






本文探讨了使用 Retrieval-Augmented Generation (RAG) 技术在 Google Cloud 平台上构建产品推荐系统的两种方法:灵活的 LangChain 框架和完全托管的 Vertex AI RAG 引擎。这两种方法都利用 Vertex AI Search 作为核心矢量数据库来存储和检索产品嵌入。作者对比了这两种方法,展示了 LangChain 提供的细粒度控制能力以及 Vertex AI RAG 引擎的简化、统一体验。此外,文章还简要概述了其他可与这些 RAG 解决方案集成的矢量数据库选项,如 PgVector、BigQuery、Pinecone和 Weaviate。最后,作者探讨了将 RAG 应用程序与聊天机器人界面集成的可能性,为读者提供了全面的 RAG 实现洞见。
关键要点
使用 LangChain 和Vertex AI RAG 引擎在 Google Cloud 上构建 RAG 应用程序。
Vertex AI Search 作为底层矢量数据库在两种方法中都有应用。
LangChain 提供了更多灵活性和定制控制能力,而 Vertex AI RAG 引擎则提供了更简化的托管体验。
文章还简要介绍了其他可选的矢量数据库,如 PgVector、BigQuery、Pinecone和 Weaviate。
作者探讨了将 RAG 应用程序与聊天机器人界面集成的可能性。
使用 Vertex AI Search 在亚马逊商品数据上比较 LangChain 和 Vertex AI RAG 引擎
Gemini 2.0 型号
Google 在 AI 竞赛中似乎一直落后,但随着 2.0 年之前 G emini 2025 的发布,感觉他们终于以有意义的方式赶上了。起初我不确定会发生什么,但试用后,它的功能给我留下了深刻的印象。这甚至让我想知道是否还需要 ChatGPT、Claude 或Llama 等工具。Gemini live 多模态 API 可以轻松处理复杂的业务问题,并与 Google 的现有工具(如 Search 和 Maps)顺利集成。最重要的是,Google 的托管产品,例如 RAG Engine 、 AI Agent Builder 和 Vertex AI for Retail ,都是可靠的,他们与 LangChain 合作进行灵活的 AI 开发,使构建适应性强的 AI 解决方案更加简单。
为了进行测试,我使用了 Hugging Face 的 2023 年 Amazon 产品数据集来构建一个基于 RAG 的产品推荐系统,将 LangChain 与 Vertex AI RAG 引擎进行了比较。这次经历既实用又富有洞察力,展示了Gemini在解决现实世界业务挑战和实现灵活的AI开发方面的巨大潜力。
接下来,我将探索 Vertex AI for Retail 和 Advanced AI Agent Builder 功能,并将在我的进步中分享我的见解。
介绍
本文探讨了 Retrieval-Augmented Generation (RAG) 在产品推荐中的实现,特别关注构建一个可以回答用户查询并推荐相关产品的系统。我们将深入研究 Google Cloud Platform 上的两种主要方法:利用流行的LangChain 框架和完全托管的 Vertex AI RAG 引擎,两者都使用 Vertex AI Search 作为底层向量数据库。虽然 PgVector、BigQuery、Pinecone、Weaviate和 Vertex AI Feature Store 等其他矢量数据库可以与这些 RAG 解决方案集成,但本文将专注于 Vertex AI Search 以进行重点比较,并在结论中简要概述其他数据库选项。

LangChain 与 Vertex AI 引擎
什么是检索增强生成 (RAG)?
检索增强生成 (RAG) 是一种强大的AI 技术,它结合了三种方法的优势:检索、增强和生成。
-
检索:在此步骤中,RAG 系统首先搜索大量文档语料库(知识库),以查找与给定输入查询或提示相关的信息。这就像在数据库中搜索或使用搜索引擎一样。目标是找到最相关的文档或段落,这些文档或段落可能包含查询的答案或提供有用的上下文。
-
Augmentation
:这是使用检索到的信息来增强原始查询或提示的关键步骤。检索到的文档(或其中的一部分)将添加到将馈送到语言模型的输入中。这为模型提供了它本来无法访问的外部知识。
-
生成:最后,大型语言模型 (LLM) 采用增强的输入(原始查询 + 检索到的上下文)并使用它来生成全面且连贯的响应。LLM 现在可以利用检索步骤中的附加信息来生成更明智、更准确且与上下文相关的输出。
从本质上讲,RAG 通过外部知识增强了LLM 的生成能力。检索到的上下文有助于 LLM 提供更准确和真实的回答,减少幻觉(编造信息),并回答有关其初始训练数据之外的主题的问题。
类比:想象一下你正在写一篇文章。除了仅仅依赖您的内存(如标准 LLM),您还可以使用库(检索组件)。您首先在图书馆中搜索相关的书籍和文章(检索),然后将这些来源的信息整合到您的论文提示中(增强)。最后,你写你的文章,利用你的知识和从图书馆(一代)新获得的信息。
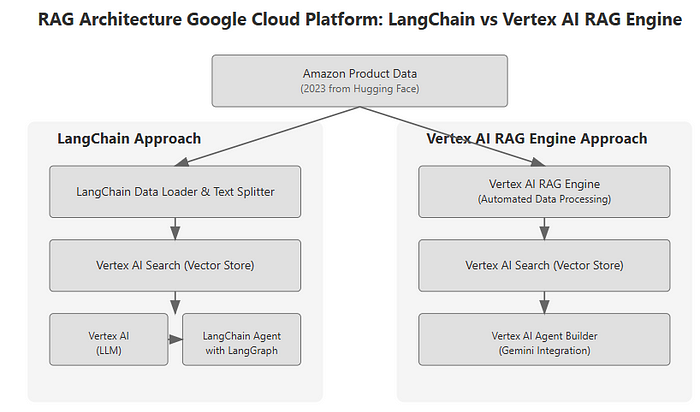
RAG 架构
RAG 在产品推荐方面的强大功能
在产品推荐方面,RAG 可以显著增强用户体验并改善业务成果。方法如下:
- 增强的产品推荐: RAG 可以通过检索类似于用户查询或浏览历史的产品,考虑文本描述、功能甚至客户评论等因素,从而提供更加相关和个性化的产品推荐。
- 改进的搜索功能:RAG 可以超越关键字匹配来理解用户查询的语义,从而在在线商店或产品目录中获得更准确、更有用的搜索结果。
- AI 驱动的聊天机器人: RAG 支持创建智能聊天机器人,这些机器人可以通过从产品目录、常见问题解答和其他相关文档中检索信息来回答客户有关产品、运输、退货和其他相关主题的问题。
- 动态内容生成: RAG 可用于根据检索到的产品信息和用户偏好生成动态产品描述、营销材料,甚至是个性化电子邮件内容。
通过将大型语言模型建立在外部知识源中,RAG 有助于克服知识中断和幻觉等限制,使其更可靠,更适用于产品推荐和其他应用程序。
Google 还提供 Vertex AI Search for Retail ,其中包括用于产品发现的预配置场景,并且易于使用。
https://cloud.google.com/solutions/retail-product-discovery?hl=en
面向零售业的 Google Vertex AI 搜索
Google Cloud 上的RAG:LangChain 与 Vertex AI RAG 引擎
本文探讨了在 Google Cloud 上构建 RAG 应用程序的两种主要方法:
- LangChain :一种流行的开源框架,用于开发具有大型语言模型的应用程序。它提供了一种灵活的模块化方式来构建 RAG 管道。虽然 LangChain 可以与各种 Google Cloud 服务(如 Vertex AI Search、PgVector 和 BigQuery)以及其他矢量数据库(如 Pinecone 和 Weaviate)集成,但本文将重点介绍如何将 LangChain 与 Vertex AI Search 结合使用。
- Vertex AI RAG 引擎 :一种更新的完全托管式服务,专为在 Google Cloud 上构建 RAG 应用程序而设计。它通过处理许多底层复杂性(包括数据摄取、嵌入生成和向量存储/检索)来简化开发。本文将主要关注如何使用 Vertex AI Vector Search 作为其底层向量数据库。其他选项(如 Pinecone 、 Weaviate 、 Vertex AI Feature Store 和默认 RagManagedDb )也可用,但此处仅包含在结论中以了解。
其他 Vector 数据库概述
虽然本文重点介绍 Vertex AI Search,但以下是与 LangChain 和 Vertex AI RAG 引擎兼容的其他一些矢量数据库选项:
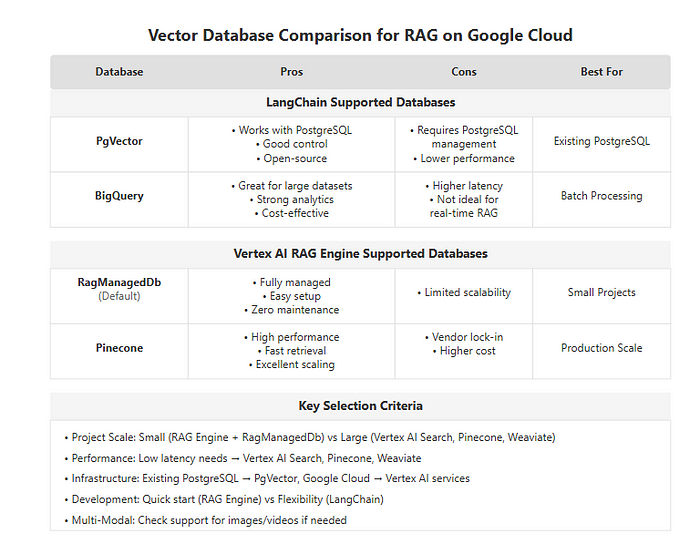
选择正确的解决方案和载体数据库
适合您项目的最佳 RAG 解决方案和矢量数据库取决于以下几个因素:
-
项目规模和复杂性:对于简单的原型或小规模的应用程序,带有 RagManagedDb 的 RAG 引擎或带有 BigQuery 的 LangChain 可能就足够了。对于更大、更复杂的项目,请考虑使用 LangChain 和 Vertex AI Search 或使用 RAG 引擎和 Vertex AI Search、Pinecone 或 Weaviate。
-
性能要求:如果低延迟检索至关重要,Vertex AI Search、Pinecone 和 Weaviate 通常是不错的选择。
-
现有基础设施:如果您已经在使用 PostgreSQL,那么带有 PgVector 的 LangChain 可能是一个不错的选择。如果您在 Google Cloud 上投入了大量资金,Vertex AI 服务可能更方便。
-
开发时间和精力: RAG 引擎由于其托管性质而提供更快的开发速度。LangChain 提供了更大的灵活性,但可能需要更多的开发时间。
-
成本:仔细评估每项服务(矢量数据库、LLM、RAG 引擎等)的定价模型,以估算您的使用案例的总体成本。
-
团队专业知识:选择符合您团队技能和经验的解决方案。
-
多模态需求:如果您计划在未来合并多模态嵌入(图像、视频),请确保所选的向量数据库支持它们或具有明确的集成路径。
最后的思考
LangChain 和 Vertex AI RAG 引擎都提供了在 Google Cloud 上构建RAG 应用程序的强大方法。LangChain 提供灵活性和控制,而 RAG 引擎提供简化的托管体验。通过了解每种方法的优缺点,并仔细考虑项目的具体要求,您可以选择最适合您需求的解决方案,并构建一个强大而有效的 RAG 驱动的产品推荐系统。请记住,RAG 领域正在迅速发展,因此紧跟框架和底层技术的最新进展至关重要。
技术实现细节
数据集:Hugging Face Amazon 评论(美容)
为了演示本文中的概念,我们将使用一个真实的数据集:Hugging Face Amazon Reviews 数据集,特别是“raw_meta_All_Beauty”拆分。
- 数据集来源:https://huggingface.co/datasets/McAuley-Lab/Amazon-Reviews-2023
- 内容:此数据集包含有关亚马逊上发布的美妆商品的元数据,包括商品名称、描述、功能、价格、评级和类别。
必需的 API 和服务
要构建我们的 RAG 应用程序,需要启用多个 Google Cloud API 和服务。您可以使用 Google Cloud 控制台(图形界面)或 gcloud 命令行工具 来执行此操作。以下是启用所需 API 的步骤:
选项 1:使用 Google Cloud Console
- 导航到 Google Cloud 控制台:
- 选择您的项目(例如,rag-product-recommendation或您选择的项目名称)。
- 单击“+ ENABLE API AND SERVICES”按钮。
- 搜索并启用以下 API:
新建项目
启用 API
核心 API (必需):
-
顶点 AI API
启用API并创建要使用的API密钥/凭据
文档:
顶点 AI API
凭据
-
双子座 API
启用 API:
文档:
双子座 API
-
云存储 API
启用 API:
文档:
选项 2:使用 gcloud CLI
如果您更喜欢使用命令行,可以使用以下命令启用所有必需的 API:
gcloud services enable \
aiplatform.googleapis.com \
generativelanguage.googleapis.com
安装 Google Cloud CLI:如果您没有,请按照以下说明操作:https://cloud.google.com/sdk/docs/install
IAM 权限
确保您使用的用户或服务账户具有访问和管理所需资源所需的 IAM 权限。此外,如果您需要完全控制权,我们需要授予 Vertex AI 管理员访问权限。以下是一些基本的 IAM 角色:
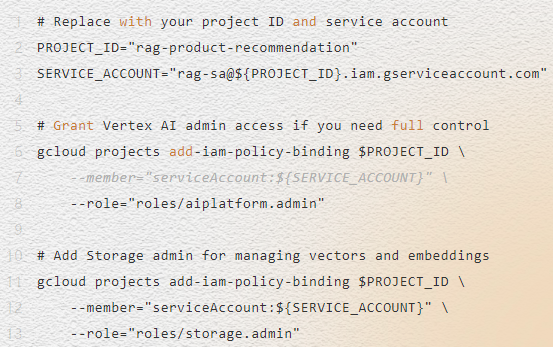
安装库 (SDK)
我们将为该项目使用以下 Python 库:
- google-cloud-aiplatform :适用于 Python 的 Vertex AI SDK。
- google-cloud-storage :用于与 Google Cloud Storage 交互。
- datasets :用于下载 Hugging Face 数据集。
- langchain :使用 LangChain 框架实现 RAG。
- langchain-google-vertexai :用于将 LangChain 与 Google Vertex AI 服务集成。
打开终端或命令提示符并运行以下命令:
pip install --upgrade google-cloud-aiplatform google-cloud-storage datasets langchain langchain-google-vertexai
数据加载、预处理和存储
在这里,我们将使用辅助函数在 GCS 中加载、清理和存储数据集。
从 Hugging Face 加载 Amazon Beauty 数据集
我们首先使用 Hugging Face datasets 库加载数据集。

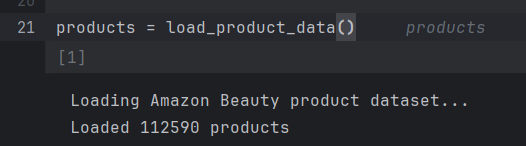
Amazon 2023 美容数据集中的产品总数
数据清理和预处理
此阶段涉及清理加载的数据以确保其质量和一致性。
def clean_product_data(products, debug_sample_size=5):
print("\nStarting data cleaning with enhanced price analysis...")
initial_count = len(products)
# Enhanced price issue tracking
price_issues = {
'none_price': {'count': 0, 'examples': []}, # Specifically for 'None' string values
'missing_price': {'count': 0, 'examples': []}, # For None type values
'non_numeric_price': {'count': 0, 'examples': []}, # For other invalid formats
'empty_string': {'count': 0, 'examples': []}, # For empty strings
'other_issues': {'count': 0, 'examples': []} # For unexpected cases
}
cleaned_products = []
for product in products:
if not product.get('title'):
continue
try:
price = None
raw_price = product.get('price')
# Categorize price issues
if raw_price is None:
price_issues['missing_price']['count'] += 1
if len(price_issues['missing_price']['examples']) < debug_sample_size:
price_issues['missing_price']['examples'].append({
'title': product.get('title'),
'raw_price': 'None (type)',
'price_type': type(raw_price).__name__
})
continue
if isinstance(raw_price, str):
if raw_price.lower() == 'none':
price_issues['none_price']['count'] += 1
if len(price_issues['none_price']['examples']) < debug_sample_size:
price_issues['none_price']['examples'].append({
'title': product.get('title'),
'raw_price': raw_price
})
continue
if not raw_price.strip():
price_issues['empty_string']['count'] += 1
if len(price_issues['empty_string']['examples']) < debug_sample_size:
price_issues['empty_string']['examples'].append({
'title': product.get('title'),
'raw_price': 'empty string'
})
continue
# Try to clean and convert non-None string prices
try:
cleaned_price = raw_price.replace('$', '').replace(',', '').strip()
price = float(cleaned_price)
except ValueError:
price_issues['non_numeric_price']['count'] += 1
if len(price_issues['non_numeric_price']['examples']) < debug_sample_size:
price_issues['non_numeric_price']['examples'].append({
'title': product.get('title'),
'raw_price': raw_price,
'price_type': type(raw_price).__name__
})
continue
elif isinstance(raw_price, (int, float)):
price = float(raw_price)
else:
price_issues['other_issues']['count'] += 1
if len(price_issues['other_issues']['examples']) < debug_sample_size:
price_issues['other_issues']['examples'].append({
'title': product.get('title'),
'raw_price': raw_price,
'price_type': type(raw_price).__name__
})
continue
if price is not None and price > 0:
cleaned_product = product.copy()
cleaned_product['price'] = price
cleaned_products.append(cleaned_product)
except Exception as e:
price_issues['other_issues']['count'] += 1
if len(price_issues['other_issues']['examples']) < debug_sample_size:
price_issues['other_issues']['examples'].append({
'title': product.get('title'),
'raw_price': raw_price,
'error': str(e)
})
# Print detailed analysis
print("\nDetailed Price Analysis:")
print(f"Total products analyzed: {initial_count}")
print(f"Products with valid prices: {len(cleaned_products)}")
print("\nPrice Issue Breakdown:")
total_issues = 0
for issue_type, data in price_issues.items():
if data['count'] > 0:
print(f"\n{issue_type.replace('_', ' ').title()}:")
print(f"Count: {data['count']}")
total_issues += data['count']
if data['examples']:
print("Example products:")
for idx, example in enumerate(data['examples'][:debug_sample_size], 1):
print(f" {idx}. {example}")
print(f"\nTotal invalid prices: {total_issues}")
print(f"Final valid products: {len(cleaned_products)}")
return cleaned_products
# Run the enhanced analysis
cleaned_products = clean_product_data(products)
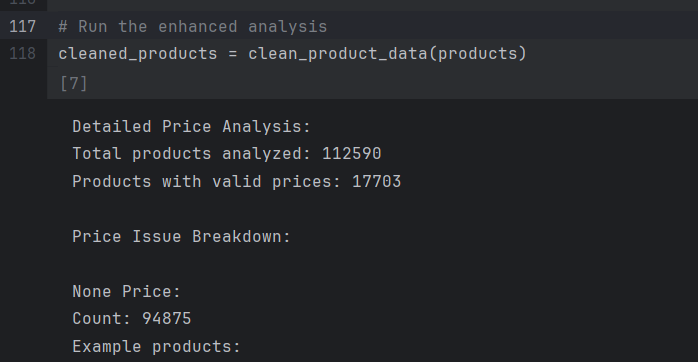
清理后的产品计数
为 RAG 准备数据(JSONL格式)
为了有效地准备数据以摄取到 Vertex AI RAG 引擎中,我们现在将清理后的产品数据格式化为 JSON 行 (JSONL) 格式,并在每个文件中存储多个产品。
- JSON 行格式:在 JSONL 中,每行都是一个有效的 JSON 对象。这种格式非常适合大型数据集,并且受 RAG 引擎import_files()方法支持。
- 每个文件多个产品:我们不会为每个产品创建单独的文件,而是将多个产品分组到每个 JSONL 文件中。这样可以减少文件总数,并且可以提高导入效率。
from google.cloud import storage
import os
import json
# Configuration for Google Cloud Storage
PROJECT_ID = "rag-product-recommendation" # Replace with your project ID
BUCKET_NAME = "rag-genaipros" # Replace with your bucket name
OUTPUT_PREFIX = "amazon_product_data"
GCS_BUCKET_PATH = f"gs://{BUCKET_NAME}/{OUTPUT_PREFIX}"
def upload_batch_to_gcs(bucket, batch, output_prefix, file_counter):
file_name = f"{output_prefix}/products_{file_counter}.jsonl"
blob = bucket.blob(file_name)
# Convert batch to JSONL format
jsonl_data = "\n".join(json.dumps(product) for product in batch)
# Upload to GCS
blob.upload_from_string(jsonl_data, content_type="application/jsonl")
print(f"Uploaded {len(batch)} products to gs://{bucket.name}/{file_name}")
def prepare_data_for_rag_jsonl(cleaned_products, bucket_name, output_prefix, products_per_file=1000):
print(f"\nPreparing data upload to GCS...")
# Initialize GCS client
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.bucket(bucket_name)
# Batch processing variables
file_counter = 0
product_counter = 0
batch = []
total_products = len(cleaned_products)
for product in cleaned_products:
# Create a standardized product entry
product_data = {
"title": product.get("title", ""),
"price": product.get("price", "N/A"),
"rating": product.get("average_rating", "N/A"),
"category": product.get("main_category", ""),
"features": product.get("features", ""),
"description": product.get("description", ""),
# Keep URLs for potential future multi-modal implementation
"image_urls": product.get("image_urls", []),
"video_urls": product.get("video_urls", []),
}
batch.append(product_data)
product_counter += 1
# When batch is full, upload it
if product_counter >= products_per_file:
upload_batch_to_gcs(bucket, batch, output_prefix, file_counter)
print(f"Progress: {min((file_counter + 1) * products_per_file, total_products)}/{total_products} products processed")
file_counter += 1
product_counter = 0
batch = []
# Upload any remaining products
if batch:
upload_batch_to_gcs(bucket, batch, output_prefix, file_counter)
print(f"Final batch uploaded: {total_products}/{total_products} products processed")
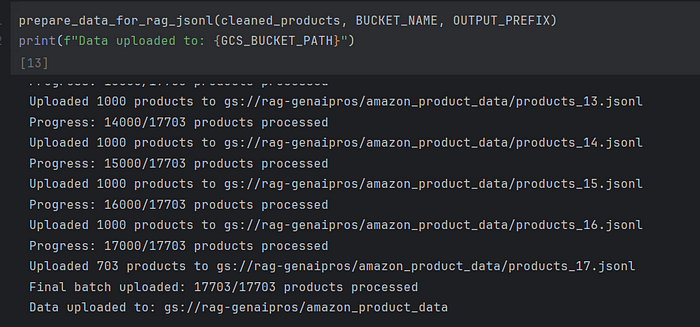
加载到 GC Bucket 的数据
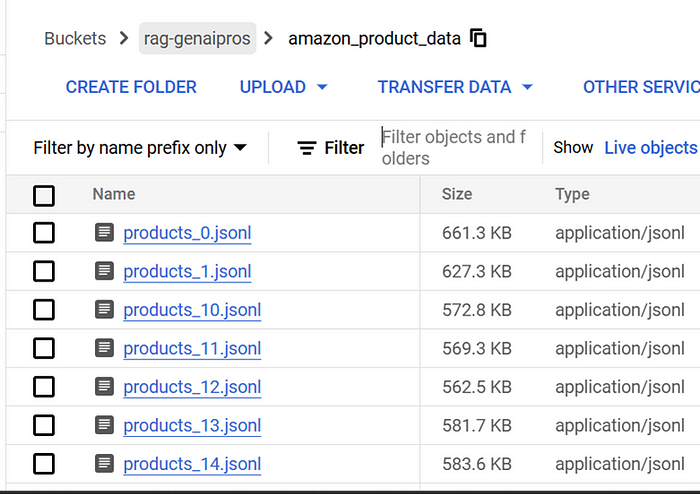
云存储桶 ProductFiles
为什么要将数据加载到 Google Cloud Storage (GCS)?
使用 Vertex AI RAG 引擎构建 RAG 管道时,将数据存储在 Google Cloud Storage (GCS) 中是关键步骤。虽然数据集最初可以使用该datasets库直接从 Hugging Face 加载,但 GCS 确保数据可以在 Google Cloud 生态系统中访问,从而通过该方法rag.import_files()无缝摄取到 RAG 语料库中。GCS 提供处理大型数据集所需的可扩展性和效率,为处理数百万条产品记录提供高性能。它还支持数据管理和版本控制,从而可以轻松跟踪产品目录随时间的变化。此外,将数据存储在 GCS 中可以与其他 Google Cloud 服务顺利集成,例如用于预处理的 Dataflow 和用于 CI/CD 的 Cloud Build,从而为您的 RAG 解决方案创建统一且优化的流水线。
选择嵌入模型
在本系列文章中,我们将使用 Vertex AI 的 text-embedding-005 模型。这是一个功能强大的文本嵌入模型,可为各种下游任务(包括信息检索)提供高质量的嵌入。
text-embedding-005 的主要特点:
-
高质量嵌入:该模型在海量数据集上进行训练,并生成可有效捕获语义含义的嵌入。
-
768
维:该模型生成具有 768 维的嵌入,从而提供丰富的文本表示。
-
针对检索进行了优化:此模型专为像我们这样的使用案例而设计,在这些用例中,我们需要根据其文本内容查找类似的项目。
编号:https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings-api
初始化嵌入模型
在生成 embedding 之前,我们需要使用 Vertex 初始化 embedding 模型
from langchain_google_vertexai import VertexAIEmbeddings
TEXT_EMBEDDING_MODEL_NAME = "text-embedding-005"
text_embedding_model = VertexAIEmbeddings(model_name=TEXT_EMBEDDING_MODEL_NAME)
print(f"Initialized embedding model: {TEXT_EMBEDDING_MODEL_NAME}")
从 Google Cloud Storage (GCS) 加载数据
由于我们将同时使用 LangChain 和 Vertex AI RAG 引擎,因此我们需要两者都可以访问我们的数据。在上一篇文章中,我们已经将数据上传到 GCS,因此在这里我们将定义一个函数来从 GCS 加载数据:
TEXT_EMBEDDING_MODEL_NAME = "text-embedding-005"
INPUT_PREFIX = "amazon_product_data" # Prefix where JSONL files are stored
GCS_INPUT_PATH = f"gs://{BUCKET_NAME}/{INPUT_PREFIX}"
from langchain_google_vertexai import VertexAIEmbeddings
text_embedding_model = VertexAIEmbeddings(model_name=TEXT_EMBEDDING_MODEL_NAME)
print(f"Initialized embedding model: {TEXT_EMBEDDING_MODEL_NAME}")
def load_data_from_gcs(bucket_name, input_prefix):
print(f"\nLoading data from GCS: {GCS_INPUT_PATH}...")
storage_client = storage.Client(project=PROJECT_ID)
bucket = storage_client.bucket(bucket_name)
products = []
blobs = bucket.list_blobs(prefix=input_prefix)
for blob in blobs:
if blob.name.endswith(".jsonl"):
print(f"Processing: {blob.name}")
file_content = blob.download_as_string()
for line in file_content.decode("utf-8").splitlines():
try:
product = json.loads(line)
products.append(product)
except json.JSONDecodeError as e:
print(f"Error decoding JSON from line: {line}. Error: {e}")
print(f"Loaded {len(products)} products from GCS")
return products
def generate_text_embeddings_for_products(products, batch_size=1000):
print(f"\nGenerating text embeddings for {len(products)} products...")
all_embeddings = []
for i in range(0, len(products), batch_size):
batch = products[i:i + batch_size]
batch_embeddings = []
texts = [
f"Title: {product.get('title', '')} Description: {product.get('description', '')} Features: {product.get('features', '')}"
for product in batch
]
try:
batch_embeddings = text_embedding_model.embed_documents(texts)
all_embeddings.extend(batch_embeddings)
print(f"Processed batch {i // batch_size + 1}/{len(products) // batch_size + 1}")
except Exception as e:
print(f"Error generating embeddings for batch starting at index {i}: {e}")
print(f"Generated embeddings for {len(all_embeddings)} products.")
return all_embeddings
products = load_data_from_gcs(BUCKET_NAME, INPUT_PREFIX)
embeddings = generate_text_embeddings_for_products(products)
创建 LangChain Document 对象
现在,我们将使用来自 GCS products 的数据以及嵌入来创建 LangChain Document 对象,这些对象将用于我们的LangChain RAG 实现
from langchain_core.documents import Document
def create_langchain_documents(cleaned_products):
documents = []
for product in cleaned_products:
# Create the same text content structure as used in GCS
text_content = (
f"Title: {product.get('title', '')}\n"
f"Price: ${product.get('price', 'N/A')}\n"
f"Rating: {product.get('average_rating', 'N/A')} stars\n"
f"Category: {product.get('main_category', '')}\n"
f"Features: {product.get('features', '')}\n"
f"Description: {product.get('description', '')}"
).strip()
# Create metadata matching GCS JSONL structure exactly
metadata = {
"title": product.get("title", ""),
"price": product.get("price", "N/A"),
"rating": product.get("average_rating", "N/A"),
"category": product.get("main_category", ""),
"features": product.get("features", ""),
"description": product.get("description", ""),
"image_urls": product.get("image_urls", []),
"video_urls": product.get("video_urls", [])
}
# Create Document object with aligned structure
documents.append(
Document(
page_content=text_content,
metadata=metadata
)
)
return documents
documents = create_langchain_documents(cleaned_products)
创建 Vertex AI 搜索索引
首先,我们需要在 Vertex AI Search 中创建一个索引来存储我们的产品嵌入。索引本质上是数据的容器,允许进行高效的相似性搜索。


使用流和批处理更新创建索引的说明
在此设置中,为不同的目的创建了两个 Vertex AI Search 索引。RAG 引擎索引用于STREAM_UPDATE支持持续、低延迟的更新,使其成为数据频繁更改且需要立即可供检索的实时应用程序的理想选择。另一方面,LangChain 索引使用 BATCH_UPDATE ,它更适合数据更新频率较低的场景,从而允许高效的批量更新和优化的性能。这两个索引都使用 Tree-AH 算法进行配置,这是近似最近邻 (ANN) 搜索的可靠默认值,并使用嵌入维度、邻居计数和搜索准确性等参数进行调整,以处理模型生成的嵌入。这种双索引策略确保了灵活性,同时满足了 RAG 管道中的实时和批处理需求。
创建 Vertex AI 搜索终端节点
接下来,我们需要一个终端节点来为针对索引的查询提供服务。我将在这里展示其中一个作为示例。
#Create Endpoint
endpoints = aiplatform.MatchingEngineIndexEndpoint.list()
ENDPOINT_RESOURCE_NAME = None
for endpoint in endpoints:
if endpoint.display_name == "amazon_beauty_langchain_endpoint":
ENDPOINT_RESOURCE_NAME = endpoint.resource_name
print(f"Found existing endpoint: {ENDPOINT_RESOURCE_NAME}")
break
if not ENDPOINT_RESOURCE_NAME:
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name="amazon_beauty_langchain_endpoint",
description="Endpoint for serving product recommendations",
public_endpoint_enabled=True # Set to False if you don't need a public endpoint
)
ENDPOINT_RESOURCE_NAME = my_index_endpoint.resource_name
print(f"Created endpoint: {ENDPOINT_RESOURCE_NAME}")
将索引部署到终端节点
现在,我们将索引部署到终端节点,使其准备好为查询提供服务。
# Deploy Index to Endpoint ---
try:
my_index = aiplatform.MatchingEngineIndex(INDEX_RESOURCE_NAME)
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint(ENDPOINT_RESOURCE_NAME)
if my_index and my_index_endpoint:
index_deployed = False
for deployed_index in my_index_endpoint.deployed_indexes:
if deployed_index.index == my_index.resource_name:
index_deployed = True
print(
f"Index {my_index.resource_name} is already deployed to endpoint {my_index_endpoint.resource_name}"
)
break
if not index_deployed:
deployed_index_id = "amazon_beauty_langchain_deployed_index"
my_index_endpoint.deploy_index(
index=my_index, deployed_index_id=deployed_index_id
)
print(
f"Deployed index {my_index.resource_name} to endpoint {my_index_endpoint.resource_name} with deployed_index_id: {deployed_index_id}"
)
else:
print("Skipping deployment as the index is already deployed.") else: print("Index or endpoint not defined.")
except Exception as e:
print(f"Error during index deployment: {e}")
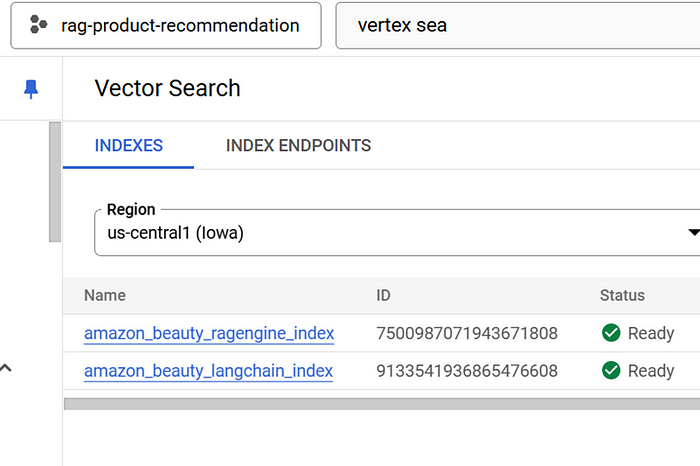
指数
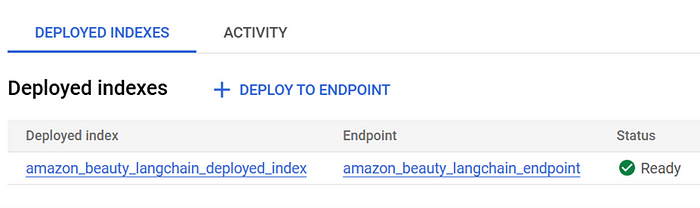
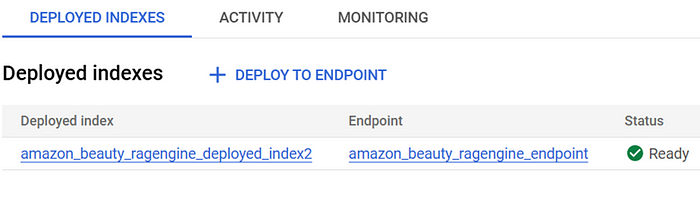
已部署的索引到终端节点
使用 LangChain 在Vertex AI Search 中存储嵌入
在这里,我们使用 LangChain VectorSearchVectorStore 连接到 Vertex AI Search,并添加我们的文档及其预计算的嵌入。
from langchain_google_vertexai import VectorSearchVectorStore
vector_store = VectorSearchVectorStore.from_components(
project_id=PROJECT_ID,
region=LOCATION,
index_id=INDEX_RESOURCE_NAME.split("/")[-1],
endpoint_id=ENDPOINT_RESOURCE_NAME.split("/")[-1],
embedding=text_embedding_model,
gcs_bucket_name=BUCKET_NAME.replace("gs://", "").split("/")[0]
)
batch_size = 5
for i in range(0, len(documents), batch_size):
batch_docs = documents[i : i + batch_size]
vector_store.add_documents(documents=batch_docs)
print(
f"Added batch {i // batch_size + 1}/{len(documents) // batch_size + 1} to Vertex AI Search"
)
print("Embeddings added to Vertex AI Search.")
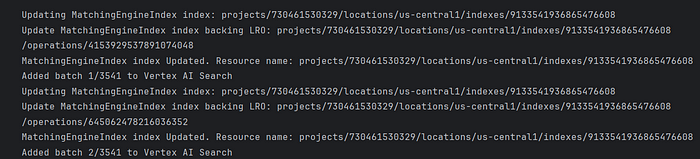
从 LangChain 嵌入向量更新索引
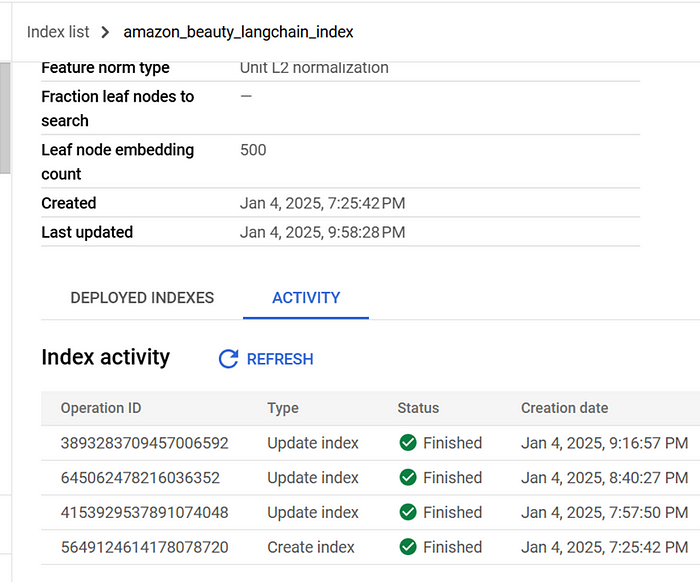
向量搜索索引的状态
使用 LangChain 构建RAG 链
现在,我们使用 LangChain 的组件构建 RAG 链:
from langchain_google_vertexai import ChatVertexAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = ChatVertexAI(
model_name="gemini-exp-1206", project=PROJECT_ID, location=LOCATION #gemini-1.5-pro
)
# Define prompt template
prompt_template = """
You are a helpful product recommender. Answer the question based on the context below.
If you don't know the answer, just say that you don't know. Don't try to make up an answer.
Context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
# Create retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 5}) # Retrieve top 5 documents
# Build RAG chain
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
print("RAG chain created with LangChain and Vertex AI Search.")
query = "Recommend a good moisturizing cream for sensitive skin under $30."
response = rag_chain.invoke(query)
print(f"Query: {query}")
print(f"Response: {response}")
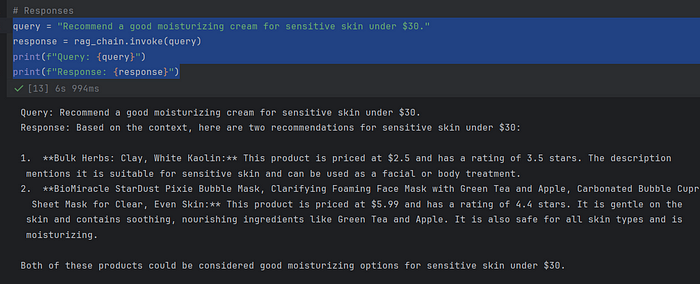
使用 Gemini 2.0 型号的产品推荐
RAG 实施 — 带有 Vertex AI Search 的 Vertex AI RAG 引擎
现在,我们将探索 Google Cloud 的完全托管式解决方案: Vertex AI RAG Engine .RAG 引擎通过在后台处理数据摄取、嵌入生成、矢量存储和检索,简化了创建 RAG 应用程序的过程。
Vertex AI RAG 引擎工作流程:
- 创建 RAG 语料库:RAG 语料库充当 RAG 引擎中数据的容器。
- 配置向量数据库:我们会将现有的 Vertex AI Vector Search 索引和端点链接到 RAG 语料库。
- 导入数据: 我们会将商品数据(以 JSONL 格式)从 GCS 导入 RAG 语料库。RAG 引擎将使用默认文本嵌入模型自动生成嵌入向量(如果需要,您也可以在语料库创建期间指定不同的嵌入向量)。
- 构建 RAG 工具和模型:我们将使用 Tool.from_retrieval() Gemini 模型创建一个检索工具并将其与 Gemini 模型集成。
- 查询和生成:我们将使用 Gemini 模型,并通过检索工具进行增强,根据 RAG 语料库中的数据回答用户查询。
#Vertex AI Vector Search as the vector database
vector_db = rag.VertexVectorSearch(
index=my_index.resource_name, index_endpoint=my_index_endpoint.resource_name
)
# RAG corpus
DISPLAY_NAME = "amazon-beauty-rag-engine"#
Create RAG Corpus
rag_corpus = rag.create_corpus(display_name=DISPLAY_NAME, vector_db=vector_db)
print(f"Created RAG Corpus resource: {rag_corpus.name}")
# Importing Data from GCS into the RAG Corpus
response = rag.import_files(
corpus_name=rag_corpus.name,
paths=[GCS_BUCKET_PATH],
chunk_size=1024,
chunk_overlap=100,
)
print(f"Data imported into RAG Corpus: {response}")
# Create a retrieval tool for the RAG Corpus
rag_resource = rag.RagResource(rag_corpus=rag_corpus.name)
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[rag_resource],
similarity_top_k=5,
vector_distance_threshold=0.4,
)
)
)
# Add the retrieval tool to the Gemini model
#rag_model = GenerativeModel("gemini-2.0-flash-exp", tools=[rag_retrieval_tool])
rag_model = GenerativeModel("gemini-exp-1206", tools=[rag_retrieval_tool])
print("RAG Tool and Model created.")
# --- Querying and Generating Responses ---
query = "Recommend a good moisturizing cream for sensitive skin under $30."
response = rag_model.generate_content(query)
print(f"Query: {query}")
print(f"Response: {response.text}")
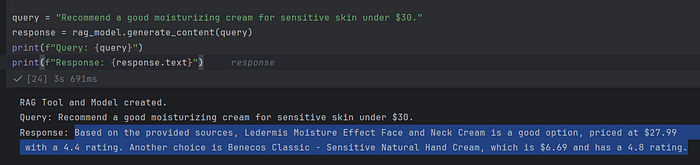
使用 Gemini 2.0 的 RAG推荐
与 Chatbot Interface 集成
我们构建的 RAG 应用程序,无论是使用 LangChain 还是 Vertex AI RAG 引擎,都可以通过与聊天机器人界面集成来进一步增强。这允许以交互式、对话方式访问您的产品推荐。虽然我们不会在这里深入研究完整的实施细节,但一种方法涉及将 RAG 模型部署为 Web 服务,例如在 Google Cloud Functions 上,然后将其连接到对话式 AI 平台,例如 Google Cloud 的 Vertex AI Agent Builder。Agent Builder 为设计和部署聊天机器人提供了一个用户友好的无代码环境。通过在Agent Builder 中配置指向您部署的 RAG 函数的webhook,您可以无缝地将用户查询路由到您的 RAG 模型,使聊天机器人能够根据检索到的信息和底层语言模型的生成能力提供智能的、数据驱动的产品推荐。简而言之,rag 应用程序可以很容易地作为聊天机器人公开。
from google.cloud import aiplatform
from vertexai.preview import rag
from vertexai.preview.generative_models import GenerativeModel, Tool
import functions_framework
# Configuration values
PROJECT_ID = "rag-product-recommendation"
LOCATION = "us-central1"
INDEX_DISPLAY_NAME = "amazon_beauty_ragengine_index"
ENDPOINT_DISPLAY_NAME = "amazon_beauty_ragengine_endpoint"
RAG_CORPUS_DISPLAY_NAME = "amazon-beauty-rag-engine"
def initialize_rag_components():
"""
Initializes the RAG system by setting up vector search and corpus components.
This function follows the same pattern that works in your notebook but is
adapted for the Cloud Functions environment.
"""
try:
# First, we need to get our index
indexes = aiplatform.MatchingEngineIndex.list(
filter=f'display_name="{INDEX_DISPLAY_NAME}"',
project=PROJECT_ID,
location=LOCATION,
)
if not indexes:
raise ValueError("Index not found")
my_index = indexes[0]
# Then get our endpoint
endpoints = aiplatform.MatchingEngineIndexEndpoint.list(
filter=f'display_name="{ENDPOINT_DISPLAY_NAME}"',
project=PROJECT_ID,
location=LOCATION,
)
if not endpoints:
raise ValueError("Endpoint not found")
my_index_endpoint = endpoints[0]
# Set up vector search
vector_db = rag.VertexVectorSearch(
index=my_index.resource_name,
index_endpoint=my_index_endpoint.resource_name
)
# Instead of listing corpora with project parameter, we'll try to get the corpus directly
try:
# First try to get existing corpus
rag_corpus = next(
(corpus for corpus in rag.list_corpora()
if corpus.display_name == RAG_CORPUS_DISPLAY_NAME),
None
)
if not rag_corpus:
# Create new corpus if it doesn't exist
rag_corpus = rag.create_corpus(
display_name=RAG_CORPUS_DISPLAY_NAME,
vector_db=vector_db
)
print(f"Created new RAG Corpus: {rag_corpus.name}")
else:
print(f"Using existing RAG Corpus: {rag_corpus.name}")
except Exception as e:
print(f"Error with corpus operations: {e}")
raise
# Create the RAG resource and retrieval tool
rag_resource = rag.RagResource(rag_corpus=rag_corpus.name)
rag_retrieval_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_resources=[rag_resource],
similarity_top_k=5,
vector_distance_threshold=0.4
)
)
)
# Initialize the model with the retrieval tool
return GenerativeModel("gemini-exp-1206", tools=[rag_retrieval_tool])
except Exception as e:
print(f"Error in initialize_rag_components: {e}")
raise
# Initialize the model globally
rag_model = initialize_rag_components()
@functions_framework.http
def query_rag(request):
"""
Cloud Function that handles RAG queries.
This function receives HTTP requests and returns responses using the RAG model.
"""
try:
request_json = request.get_json(silent=True)
if not request_json or 'query' not in request_json:
return {'error': 'Missing query parameter'}, 400
query = request_json['query']
response = rag_model.generate_content(query)
return {'response': response.text}
except Exception as e:
print(f"Error processing query: {e}")
return {'error': str(e)}, 500
gcloud functions deploy query_rag_function --region us-central1 --runtime python311 --source . --entry-point query_rag_function --trigger-http --allow-unauthenticated --timeout=540s
结论
在对用于产品推荐的检索增强生成 (RAG) 的全面探索中,我们介绍了 Google Cloud 上两种截然不同但功能强大的方法:灵活的开源LangChain 框架和完全托管的 Vertex AI RAG 引擎。这两种实施都利用 Vertex AI Search 作为核心向量数据库,展示了其高效存储和检索产品嵌入的能力。通过比较这些方法,我们了解了 LangChain 如何对 RAG 管道的各个方面进行精细控制,使其成为复杂场景和需要定制的开发人员的理想选择。相反,Vertex AI RAG 引擎提供了一种简化的、用户友好的体验,实现了许多复杂流程的自动化,并提供与 Google 的 Gemini 模型的无缝集成。虽然我们的重点仍然放在 Vertex AI 搜索上,但我们也承认更广泛的矢量数据库生态系统,包括PgVector 、 BigQuery 、 Pinecone 和 Weaviate ,每个数据库都根据项目规模、性能需求和现有基础设施提供独特的优势。最终,LangChain 和 Vertex AI RAG 引擎之间的选择取决于您项目的具体要求、团队的专业知识以及控制和易用性之间的理想平衡。本文为您提供了做出明智决策的知识,并为产品推荐等构建强大、智能的 RAG 应用程序,为未来探索多模态数据和更复杂的对话式 AI 界面奠定了基础。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。 

四、100+套大模型面试题库

五、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









