext.from_defaults(llm=llm,embed_model=embed_model) # 使用上面配置的模型
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
return index
index = load_data()
if "chat_engine" not in st.session_state.keys(): # 初始化聊天引擎
st.session_state.chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
if prompt := st.chat_input("Your question"): # 提示用户输入问题,并将问题添加到消息历史记录
st.session_state.messages.append({"role": "user", "content": prompt})
for message in st.session_state.messages: # 显示此前的问答记录
with st.chat_message(message["role"]):
st.write(message["content"])
if st.session_state.messages[-1]["role"] != "assistant": # 生成回答
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = st.session_state.chat_engine.chat(prompt)
st.write(response.response)
message = {"role": "assistant", "content": response.response}
st.session_state.messages.append(message) # 将回答加入到消息历史记录
上述LlamaIndex与Streamlit的集成的相关代码,来源于这篇文章,供参考。
https://blog.streamlit.io/build-a-chatbot-with-custom-data-sources-powered-by-llamaindex/
通过以下命令运行代码后,浏览器将自动打开http://localhost:8501,即可使用这个Streamlit应用。
streamlit run app.py
同样,提问:“流程有哪三个特征?”。可以得到以下回复。你可以针对文档继续问其他问题。
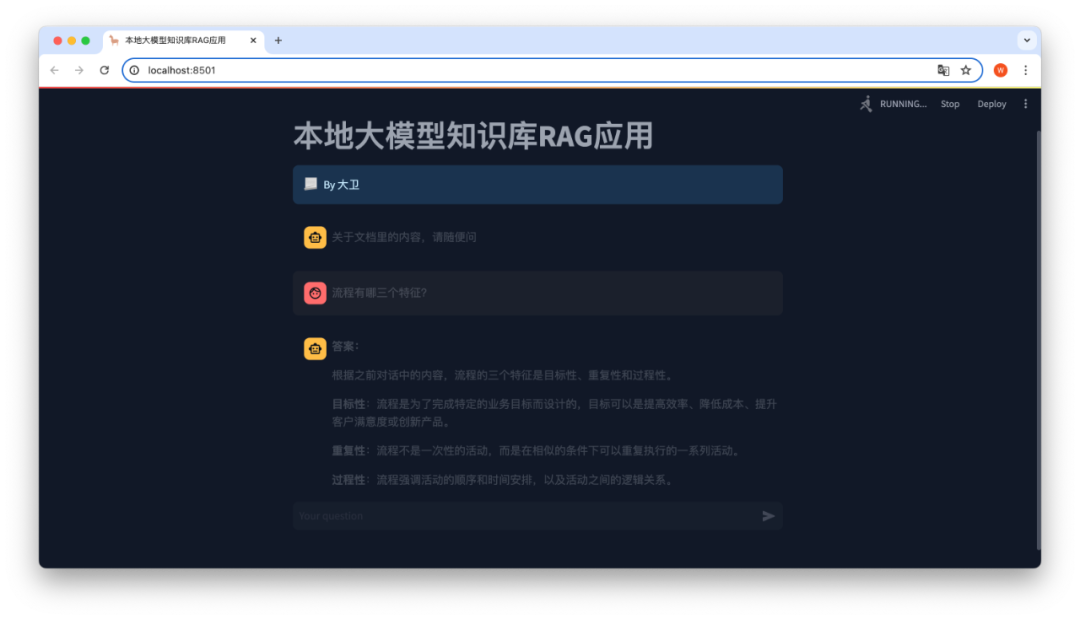
9. 阶段总结
以上,我们基于LlamaIndex + Ollama + Streamlit,构建了一个完整可本地部署和运行的RAG智能问答系统。
未来,可以在这个技术栈上,进一步完善知识库的管理、优化前端界面,打造生产级的系统。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 458
458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









