






目标
这项研究的主要目的是通过创建一个在医疗建议方面具有更高准确性的专业语言模型,来解决在诸如ChatGPT等流行的大型语言模型(LLMs)中观察到的医学知识局限性。
Methods
We achieved this by adapting and refining the large language model meta-AI (LLaMA) using a large dataset of 100,000 patient-doctor dialogues sourced from a widely used online medical consultation platform. These conversations were cleaned and anonymized to respect privacy concerns. In addition to the model refinement, we incorporated a self-directed information retrieval mechanism, allowing the model to access and utilize real-time information from online sources like Wikipedia and data from curated offline medical databases.
方法
我们通过适应和精炼大型语言模型meta-AI(LLaMA)来实现这一目标,使用的数据集包含了来自一个广泛使用的在线医疗咨询平台的100,000个患者-医生对话。这些对话被清理并匿名化,以尊重隐私关切。除了模型精炼之外,我们还引入了一种自我指导的信息检索机制,允许模型访问和使用来自维基百科等在线来源以及精选离线医疗数据库的实时信息。
Results
The fine-tuning of the model with real-world patient-doctor interactions significantly improved the model’s ability to understand patient needs and provide informed advice. By equipping the model with self-directed information retrieval from reliable online and offline sources, we observed substantial improvements in the accuracy of its responses.
结果
通过对模型进行真实世界患者-医生互动的微调,显著提高了模型理解患者需求并提供明智建议的能力。通过使模型能够从可靠的在线和离线来源自我指导信息检索,我们观察到其回答准确性的显著提升。
Conclusion
Our proposed ChatDoctor, represents a significant advancement in medical LLMs, demonstrating a significant improvement in understanding patient inquiries and providing accurate advice. Given the high stakes and low error tolerance in the medical field, such enhancements in providing accurate and reliable information are not only beneficial but essential.
结论
我们提出的ChatDoctor代表了医学LLMs的重大进步,在理解患者询问和提供准确建议方面表现出显著的改进。鉴于医疗领域的高风险和低错误容忍度,这种在提供准确和可靠信息方面的增强不仅是有益的,而且是必要的。Categories:Family/GeneralPractice,MedicalPhysics,Integrative/Complementary Medicine
Keywords: ai chatbot, large language model, llama, chat gpt, gpt
类别:家庭/全科实践,医学物理,整合/补充医学
关键词:AI聊天机器人,大型语言模型,LLaMA,ChatGPT,GPT
Introduction
The development of instruction-following large language models (LLMs), such as ChatGPT [1], has gained significant attention due to their remarkable success in instruction understanding and human-like response generation. These auto-regressive LLMs [2] are pre-trained on web-scale natural language by predicting the next token and then fine-tuned to follow large-scale human instructions. These models show robust performance on a wide range of natural language processing (NLP) tasks and can generalize to unseen tasks,demonstrating their potential as unified solutions to various problems in natural language understanding,text generation, and conversational artificial intelligence. However, the exploration of such general-domain LLMs in the medical domain remains relatively scarce [3], despite their great potential in revolutionizing medical communication and decision-making [4]. In general, these common-domain models were not trained to capture the medical-domain knowledge specifically or in detail, resulting in models that often provide incorrect medical responses.
引言
遵循指令的大型语言模型(LLMs)的发展,如ChatGPT [1],由于其在对指令理解和类人响应生成方面的显著成功,已经引起了广泛关注。这些自回归LLMs [2] 通过预测下一个令牌,在网页级自然语言上进行预训练,然后被微调以遵循大规模的人类指令。这些模型在广泛的自然语言处理(NLP)任务上表现出稳健的性能,并且能够泛化到未见过的任务,展示了它们作为自然语言理解、文本生成和会话人工智能中各种问题的统一解决方案的潜力。然而,尽管这些通用领域模型在革新医疗通信和决策方面具有巨大潜力 [4],但它们在医疗领域的探索仍然相对较少 [3]。通常,这些通用领域模型并未被专门或详细地训练以捕捉医疗领域的知识,导致模型常常提供错误的医疗响应。
By fine-tuning large linguistic dialogue models on data from real-world patient-physician conversations,these models’ ability in understanding patients’ inquiries and needs can be significantly improved. In addition, to further enhance the models’ credibility, a knowledge brain based on online sources such as Wikipedia or offline sources like medical-domain databases can be incorporated into the models to retrieve real-time information to facilitate answering medical questions. The enhanced reliability of such answers is vital for the medical field, as a wrong answer can be detrimental to patients’ treatments and well-being. In this study, we investigated the use of these two strategies: model fine-tuning and knowledge brain instillation, to enhance the capability of LLMs to serve as medical chatbots. Since the prevalent ChatGPT model is not open source, we used Meta’s public large language model meta-AI (LLaMA) model as the platform for development and evaluation. In detail, we first trained a generic conversation model based on LLaMA, using 52K instruction-following data from Stanford University’s Alpaca project [5]. We then finetuned the conversation model on our collected dataset of 100K patient-physician conversations from an online medical consultation website (www.healthcaremagic.com). Through extensive experiments, we found that the fine-tuned model by patient-physician dialogues outperforms ChatGPT in terms of precision, recall,and the F1 score [6]. In addition, the autonomous ChatDoctor model, which is able to retrieve the latest online/offline information, can also answer medical questions about relatively new diseases that are not included in the patient-physician training dialogues, for instance, the Monkeypox (Mpox) disease [7,8].
通过在真实世界患者-医生对话数据上对大型语言对话模型进行微调,可以显著提高这些模型理解患者询问和需求的能力。此外,为了进一步提高模型的可靠性,可以将基于在线来源(如维基百科)或离线来源(如医疗领域数据库)的知识大脑整合到模型中,以检索实时信息,帮助回答医疗问题。这些答案的增强可靠性对医疗领域至关重要,因为错误的答案可能会对患者的治疗和福祉造成损害。在本研究中,我们探讨了这两种策略的使用:模型微调和知识大脑植入,以增强LLMs作为医疗聊天机器人的能力。由于流行的ChatGPT模型不是开源的,我们使用了Meta的公共大型语言模型meta-AI(LLaMA)作为开发和评估的平台。具体来说,我们首先使用斯坦福大学Alpaca项目 [5] 的52K指令遵循数据,在LLaMA的基础上训练了一个通用对话模型。然后,我们在从在线医疗咨询网站(www.healthcaremagic.com)收集的100K患者-医生对话数据集上对对话模型进行了微调。通过广泛的实验,我们发现通过患者-医生对话微调的模型在精确度、召回率和F1分数 [6] 方面优于ChatGPT。此外,能够检索最新在线/离线信息的自主ChatDoctor模型,也能够回答患者-医生训练对话中未包含的相对较新的疾病,例如猴痘(Monkeypox)[7,8]的医疗问题。
In summary, the ChatDoctor model has the following three main contributions:
总结来说,ChatDoctor模型具有以下三个主要贡献:
\1. We established a methodology for fine-tuning LLMs for application in the medical field.
1.我们建立了一种用于医疗领域应用的大型语言模型微调方法。
\2. We compiled and publicly shared a comprehensive dataset of 100,000 patient-doctor interactions to serve as a training resource for refining the LLM. This dataset includes a wealth of terms, knowledge, and expertise essential for training LLMs in the medical domain. Additionally, we curated and openly shared another dataset consisting of 10,000 patient-doctor conversations from a separate source (www.icliniq.com) to serve as a testing resource for the model. To support and stimulate future advancements in the development of dialogue models in healthcare, we provide public access to all relevant resources such as source codes, datasets, and model weights. These can be found at https://github.com/Kent0n-Li/ChatDoctor.
2.我们编制并公开分享了包含100,000个患者-医生互动的综合数据集,作为精炼LLM的训练资源。这个数据集包含了用于医疗领域LLMs训练的大量术语、知识和专业知识。此外,我们还策划并公开分享了另一个包含10,000个患者-医生对话的数据集,来自另一个来源(www.icliniq.com),作为模型的测试资源。为了支持和促进未来医疗对话模型开发的进步,我们提供了所有相关资源的公共访问,如源代码、数据集和模型权重。这些可以在https://github.com/Kent0n-Li/ChatDoctor找到。
\3. We proposed an autonomous ChatDoctor model that can retrieve online and offline medical domain knowledge to answer medical questions on up-to-date medical terms and diseases, which can potentially reduce the errors and hallucinations of LLMs [9-11].
3.我们提出了一个自主的ChatDoctor模型,它可以检索在线和离线医疗领域知识,以回答关于最新医疗术语和疾病的医疗问题,这有可能减少LLMs的错误和幻觉[9-11]。
This article was previously posted to the arXiv preprint server on March 24, 2023.
这篇文章之前于2023年3月24日发布到了arXiv预印本服务器上。
Materials And Methods
Collection and preparation of patient-physician conversation dataset
The initial step in refining our model involved curating a dataset comprising patient-physician interactions.Often, patients describe their symptoms in casual and somewhat superficial language. If we attempted to generate these dialogues synthetically, similar to Alpaca [5], it could lead to over-specific descriptions with limited diversity and relevance to the real world. Hence, we chose to gather authentic patient-doctor conversations, collecting around 100k such interactions from the online medical consultation website,HealthCareMagic. The data were filtered both manually and automatically. Specifically, we automatically filtered out conversations that were too short, most of which did not answer anything of practical significance. And we manually filtered the content of the responses that had errors. To maintain privacy, we erased any information identifying the doctor or the patient and employed LanguageTool to rectify any grammatical errors. This dataset was labeled HealthCareMagic100k, illustrated in Figure 1. We also sourced roughly 10k additional conversations from another independent online medical consultation site, iCliniq, to test our model’s performance. The iCliniq dataset was chosen randomly in a stratified manner to guarantee representation across various medical specialties. It was also made certain that the selected data contained no identifiable patient information, in strict compliance with privacy and ethical standards.
材料与方法
患者-医生对话数据集的收集和准备
我们模型精炼的初始步骤包括策划一个包含患者-医生互动的数据集。通常,患者会用随意且有些表面的语言描述他们的症状。如果我们尝试像Alpaca [5]那样合成这些对话,可能会导致过于具体的描述,缺乏多样性和与真实世界的相关性。因此,我们选择收集真实的患者-医生对话,从在线医疗咨询网站HealthCareMagic收集了大约10万个此类互动。数据经过手工和自动过滤。具体来说,我们自动过滤掉了过短的对话,其中大部分没有回答实际重要的问题。我们手动过滤了回应中的错误内容。为了保护隐私,我们删除了任何识别医生或患者的信息,并使用LanguageTool纠正任何语法错误。这个数据集被标记为HealthCareMagic100k,如图1所示。我们还从另一个独立的在线医疗咨询网站iCliniq额外搜集了大约1万个对话,以测试我们模型的性能。iCliniq数据集是按照分层方式随机选择的,以确保涵盖各种医学专业。还确保所选数据不含任何可识别的患者信息,严格遵守隐私和伦理标准。
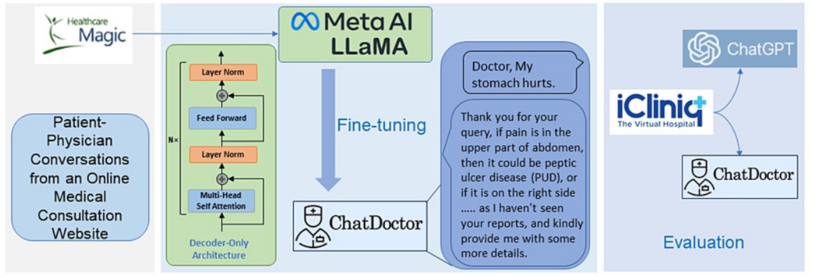
FIGURE 1: A summary of the process involved in gathering the patient-physician conversation dataset and the steps involved in training the ChatDoctor model.
图1:收集患者-医生对话数据集以及训练ChatDoctor模型所涉及过程的总结。
Creation of external knowledge database
LLMs typically predict the next word in a sequence, leading to potential inaccuracies or erroneous responses to questions (hallucinations) [12]. In addition, the model’s output can be unpredictable to some extent,which is unacceptable in the medical field. However, the accuracy of these models could be significantly improved if they could generate or assess responses based on a reliable knowledge database, depicted in Figure 2. Consequently, we curated a database (sample shown in Figure 3) encompassing diseases, their symptoms, relevant medical tests/treatment procedures, and potential medications. This database serves as an external and offline knowledge brain for ChatDoctor. Continually updatable without requiring model retraining, this database can be tailored to specific diseases or medical specialties. We utilized MedlinePlus to construct this disease database, but other reliable sources can also be used. Additionally, online information sources like Wikipedia can supplement the knowledge base of our autonomous model. It is worth noting that Wikipedia may not be a fully reliable database, but our framework can be easily extended to more reliable online databases such as reputable academic journals.
创建外部知识数据库
LLMs通常预测序列中的下一个单词,这可能导致对问题的响应不准确或错误(幻觉)[12]。此外,模型的输出在一定程度上可能是不可预测的,这在医疗领域是不可接受的。然而,如果这些模型能够基于一个可靠的知识数据库生成或评估响应,它们的准确性可以得到显著提高,如图2所示。因此,我们策划了一个数据库(样本如图3所示),涵盖疾病、症状、相关医疗测试/治疗程序以及可能的药物。这个数据库作为ChatDoctor的外部和离线知识大脑。这个数据库可以不断更新,而无需重新训练模型,并且可以针对特定疾病或医学专业进行定制。我们使用MedlinePlus构建了这个疾病数据库,但也可以使用其他可靠来源。此外,像维基百科这样的在线信息源可以补充我们自主模型的 knowledge base。值得注意的是,维基百科可能不是一个完全可靠的数据库,但我们的框架可以很容易地扩展到更可靠的在线数据库,如声誉良好的学术期刊。
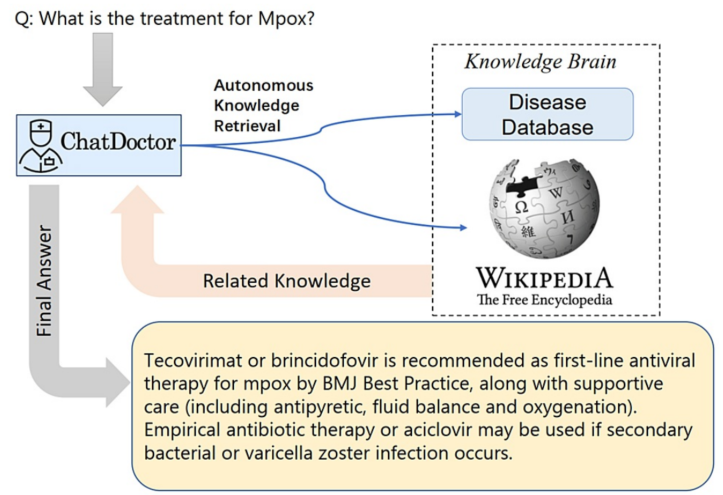
FIGURE 2: Overview of the autonomous ChatDoctor model based on information retrieval from an external knowledge brain.
图2:基于从外部知识大脑检索信息 的自主ChatDoctor模型概述。

FIGURE 3: Some samples in our offline disease database consist ofsymptoms, clinical test/treatment approaches, and medication suggestions.
图3:我们离线疾病数据库中的一些样本包括症状、临床测试/治疗方法以及药物建议。
Development of autonomous ChatDoctor with knowledge brain
Armed with the external knowledge brain, i.e., Wikipedia or our custom disease database, ChatDoctor can more accurately answer patient inquiries by retrieving reliable information. Upon establishing the external knowledge brain, we devised a mechanism to enable ChatDoctor to autonomously retrieve necessary information to answer queries. This was accomplished by constructing appropriate prompts to input into the ChatDoctor model. Specifically, we designed keyword mining prompts (Figure 4) as the initial step for ChatDoctor to extract key terms from patient queries for relevant knowledge search. Based on these keywords, top-ranked information was retrieved from the knowledge brain using a term-matching retrieval system [13]. Given the LLM’s word limit (token size), we divided the texts to be read into equal sections and ranked each section by the number of keyword hits. The ChatDoctor model then reads the first N sections (five used in our study) sequentially, selecting and summarizing pertinent information via prompts (Figure5). Ultimately, the model processes and compiles all the knowledge entries to generate a final response (Figure 6). This information retrieval approach ensures patients receive precise, well-informed responses backed by credible sources and can serve as a verification method for responses generated by ChatDoctor from prior knowledge
开发具有知识大脑的自主ChatDoctor
配备了外部知识大脑,即维基百科或我们自定义的疾病数据库,ChatDoctor可以通过检索可靠信息来更准确地回答患者询问。在建立外部知识大脑后,我们设计了一种机制,使ChatDoctor能够自主检索必要的信息来回答查询。这是通过构建适当的提示输入到ChatDoctor模型中实现的。具体来说,我们设计了关键词挖掘提示(图4),作为ChatDoctor从患者查询中提取关键术语以进行相关知识搜索的初始步骤。基于这些关键词,使用术语匹配检索系统[13]从知识大脑中检索排名靠前的信息。考虑到LLM的单词限制(令牌大小),我们将要阅读的文本分成相等的部分,并按关键词命中次数对每个部分进行排名。ChatDoctor模型然后依次阅读前N个部分(我们的研究中使用了五个),通过提示选择和总结相关信息(图5)。最终,模型处理和编译所有知识条目以生成最终响应(图6)。这种信息检索方法确保患者收到精确、有据可依的响应,并可以作为验证ChatDoctor根据先前知识生成的响应的方法。

FIGURE 4: Autonomously extract keywords for information retrieval
图4:自主提取信息检索关键词。

FIGURE 5: Autonomous information retrieval from the disease database through the prompt.
图5:通过提示从疾病数据库自主检索信息。

FIGURE 6: Instruct the ChatDoctor to read the retrieved domain knowledge and provide a reliable answer.
图6:指示ChatDoctor阅读检索到的领域知识并提供可靠的答案。
Model training
We developed the ChatDoctor model using Meta’s publicly accessible LLaMA-7B model [14], which uses Transformers with the structure of the decoder only. Despite its relatively modest 7 billion parameters, the LLaMA model exhibits comparable performance to the much larger GPT-3 model (with 175 billion parameters) across several NLP benchmarks. This performance enhancement was achieved by diversifying the training data rather than increasing network parameters. Specifically, LLaMA was trained on 1.0 trillion tokens from publicly accessible data sources like CommonCrawl and arXiv documents. We used conversations from HealthCareMagic-100k to fine-tune the LLaMA model [15] in line with Stanford Alpaca [5] training methodology. The model was first fine-tuned with Alpaca’s data to acquire basic conversation skills, followed by further refinement on HealthCareMagic-100k using 6 * A100 GPUs for three hours. The training process followed these hyperparameters: total batch size of 192, learning rate of 2x10⁻⁵, 3 epochs, maximum sequence length of 512 tokens, and a warmup ratio of 0.03, with no weight decay.
模型训练
我们使用Meta公开可访问的LLaMA-7B模型[14]开发了ChatDoctor模型,该模型使用仅包含解码器结构的Transformers。尽管其参数相对较少,仅有70亿个,但LLaMA模型在几个NLP基准测试中展现出了与参数量更大的GPT-3模型(拥有1750亿参数)相当的性能。这种性能提升是通过多样化训练数据而不是增加网络参数实现的。具体来说,LLaMA在公共可访问数据源如CommonCrawl和arXiv文档上接受了1000万亿个令牌的训练。我们使用了HealthCareMagic-100k中的对话来微调LLaMA模型[15],遵循斯坦福Alpaca[5]的训练方法。模型首先使用Alpaca的数据进行微调,以获得基本的对话技能,然后在使用6个A100 GPU进行了三小时的进一步精炼。训练过程遵循了以下超参数:总批量大小为192,学习率为2x10⁻⁵,3个周期,最大序列长度为512个令牌,预热比为0.03,无权重衰减。
Results
To evaluate the proficiency of the autonomous ChatDoctor model, we tested it using a variety of contemporary medical queries. One of these included a question related to “Monkeypox” (abbreviated as Mpox), as illustrated in Figure 7. Monkeypox was recently designated by the World Health Organization (WHO) on November 28, 2022, making it a relatively novel term. While ChatGPT was incapable of providing a satisfactory response, ChatDoctor, due to its autonomous knowledge retrieval feature, was able to extract pertinent information about Monkeypox from Wikipedia and deliver a precise answer. Similarly, for more general medical inquiries such as “Otitis,” as shown in Figure 8, ChatDoctor was able to provide a reliable response following the retrieval of relevant knowledge. In another instance, a question about “Daybue,” a drug that received FDA approval in March 2023, was accurately addressed by our model after it autonomously retrieved relevant information, demonstrating an advantage over ChatGPT, as shown in Figure 9.
结果
为了评估自主ChatDoctor模型的熟练程度,我们使用各种现代医学查询对其进行了测试。其中之一是关于“猴痘”(简称Mpox)的问题,如图7所示。猴痘是最近由世界卫生组织(WHO)在2022年11月28日命名的,使它成为一个相对较新的术语。虽然ChatGPT无法提供满意的回答,但由于ChatDoctor具有自主知识检索功能,它能够从维基百科中提取关于猴痘的相关信息并给出精确答案。同样,对于更一般的医疗询问,如“中耳炎”(如图8所示),ChatDoctor能够在检索到相关知识后提供可靠的响应。在另一个例子中,关于“Daybue”的问题得到了我们的模型准确回答,这是一种在2023年3月获得FDA批准的药物,ChatDoctor在自主检索到相关信息后显示出比ChatGPT的优势,如图9所示。

FIGURE 7: Comparison between the ChatGPT and the autonomous ChatDoctor for relatively new medical diseases/terms. The ChatGPT cannot recognize the word Mpox (aka, Monkeypox), while ournChatDoctor can provide the precise answer for the relevant medical tests of Mpox, with the help of the external knowledge brain.
图7:ChatGPT与自主ChatDoctor在相对较新的医疗疾病/术语方面的比较。ChatGPT无法识别Mpox(又名猴痘)这个词汇,而我们的ChatDoctor在外部知识大脑的帮助下,能够提供关于Mpox相关医疗测试的精确答案。

FIGURE 8: Comparison between the ChatGPT and the autonomous ChatDoctor. The ChatGPT provided a more general answer about otitis, while the ChatDoctor provided a more specialized response about the treatments of otitis, with the help of the external knowledge brain.
图8:ChatGPT与自主ChatDoctor的比较。ChatGPT提供了关于中耳炎的更一般的答案,而ChatDoctor在外部知识大脑的帮助下,提供了关于中耳炎治疗的更专业化的响应。

FIGURE 9: Comparison between the ChatGPT and the autonomous ChatDoctor. The ChatGPT is unfamiliar with the “Daybue” medication which received approval from the Food and Drug Administration (FDA) in early 2023. The ChatDoctor accurately pointed out the purpose of Daybue (trofinetide), with the help of the external knowledge brain.
图9:ChatGPT与自主ChatDoctor的比较。ChatGPT不熟悉“Daybue”这种药物,该药物在2023年初获得了食品和药物管理局(FDA)的批准。ChatDoctor在外部知识大脑的帮助下准确地指出了Daybue(trofinetide)的用途。
For a quantitative evaluation of ChatDoctor’s performance, we utilized questions from the independently sourced iCliniq database as inputs, with the corresponding responses from actual human physicians serving as the benchmark or “ground truth.” We compared these with responses generated by both ChatDoctor and ChatGPT. In this evaluation, we employed BERTScore [6] to compute Precision, Recall, and F1 scores for both ChatDoctor and ChatGPT. BERTScore leverages pre-trained BERT to match words in the candidate and reference sentences via cosine similarity, and BERTScore was chosen for its ability to evaluate the semantic similarity between our model’s responses and the reference sentences, which we believe is of utmost importance in the medical context. This method of evaluation closely aligns with human judgment at both sentence and system levels. In all three metrics, a higher value denotes a better match. As seen in the results illustrated in Table 1, the fine-tuned ChatDoctor model outperforms ChatGPT across all three metrics, with specific dialogue examples detailed in Figures 10-13.
为了对ChatDoctor的性能进行量化评估,我们使用了来自独立来源的iCliniq数据库中的问题作为输入,实际人类医生的相应回答作为基准或“真实情况”。我们将这些与ChatDoctor和ChatGPT生成的回答进行了比较。在这个评估中,我们使用了BERTScore [6] 来计算ChatDoctor和ChatGPT的精确度、召回率和F1分数。BERTScore利用预训练的BERT通过余弦相似度来匹配候选句和参考句中的单词,并且我们选择BERTScore是因为它能够评估我们的模型响应与参考句之间的语义相似性,我们认为这在医疗背景下至关重要。这种评估方法在句子和系统层面上都与人类判断紧密一致。在这三个指标中,数值越高表示匹配越好。如表1所示的结果,经过微调的ChatDoctor模型在所有三个指标上均优于ChatGPT,具体的对话示例详细展示在图10-13中。

TABLE 1: Quantitative comparison with BERTScore between ChatDoctor and ChatGPT. The pvalues in the table are derived from our paired t-test.
表1:使用BERTScore对ChatDoctor和ChatGPT进行量化比较。表中的p值来自我们的成对t检验。

FIGURE 10: Example 1: a patient suffering from a unilateral headache expressed concerns about a potential association with a brain tumor. Our ChatDoctor accurately proposed sinusitis as a possible cause for the headache, mirroring the diagnosis provided by the physician from iCliniq. On the other hand, ChatGPT failed to deliver a congruent interpretation regarding the root cause of the one-sided headache.
图10:示例1:一位患有单侧头痛的患者表达了对于可能关联脑肿瘤的担忧。我们的ChatDoctor准确地提出了鼻窦炎作为头痛的可能原因,这与iCliniq上的医生提供的诊断相呼应。另一方面,ChatGPT未能就单侧头痛的根本原因提供一个一致的解释。

FIGURE 11: Example 2: a patient reported having a white lump in their throat for several months and expressed concerns about potential cancer. All three entities, iCliniq, ChatGPT, and ChatDoctor suggested that the patient could be dealing with abnormally enlarged lymph nodes. Both iCliniq and ChatDoctor additionally recommended that a biopsy and radiological diagnosis would be necessary if initial treatments proved unsuccessful. However, ChatGPT’s response was limited to advising the patient to consult with an Ear, Nose, and Throat (ENT) specialist.
图11:示例2:一位患者报告称喉咙里有一个白色的肿块已经几个月了,并表达了对于可能癌症的担忧。iCliniq、ChatGPT和ChatDoctor这三个实体都表示患者可能是在应对异常肿大的淋巴结。iCliniq和ChatDoctor还额外建议,如果初步治疗失败,将需要进行活组织检查和放射学诊断。然而,ChatGPT的回应仅限于建议患者咨询耳鼻喉科(ENT)专家。

FIGURE 12: Example 3: a patient reported experiencing a sharp back pain during exercise, which intensified during breathing and rotation of the torso or neck. The patient was unsure whether urgent medical attention was necessary. ChatDoctor generated a closer answer to iCliniq than ChatGPT.
图12:示例3:一位患者报告在锻炼时经历了剧烈的背部疼痛,呼吸或转动躯干或颈部时疼痛加剧。患者不确定是否需要紧急医疗关注。ChatDoctor给出的答案比ChatGPT更接近iCliniq的答案。

FIGURE 13: Example 4: a patient experienced blurred vision and was particularly concerned about the health of their left eye. Taking into consideration the patient’s past medical history of retinal detachment, all three sources—iCliniq, ChatGPT, and ChatDoctor—advised the individual to seek professional consultation with ophthalmologists for a comprehensive assessment and swift treatment. Due to possible limitations in providing medical diagnoses (and advice), ChatGPT did not speculate on the cause of the diminished vision. On the other hand, both iCliniq and ChatDoctor identified the possibility of retinal detachment or bleeding as potential issues.
图13:示例4:一位患者出现了视力模糊,尤其担心左眼的健康状况。考虑到患者过去有视网膜脱落的医疗史,iCliniq、ChatGPT和ChatDoctor这三个来源都建议个人寻求眼科医生的专业咨询,进行全面评估和迅速治疗。由于在提供医疗诊断(和建议)方面可能存在限制,ChatGPT没有推测视力减退的原因。另一方面,iCliniq和ChatDoctor都识别出视网膜脱落或出血的可能性作为潜在问题。
Discussion
The medical LLM, ChatDoctor, which has been fine-tuned on medical data, has extensive potential uses.These range from preliminary patient assessment and automated case adjudication to proactive healthcare measures. Nevertheless, owing to the complex nature of medical information [16], any concealed inaccuracies in diagnoses and health advice could lead to severe outcomes [17]. LLMs are known to occasionally generate fallacious and harmful assertions (hallucinations) about areas beyond their knowledge expertise, potentially causing medical malpractice [18]. To mitigate this, ChatDoctor has been trained using real-world patient-doctor interactions to better understand patients’ questions and deliver more knowledgeable responses. To make the model most capable of answering questions about the latest medical terms (which may not be contained in the training dataset), and to introduce additional external references for verification, we also equipped the ChatDoctor model with the ability to autonomously retrieve information from external knowledge brains to provide answers, further enhancing the credibility of the model [19]. Such external knowledge retrieval can be called by inputting pre-configured prompts into the model. In future developments, the internal prior knowledge of the ChatDoctor model (gained through training) and the external knowledge brain can be further combined by training ChatDoctor to select a more trustworthy answer, or merge and fuse both answers or provide alternative opinions.
讨论
经过医学数据微调的医疗LLM,ChatDoctor,具有广泛的应用潜力。这些应用范围从初步的患者评估和自动病例评估到主动的医疗保健措施。然而,由于医学信息的复杂性[16],诊断和健康建议中的任何潜在不准确之处都可能导致严重后果[17]。LLM有时会生成超出其知识领域的虚假和有害声明(幻觉),可能导致医疗事故[18]。为了减轻这一点,ChatDoctor已被训练使用真实世界的患者-医生互动来更好地理解患者的问题并提供更有见识的回应。为了使模型能够回答最新医学术语的问题(这些术语可能不在训练数据集中),并为验证引入额外的外部参考,我们还使ChatDoctor模型具备了从外部知识大脑自主检索信息以提供答案的能力,从而进一步增强了模型的可信度[19]。这种外部知识检索可以通过向模型输入预配置的提示来调用。在未来的发展中,ChatDoctor模型通过训练获得的内部先验知识和外部知识大脑可以进一步结合,通过训练ChatDoctor选择更可靠答案,或合并融合两个答案,或提供替代意见。
Limitations
It is important to emphasize that the current ChatDoctor model is still in the investigation phase and has been developed for academic research only. The actual clinical use is subject to the risk of wrong answers being output by the model, and the use of exclusively LLMs in medical diagnosis is still plagued by false positives and false negatives for the time being. Additional security measures, including automated reference checking and human expert evaluation, are needed to cross-validate the answers provided by ChatDoctor to flag potentially inaccurate answers and prevent hallucinations. The exact design, development and deployment of such security measures remains an important topic for further research. A more secure application at this stage is the use of LLMs to assist physicians in their face-to-face consultations. Physicians and ChatDoctor work together to ensure not only that the technology is consistent with clinical practice, but also that patient safety is ensured. The evaluation and potential approval of such tools for healthcare-related purposes also needs further investigation.
局限性
重要的是要强调,目前的ChatDoctor模型仍处于研究阶段,仅用于学术研究。实际临床应用存在模型输出错误答案的风险,而且仅凭LLM进行医疗诊断目前仍受到假阳性和假阴性的困扰。需要额外的安全措施,包括自动参考检查和人类专家评估,以交叉验证ChatDoctor提供的答案,标记潜在的不准确答案并防止幻觉。此类安全措施的确切设计、开发和部署仍是进一步研究的重点。在这个阶段,一个更安全的应用是使用LLM协助医生进行面对面咨询。医生和ChatDoctor共同工作,确保技术符合临床实践,同时确保患者安全。此类工具在医疗相关目的上的评估和潜在批准也需要进一步的研究。
Conclusions
With adequate training and online/offline supervision, ChatDoctor can potentially improve accuracy and efficiency in medical diagnosis and reduce the workload for medical professionals. It may also increase access to high-quality medical consultations, especially for patients in underserved regions with limited medical resources. The further developments and applications of ChatDoctor may eventually help to improve patient outcomes and advance medical research.
结论
在充分的训练和在线/离线监督下,ChatDoctor有望提高医疗诊断的准确性和效率,减轻医疗专业人员的工作负担。它还可能增加对高质量医疗咨询的访问,尤其是对医疗资源有限的欠发达地区的患者。ChatDoctor的进一步发展和应用最终可能有助于改善患者结果并推动医学研究。
Additional Information
Disclosures
Human subjects: All authors have confirmed that this study did not involve human participants or tissue. Animal subjects: All authors have confirmed that this study did not involve animal subjects or tissue.Conflicts of interest: In compliance with the ICMJE uniform disclosure form, all authors declare the following: Payment/services info: This work was supported by the National Institutes of Health (Grant No.R01 CA240808, R01 CA258987). Financial relationships: All authors have declared that they have no financial relationships at present or within the previous three years with any organizations that might have an interest in the submitted work. Other relationships: All authors have declared that there are no other relationships or activities that could appear to have influenced the submitted work.
附加信息
披露
人类受试者:所有作者都确认这项研究没有涉及人类参与者或组织。动物受试者:所有作者都确认这项研究没有涉及动物参与者或组织。利益冲突:符合ICMJE统一披露表格,所有作者声明如下:支付/服务信息:这项工作得到了美国国立卫生研究院(Grant No. R01 CA240808, R01 CA258987)的支持。财务关系:所有作者都声明他们目前或过去三年内没有与可能对提交工作感兴趣的任何组织有任何财务关系。其他关系:所有作者都声明没有其他关系或活动可能影响提交的工作。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









