






大型语言模型(LLMs)已经彻底改变了AI领域,小型模型也在崛起。因此,即使是在旧的PC和智能手机上运行先进的LLMs也成为了可能。为了给大家一个起点,我们将探索三种不同的方法来本地与LLama 3.2进行交互。
先决条件
 在我们深入探讨之前,请确保你已经:
在我们深入探讨之前,请确保你已经:
-
安装并运行了Ollama
-
已经拉取了LLama 3.2模型(在终端中使用
ollama pull llama3.2)
现在,让我们来探索这三种方法!
Ollama的Python包提供了一种简便的方法,可以在你的Python脚本或Jupyter笔记本中与LLama 3.2进行交互。

这种方法非常适合简单的同步交互。但如果你想要流式接收响应呢?Ollama为你提供了AsyncClient:

方法二:使用Ollama API
对于那些更喜欢直接使用API或想要将LLama 3.2集成到非Python应用程序中的人,Ollama提供了一个简单的HTTP API。

这种方法为你提供了从任何能够发出HTTP请求的语言或工具与LLama 3.2进行交互的灵活性。
方法三:使用Langchain构建高级应用程序
对于更复杂的应用程序,特别是涉及文档分析和检索的应用程序,Langchain与Ollama和LLama 3.2可以无缝集成。
以下代码片段展示了加载文档、创建嵌入和执行相似性搜索的过程:
from langchain_community.document_loaders import DirectoryLoader, UnstructuredWordDocumentLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.llms import Ollama
from langchain_community.vectorstores import Chroma
# 加载文档
loader = DirectoryLoader('/path/to/documents', glob="**/*.docx", loader_cls=UnstructuredWordDocumentLoader)
documents = loader.load()
# 将文档拆分为多个块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(documents)
# 创建嵌入和向量存储
embeddings = OllamaEmbeddings(model="nomic-embed-text")
vectorstore = Chroma.from_documents(documents=splits, embedding=embeddings)
# 初始化LLama 3.2
llm = Ollama(model="llama3.2", base_url="http://localhost:11434")
# 执行相似性搜索并生成回答
query = "What was the main accomplishment of Thomas Jefferson?"
similar_docs = vectorstore.similarity_search(query)
context = "\n".join([doc.page_content for doc in similar_docs])
response = llm(f"上下文: {context}\n问题: {query}\n回答:")
print(response)
这种方法允许你构建能够使用LLama 3.2强大的语言理解能力来理解和推理大量文本数据的应用程序。
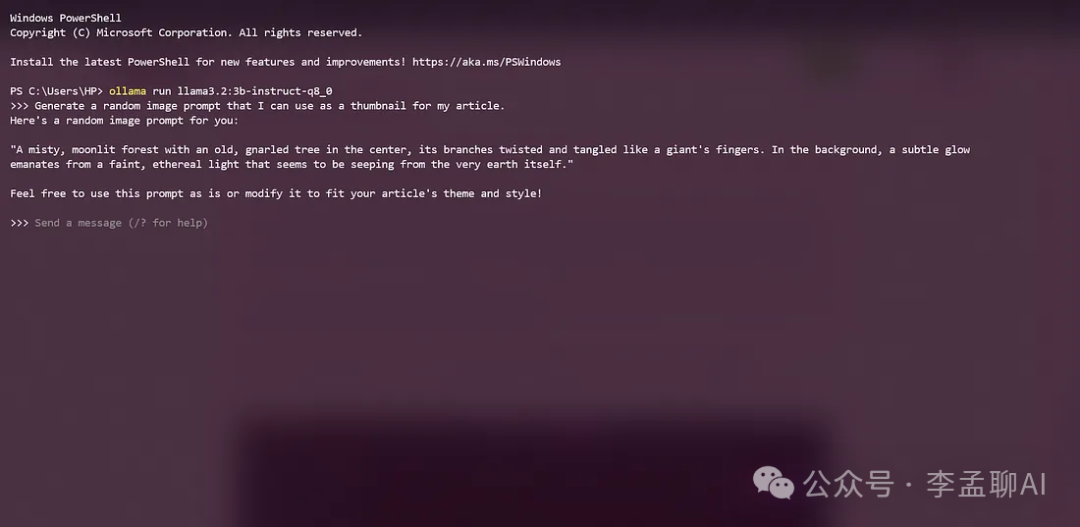
开始生成提示了!
下载成功后,你可以在终端中使用以下命令运行模型:
$ ollama run llama3.2:3b-instruct-q8_0
现在你已经可以生成一些图片提示了。假设我想为我的博客文章创建一个缩略图,于是我运行了下面的提示词:
Generate a random image prompt that I can use as a thumbnail for my article.
这是生成的结果:
Here's a random image prompt for you:
"A misty, moonlit forest with an old, gnarled tree in the center, its branches twisted and tangled like a giant's fingers. In the background, a subtle glow
emanates from a faint, ethereal light that seems to be seeping from the very earth itself."
Feel free to use this prompt as is or modify it to fit your article's theme and style!
 现在我准备在leonardo.ai网站上使用这个图片提示。这个网站非常适合从文本生成图片。你可以通过创建账户轻松开始制作图片。
现在我准备在leonardo.ai网站上使用这个图片提示。这个网站非常适合从文本生成图片。你可以通过创建账户轻松开始制作图片。
该网站每天为你提供150个可用积分。如果合理使用这些积分,它非常适合个人使用。

图片
如果你是这个平台的新手,可以使用我的图片生成设置,以下是具体的设置:
-
预设:Cinematic Kino
-
预设风格:Cinematic
-
对比度:Medium
-
图片尺寸:16:9, Medium
-
模型:Leonardo Lightning XL
结论
在本地运行LLama 3.2为AI驱动的应用程序打开了新的可能性。无论你是寻找简单的聊天交互、基于API的集成,还是复杂的文档分析系统,这三种方法都提供了适应各种使用场景的灵活性。
记住要负责任地、道德地使用这些强大的工具。编码愉快!
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









