






AI 语音交互大模型其实有两种主流的做法:
- All in LLM
- 多个模块组合, ASR+LLM+TTS
实际应用中,这两种方案并不是要对立存在的,像永劫无间这种游戏的场景,用户要的是低延迟,无障碍交流。并且能够触发某些动作技能。这就非常适合使用成熟的 ASR 和 TTS 技术来负责音频的处理,而 LLM 就可以专门做用户意图的理解。
1.数据
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
- 自动化的获取,就像 Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
- 半自动获取,我们可以借助一些更强大的生成模型比如 ChatGPT,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
- 用户使用数据, 类似商品和短视频推荐的数据,都是通过曝光点击行为来做训练的
- 人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值
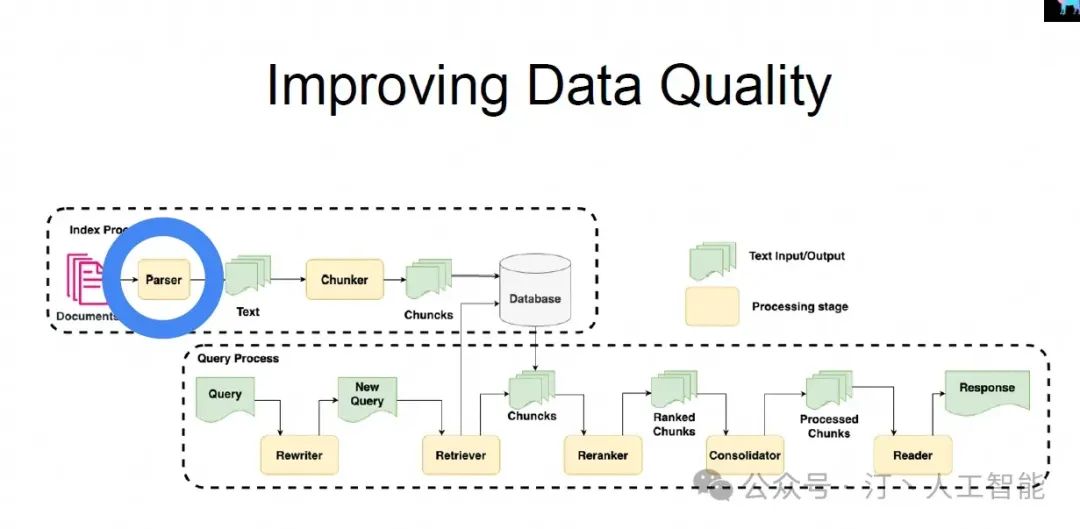
再有,要构建自己的数据闭环。在本次 AICon 中,很多演讲者就演讲了自己怎样构建自己的数据闭环的。这里的闭环指 用户使用 -> 生成的中间数据 -> 专家矫正和人工标注 -> 校正后的数据迭代整个系统或者模型。这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
2.问答场景多模态
整个 Aone Copilot 的问答,包括研小喵的问答都是采用 markdown 作为输出的富文本载体的,markdown 原生支持图片渲染的,所以我觉得借鉴小红书的方案,可以将图片信息通过 markdown 格式放入文本中。
这里需要注意
- 清洗数据的时候,需要确保文本是能够加载显示的,而不是无效的图片
- 图片本身 ocr 可能提供的信息有限,可以但是可以根据上下文信息,让大模型猜测图片可能的内容,这就有点像 NLP 的传统任务,完形填空,可以猜测的八九不离十
回头再看小红书的方案,他们放弃了图文类图片的对齐数据,若这块采用了图片问答(VQA)的模型描述图片,显然这种模型的运行速度还不能处理小红书海量的数据,所以采用这种根据文字推测图片方案或许也失为一种好的方法。
下面我们就节选本文的一部分内容进行实验
user:
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
1. 自动化的获取,就像Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
2. 半自动获取,我们可以借助一些更强大的生成模型比如chat-gpt,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
3. 用户使用数据, 类似广告推荐的数据,都是通过曝光点击行为来做训练的
4. 人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值
<image>
再有,要构建自己的数据闭环。在本次AICon中,很多演讲者就演讲了自己怎样构建自己的数据闭环的,这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
以上段落中,<image> 的地方是一张图片,根据上下文推测图片内容,限制在25个字
assistant:
图片内容可能是一个展示数据获取方法和数据闭环构建流程的流程图或示意图。
所以我们就可以可以这样存储待召回的数据
要是想训练一个大模型,去思考自己有什么样的数据,数据的获取方法有两种
1. 自动化的获取,就像Aone Copilot 代码补全场景一样,我们从原始的代码中通过某些规则扣出一块,作为模型的预测数据,我们只需要设定好策略就可以得到千万条数据用来训练
2. 半自动获取,我们可以借助一些更强大的生成模型比如chat-gpt,让他代替人工生成一些数据,再经过规则清洗得到最终使用的数据
3. 用户使用数据, 类似广告推荐的数据,都是通过曝光点击行为来做训练的
4. 人工标注,这种数据获取方法成本非常高,做这种事情的时候,千万先想好自己的业务诉求和价值

再有,要构建自己的数据闭环。在本次AICon中,很多演讲者就演讲了自己怎样构建自己的数据闭环的,这对于大模型非常重要,有了数据闭环才能说真正的达到了一个与大模型交互的系统上线的要求。
后面都是结合此次会议的内容,对技术层面的简述,也有部分有意思东西:
纯从特征融合的角度看,现有架构的多模态的大模型都是属于特征层的模态融合,这种融合方式相对于从数据层融合 (early fusion) 更加容易对齐数据而且可以限制特征空间,想对于各个模态的结果融合(later fusion)又有很大的发挥空间。
下面就举例一些经典的案例来说明其他模态的特征是如何与 transformer 交互的:
3.图像Vision Transformer
基于自注意力的架构,尤其是 Transformer,已成为 NLP 中的首选模型。由于 Transformers 的计算效率和可扩展性,训练具有超过 100B 个参数的、前所未有的模型成为了可能。随着模型和数据集的增长,仍未表现出饱和的迹象。
3.1 常见方法
将图像拆分为块 (patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块 (patches) 的处理方式同 NLP 的标记 (tokens)
当在没有强正则化的中型数据集(如 ImageNet)上进行训练时,这些模型产生的准确率比同等大小的 ResNet 低几个百分点。 但若在更大的数据集 (14M-300M 图像) 上训练,情况就会发生变化。我们发现 大规模训练 胜过 归纳偏置。Vision Transformer (ViT) 在以足够的规模进行预训练并迁移到具有较少数据点的任务时获得了出色结果。
图像块的嵌入 - 图像到 tokens
- Patch Embeddings
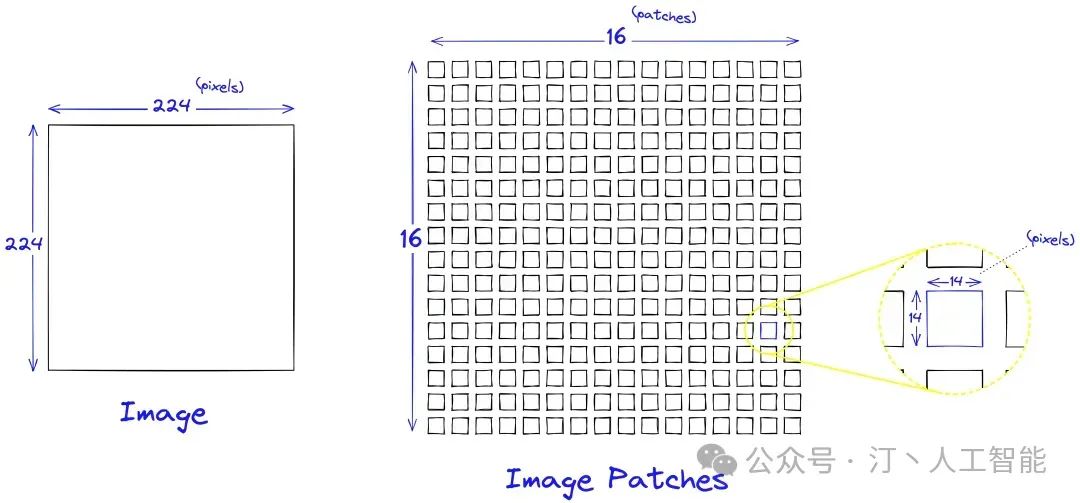
- Position Embeddings: Position embeddings 加到图像块中是为了保留位置信息的。
- Classification Token: 为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个 * 的块 0,叫额外的学习的分类标记 Classification Token。
- Transformer Encoder: 由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和多层感知机(MLP block)。
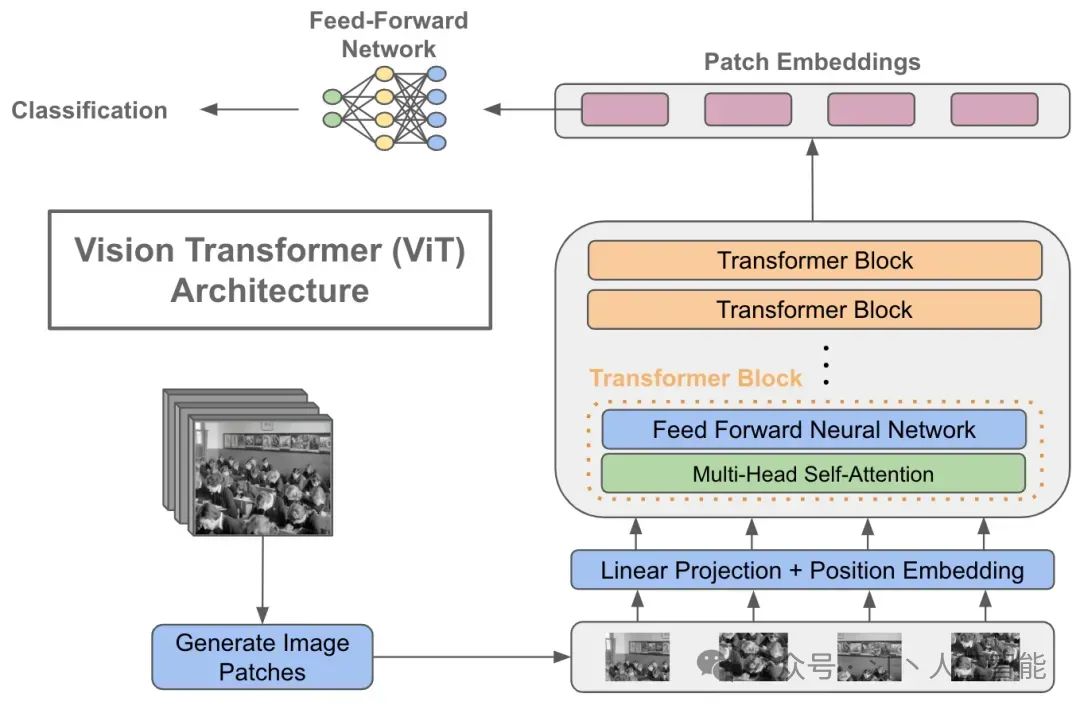
不同于 NLP 任务,NLP 任务的文本都是自回归的。 无论是之前的类似完形填空的 Masked Language Modeling (MLM), 后者预测 next token 等,VIT 还是使用类别预测来做训练的。
但是图像信息其实也有相互关联和冗余,其实也可以通过非监督的 MLM 方式来进行预训练,所以如下就是 BEIT 的工作成果
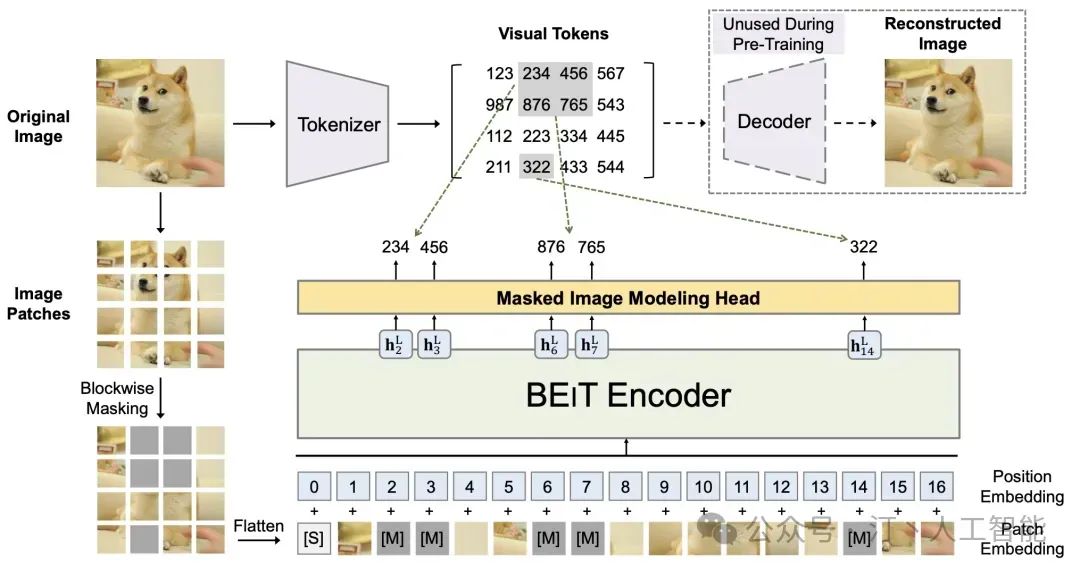
ICLR 2022 微软亚研院的一篇工作 BEIT: BERT Pre-Training of Image Transformers(ICLR 2022)
3.2 图像问答 VQA
好了,自从第一位大神将图像从纯深度 CNN-DNN 迁移到 tansformer 上,并证明了在大数据集下的优秀表现,图像的任务就逐步放弃了纯 CNN-DNN 的超级深度网络,转而投降与自然语言结合在一起,在 transformer 的加持下攻破了各种图片问答(VQA)的数据集,进而衍生出了更多复杂的玩法
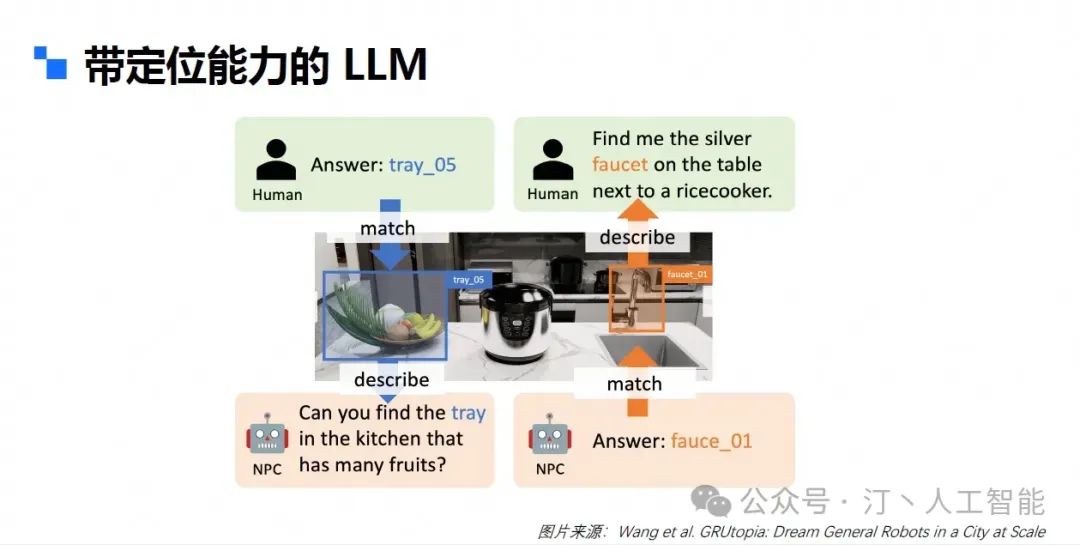
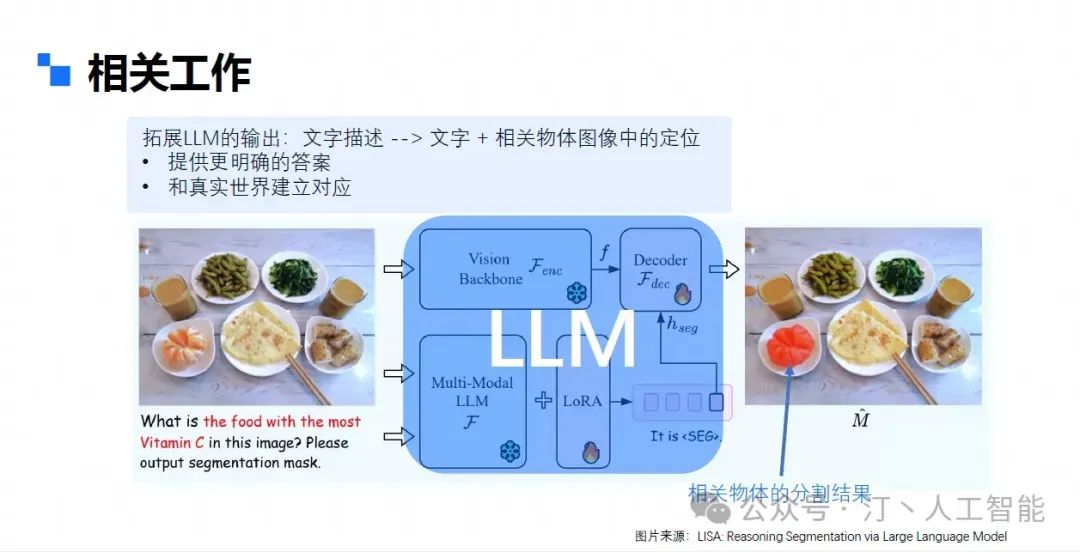
前面都是做图像问答和分割的,至于如何让大模型输出一个图像,现在主流的做法是采用扩散模型的方法来做(不过多展开),但是玩过 midjourney 都知道,用它来做艺术创作确实可以收货不错的灵感,但是要是用它来生成一个具体的带有业务含义的框图,其实比较难。 可以看看本文开头的第一幅图,就是用即梦的网页版本生成的图片,prompt 为 “多模态应用在生活的种种方面,生成一个多模态大模型应用于各个方面的图”,但是可以看见图片的细节,特别是文字,几乎都是不可阅读的。
4.语音
4.1 FunAudioLLM
通义的 FunAudioLLM 的介绍,但是用这个来了解音频大模型的构成,还是不错的一个样例
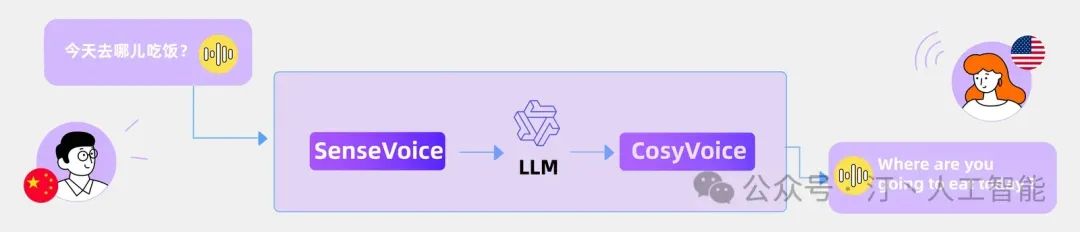
- SenseVoice
可以认为是提取语音的输入特征信息的模块
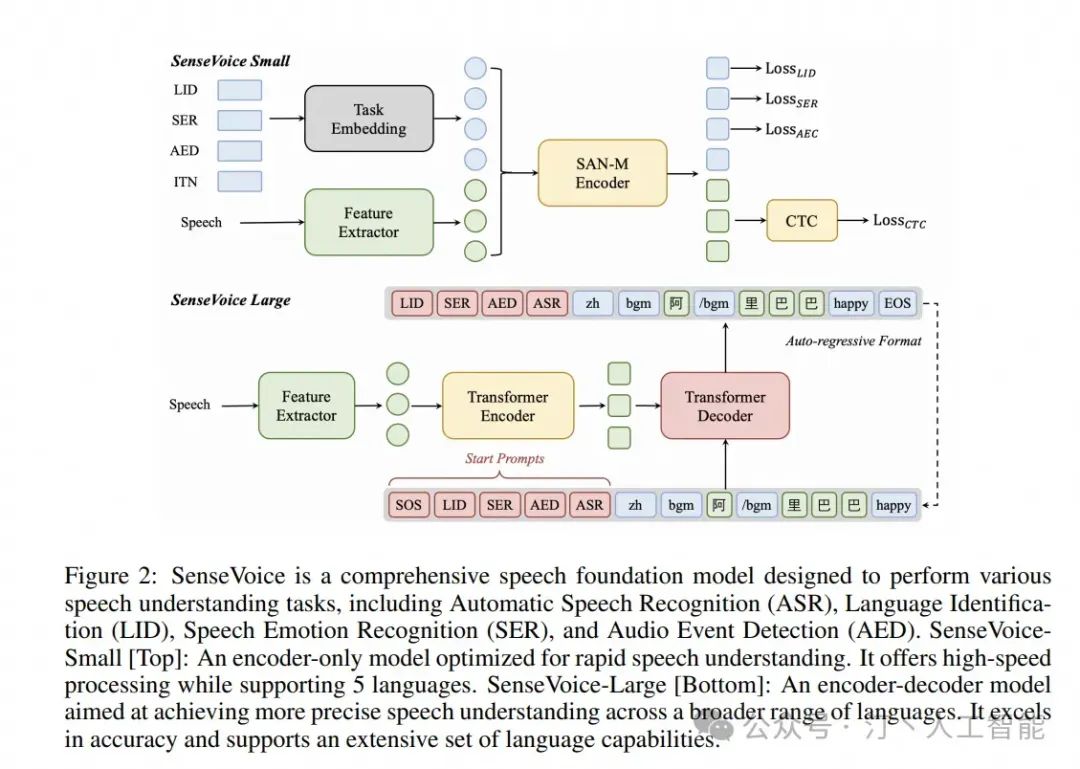
这里需要对输入的 LID,SER,AED,ITN 进一步说明下
ASR:通俗来说,就是语音转文字,其实是研究了很久的一项较为成熟的技术,在中国还能比较好的支持部分方言,主流的服务与说话的延迟差不多 1s 左右
SER:语音情感识别,我之前专门做过这个方向,差不多输出平静,高兴,悲伤,愤怒这 4 个标签 能够表征人物的语言情感
LID: 识别人说的是哪种语言,中文,英文,日文等等
AED:语音事件检测,比如哭声,掌声,鼾声等等。 很多家用摄像头就带这个功能,可以检测孩子哭声并及时报警。
除此之外,其实语音还有很多丰富的功能,比如男女,年龄范围等等。
- CosyVoice
可以认为是重建语音的模块
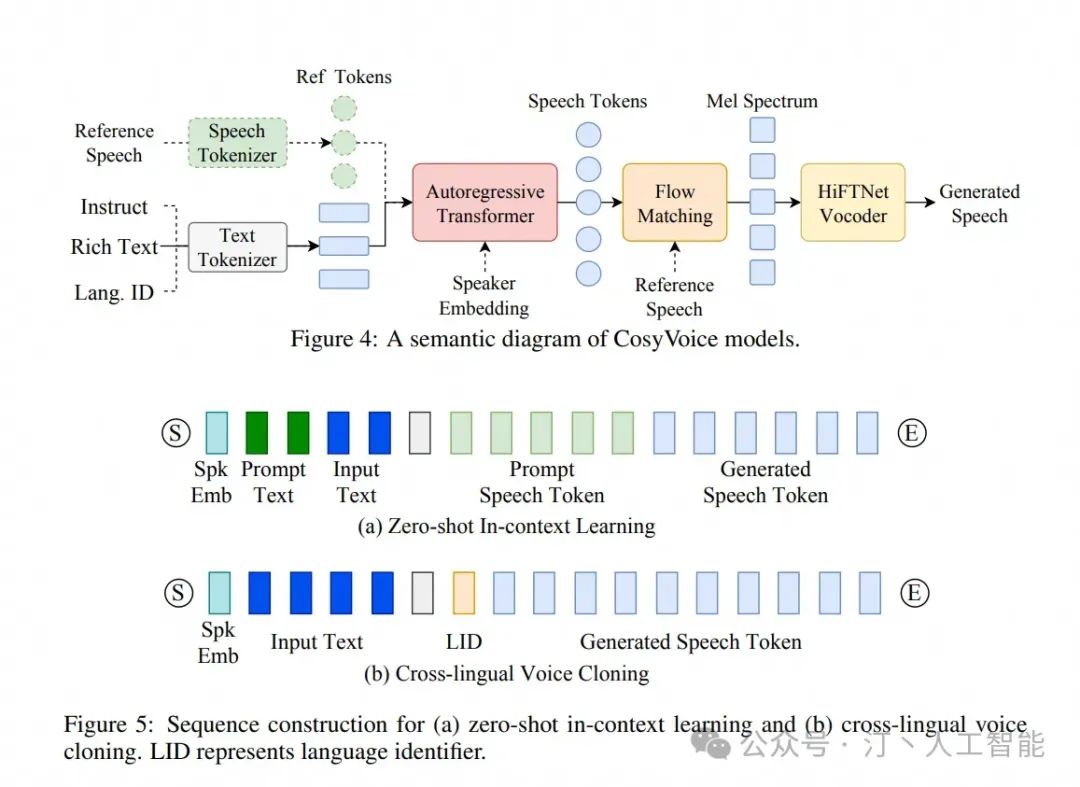
- 自然语音生成:能够生成自然流畅、逼真的语音。
- 多语言支持:支持中文、英文、日语、粤语和韩语。
- 音色和情感控制:通过少量原始音频生成模拟音色,包括韵律和情感细节。
- 细粒度控制:支持以富文本或自然语言精细控制生成语音的情感和韵律
4.2 音频多模态大模型方案
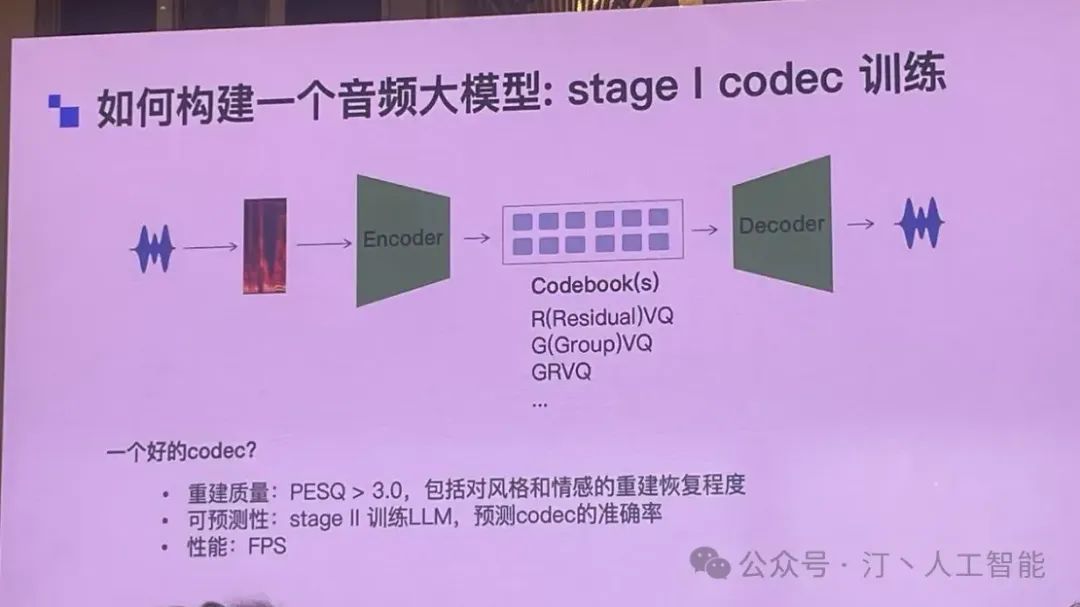
首先解决如何将声音变为数字编码以及在还原声音的过程,图中声音和 Encoder 之间的图片是声音的频谱图,虽然图这么画,但是实际上并不一定用的就是频谱图本身,按照经验可能是频率的特征,加上其他特征。
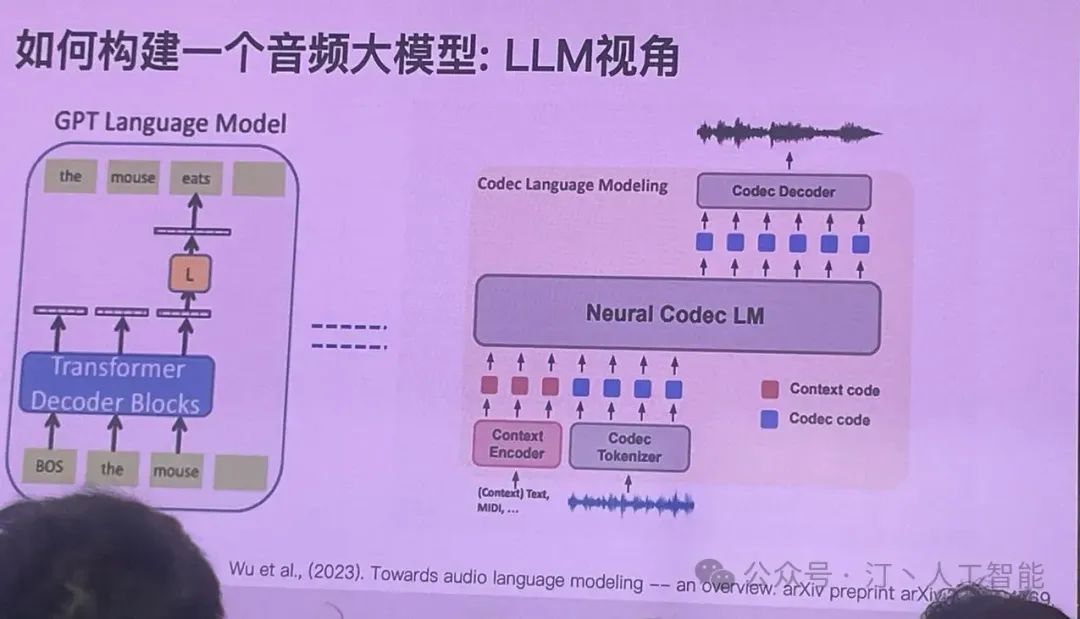
有了特征,那就大力出奇迹,all in llm。
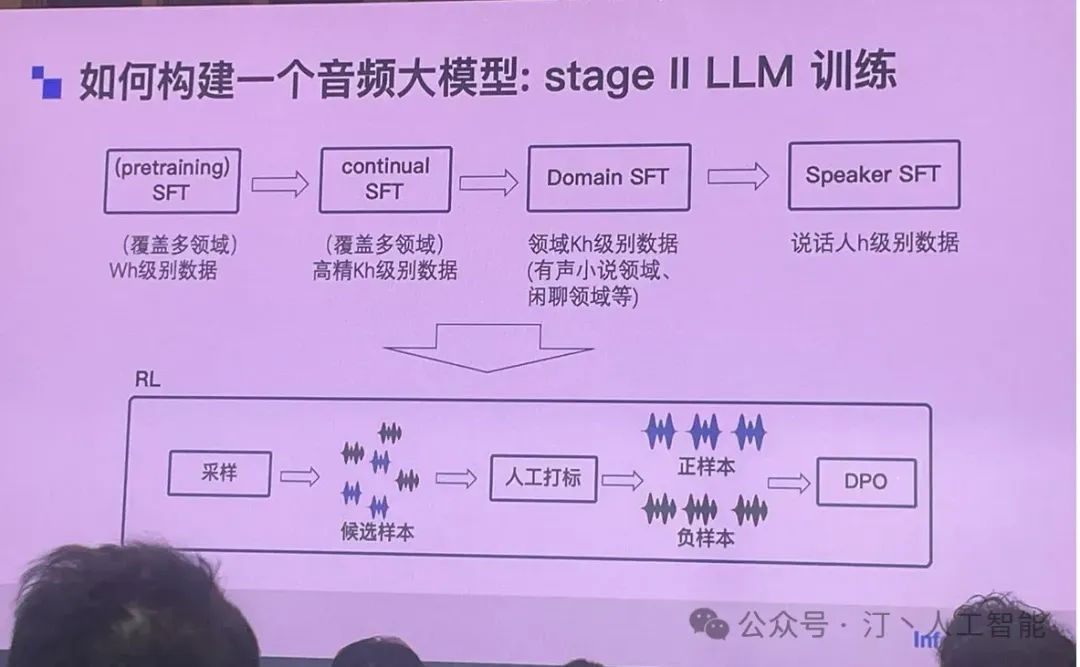
训练过程也跟 NLP 大模型训练非常像,从大量数据到少量优质领域数据。
4.3 多模块整合方案
大致归纳如下

下面是永劫无间游戏场景做的一个 AI 队友的方案,LLM 负责自然语言输出,角色 TTS 做出效果和回应
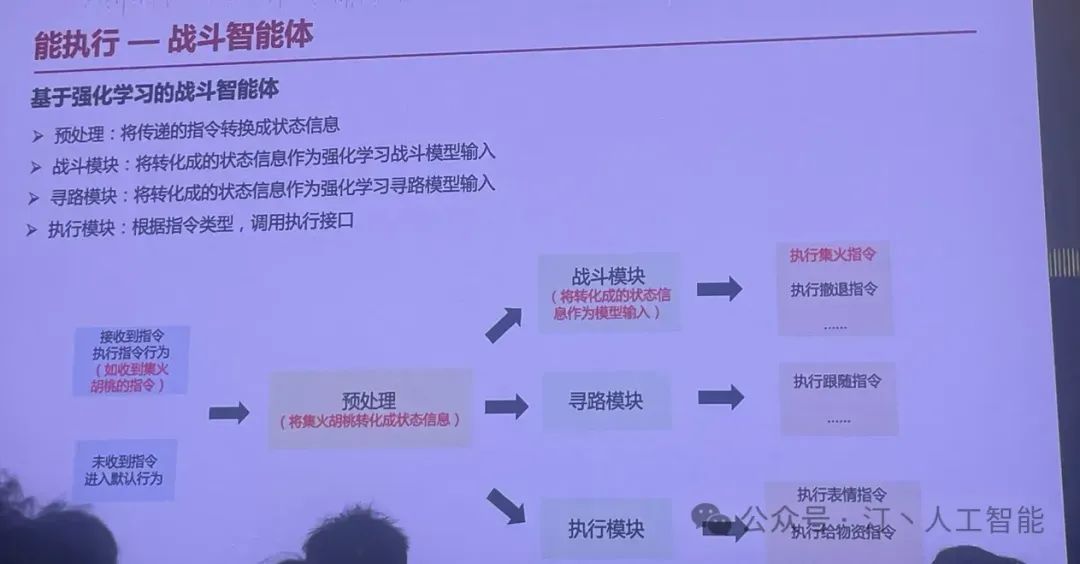
这种方案的好处是,每个模块都相对比较成熟,每个模块的质量可以得到保证,整个系统可以相比较千亿的模型相比较做的轻量级,系统的时延反馈可以做的好,体验顺畅。
5 小结
现在以 transformer 架构的模型,虽然表现出了很强的泛化能力,并且越大的模型,越大规模的数据训练,越能激发更多的创造能力,也经常会让人眼前一亮。但是对固定的业务来说,垂域的小模型是一个非常好的方案,他让业务能够快速的迭代。
但是现在的模型还是太过程式化了,对特殊 token 的理解还是非常敏感,若训练和使用不匹配,经常会出现
- 输入轮次过多的遗忘问题
- 输出重复停不下来的问题
- 应该放到user的内容放到system导致输出不达预期的问题
而人类的思考方式,完全没有以上提及的问题。这种问题的出现或许来源于 transformer 本身,也有可能来自训练过程,总之还要解决的问题还有很多,但是 AI 辅助业务提效的时代已经到来。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









