






Dify 可以通过插件实现 MCP 服务调用,而被调用的 MCP 服务基本可以分为以下两类:
- 通用 MCP 服务(非本地 MCP 服务)。
- 本地 MCP 服务。
“
本地 MCP 服务指的是本地通过 Java 或其他语言实现的 MCP 服务器端。
当你会用 Dify 调用本地 MCP 服务,也就意味着你会使用 Dify 调用通用 MCP 服务了,因为实现步骤和原理基本都是一样。
1.什么是MCP?
MCP 是 Model Context Protocol,模型上下文协议,它是由 Anthropic(Claude 大模型母公司)提出的开放协议,用于大模型连接外部“数据源”的一种协议。
它可以通俗的理解为 Java 界的 Spring Cloud Openfeign,只不过 Openfeign 是用于微服务通讯的,而 MCP 用于大模型通讯的,但它们都是为了通讯获取某项数据的一种机制,如下图所示:
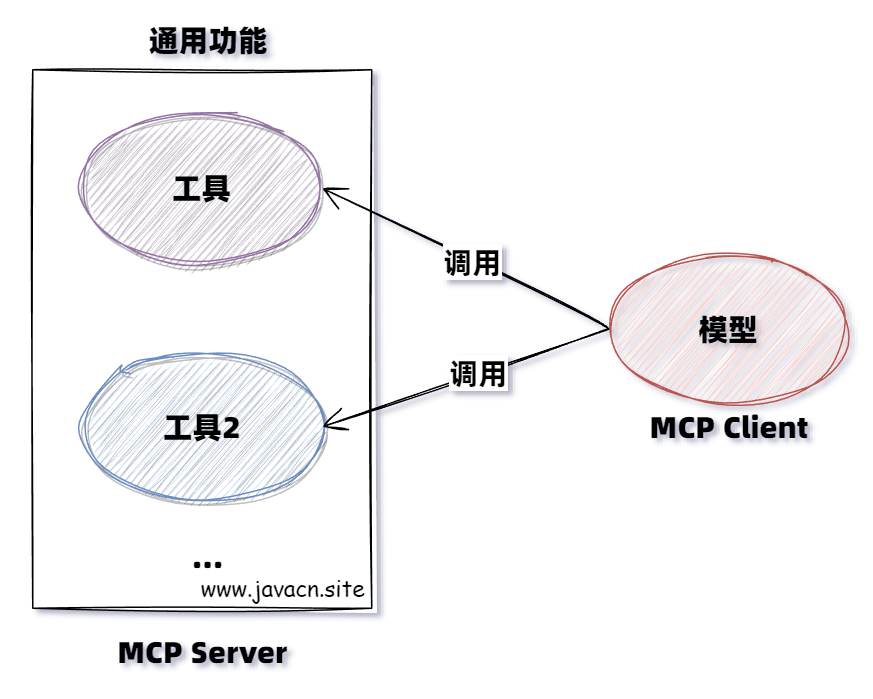
2.为什么需要MCP?
MCP 存在的意义是它解决了大模型时代最关键的三个问题:数据孤岛***、开发低效和生态***碎片化等问题。
1.打破数据孤岛,让AI“连接万物”
大模型本身无法直接访问实时数据或本地资源(如数据库、文件系统),传统方式需要手动复制粘贴或定制接口。MCP 通过标准化协议,让大模型像“插USB”一样直接调用外部工具和数据源,例如:
- 查天气时自动调用气象 API,无需手动输入数据。
- 分析企业数据时直接连接内部数据库,避免信息割裂。
2.降低开发成本,一次适配所有场景
在之前每个大模型(如 DeepSeek、ChatGPT)需要为每个工具单独开发接口(Function Calling),导致重复劳动,MCP 通过统一协议:
- 开发者只需写一次 MCP 服务端,所有兼容 MCP 的模型都能调用。
- 用户无需关心技术细节,大模型可直接操作本地文件、设计软件等。
3.提升安全性与互操作性
- 安全性:MCP 内置权限控制和加密机制,比直接开放数据库更安全。
- 生态统一:类似 USB 接口,MCP 让不同厂商的工具能“即插即用”,避免生态分裂。
4.推动AIAgent的进化
MCP 让大模型从“被动应答”变为“主动调用工具”,例如:
- 自动抓取网页新闻补充实时知识。
- 打开 Idea 编写一个“Hello World”的代码。
MCP 的诞生,相当于为AI世界建立了“通用语言”,让模型、数据和工具能高效协作,最终释放大模型的全部潜力。
3.MCP组成和执行流程
MCP 架构分为以下 3 部分:
- 客户端:大模型应用(如 DeepSeek、ChatGPT)发起 MCP 协议请求。
- 服务器端:服务器端响应客户端的请求,并查询自己的业务实现请求处理和结果返回。
运行流程:
- 用户提问 LLM。
- LLM 查询 MCP 服务列表。
- 找到需要调用 MCP 服务,调用 MCP 服务器端。
- MCP 服务器接收到指令。
- 调用对应工具(如数据库)执行。
- 返回结果给 LLM。
4.编写本地MCP服务
接下来,我们使用 Spring AI 来实现本地 MCP 服务器端,它的主要实现步骤如下:
- 添加 MCP Server 依赖。
- 设置 MCP 配置信息。
- 编写 MCP Server 服务代码。
- 将 MCP Server 进行暴露设置。
关键实现代码如下。
4.1 添加 MCP Server 依赖
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webflux</artifactId>
</dependency>
</dependencies>
<repositories>
<repository>
<name>Central Portal Snapshots</name>
<id>central-portal-snapshots</id>
<url>https://central.sonatype.com/repository/maven-snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
MCP Server 依赖有三种类型:
- 标准输入/输出 (STDIO):spring-ai-starter-mcp-server
- Spring MVC(服务器发送的事件):spring-ai-starter-mcp-server-webmvc
- Spring WebFlux(响应式 SSE):spring-ai-starter-mcp-server-webflux
4.2 设置 MCP 配置信息
MCP Server 包含以下配置信息:
| 配置项 | 描述 | 默认值 |
|---|---|---|
| enabled | 启用/禁用 MCP 服务器 | TRUE |
| stdio | 启用/禁用 stdio 传输 | FALSE |
| name | 用于标识的服务器名称 | mcp-server |
| version | 服务器版本 | 1.0.0 |
| type | 服务器类型 (SYNC/ASYNC) | SYNC |
| resource-change-notification | 启用资源更改通知 | TRUE |
| prompt-change-notification | 启用提示更改通知 | TRUE |
| tool-change-notification | 启用工具更改通知 | TRUE |
| tool-response-mime-type | (可选)每个工具名称的响应 MIME 类型。例如,将 mime 类型与工具名称相关联spring.ai.mcp.server.tool-response-mime-type.generateImage=image/pngimage/pnggenerateImage() | - |
| sse-message-endpoint | Web 传输的 SSE 终端节点路径 | /mcp/message |
其中 MCP Server 又分为以下两种类型。
服务器类型
- 同步服务器:默认服务器类型,它专为应用程序中的简单请求-响应模式而设计。要启用此服务器类型,请在您的配置中设置。 激活后,它会自动处理同步工具规格的配置,spring.ai.mcp.server.type=SYNC。
- **异步服务器:**异步服务器实现使用非阻塞作并针对非阻塞作进行了优化。要启用此服务器类型,请使用配置您的应用程序。此服务器类型会自动设置具有内置 Project Reactor 支持的异步工具规范,spring.ai.mcp.server.type=ASYNC。
4.3 编写MCPServer服务代码
编写天气预报查询伪代码:
import org.springframework.ai.tool.annotation.Tool;
import org.springframework.stereotype.Service;
import java.util.Map;
@Service
publicclass WeatherService {
@Tool(description = "根据城市名称获取天气预报")
public String getWeatherByCity(String city) {
Map<String, String> mockData = Map.of(
"西安", "晴天",
"北京", "小雨",
"上海", "大雨"
);
return mockData.getOrDefault(city, "抱歉:未查询到对应城市!");
}
}
4.4 将服务暴露出去
@Bean
public ToolCallbackProvider weatherTools(WeatherService weatherService) {
return MethodToolCallbackProvider.builder().toolObjects(weatherService).build();
}
这样 MCP Server 就编写完成了。
5.Dify调用本地MCP
Dify 调用 MCP 主要步骤如下:
- 安装 MCP 插件。
- 配置 MCP 服务 HTTP 地址。
- 配置 Agent 相关信息。
- 运行测试。
具体配置如下。
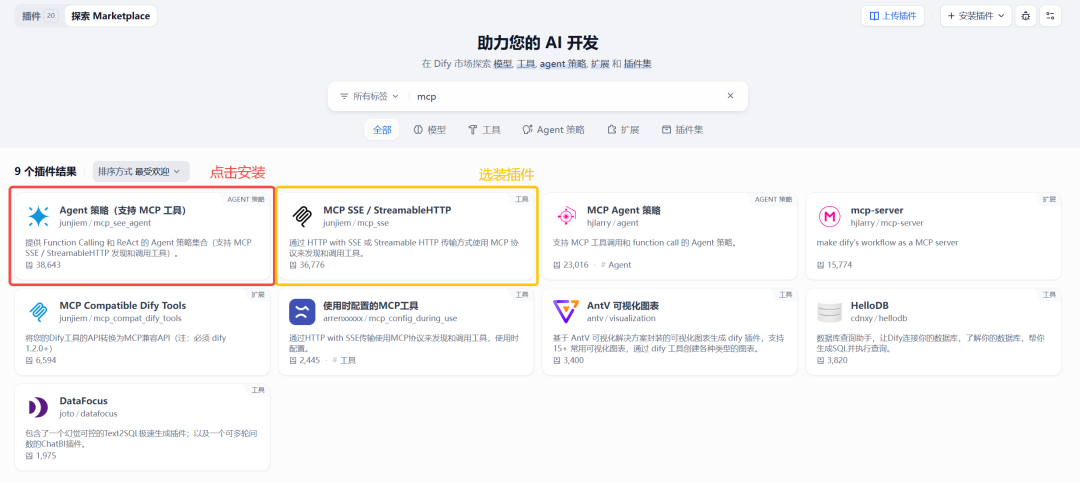
5.1 安装 MCP 插件
安装 Agent 策略(支持 MCP 工具)如下图所示:
“
MCP SSE 选装,非必须,可以为后续 Agent 提供 MCP 工具列表,方便 LLM 正确理解和调用工具。
5.2 配置 MCP 服务地址
Dify 只支持 HTTP 协议的 MCP 服务调用,它的配置格式如下:
{
"server_name1": {
"transport": "sse",
"url": "http://127.0.0.1:8000/sse",
"headers": {},
"timeout": 50,
"sse_read_timeout": 50
},
"server_name2": {
"transport": "sse",
"url": "http://127.0.0.1:8001/sse"
},
"server_name3": {
"transport": "streamable_http",
"url": "http://127.0.0.1:8002/mcp",
"headers": {},
"timeout": 50
},
"server_name4": {
"transport": "streamable_http",
"url": "http://127.0.0.1:8003/mcp"
}
}
支持配置多个 MCP 服务,或者是以下 JSON 格式也支持:
{
"mcpServers": {
"server_name1": {
"transport": "sse",
"url": "http://127.0.0.1:8000/sse",
"headers": {},
"timeout": 50,
"sse_read_timeout": 50
},
"server_name2": {
"transport": "sse",
"url": "http://127.0.0.1:8001/sse"
},
"server_name3": {
"transport": "streamable_http",
"url": "http://127.0.0.1:8002/mcp",
"headers": {},
"timeout": 50
},
"server_name4": {
"transport": "streamable_http",
"url": "http://127.0.0.1:8003/mcp"
}
}
}
5.3 配置 Agent
Agent 需要配置的项目比较多,首先是 Agent 策略:
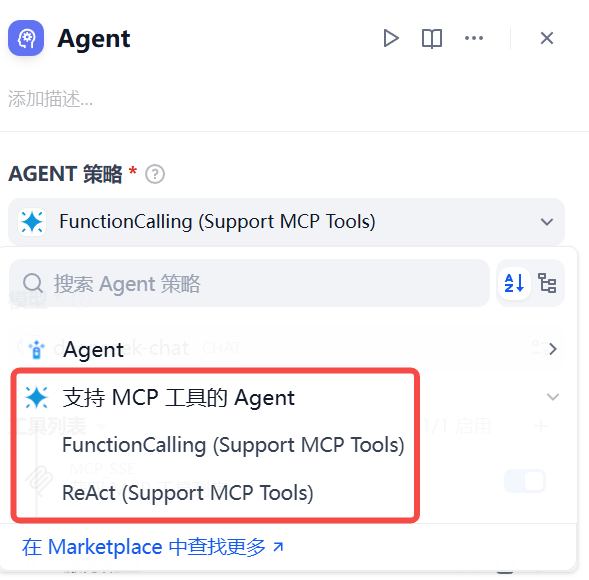
然后是 LLM,选择合适的大模型即可,之后配置 MCP 工具和 HTTP 地址,如下图所示:
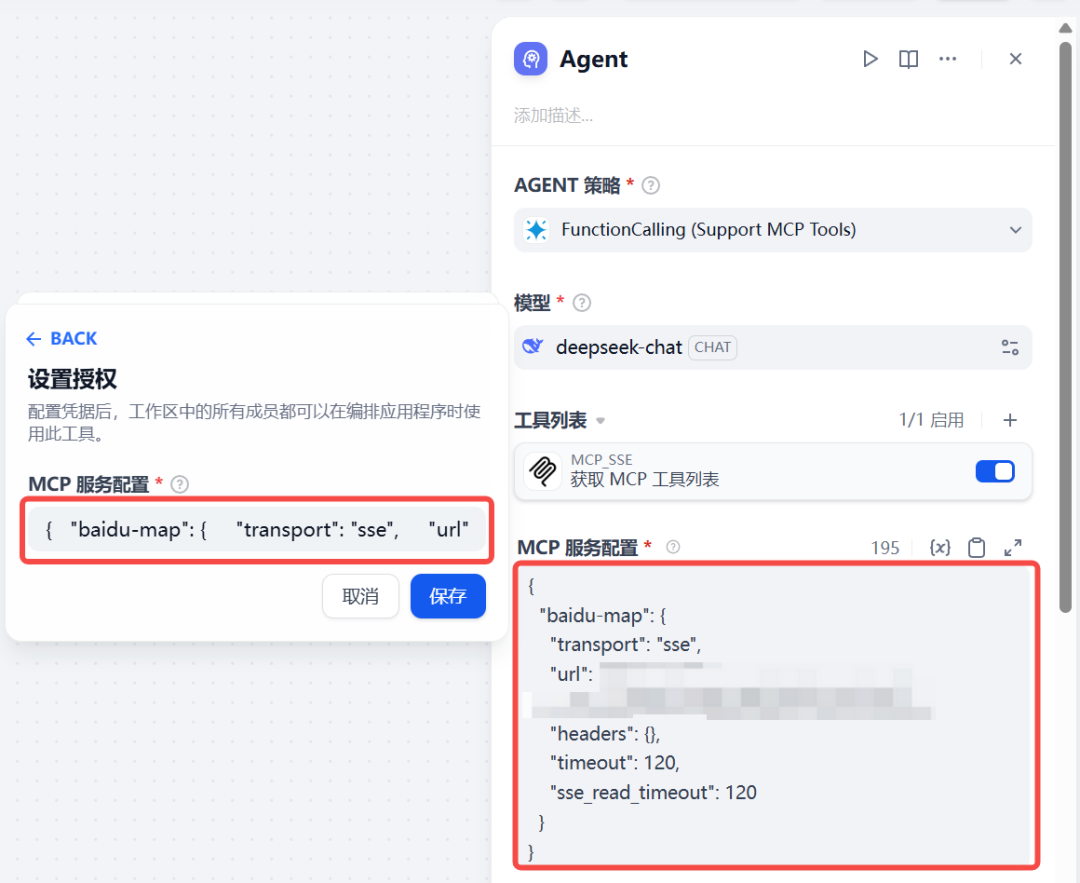
之后配置指令和查询问题:
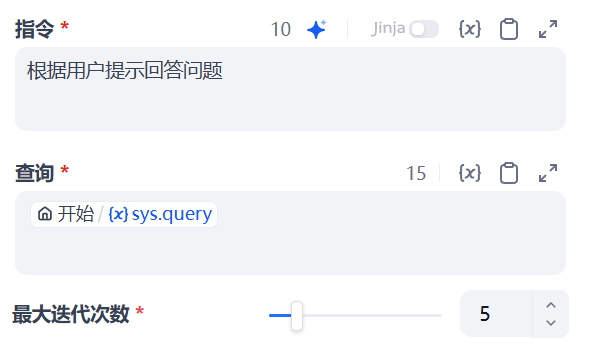
5.4 测试 MCP 调用
我们创建的是一个 ChatFlow,执行效果如下:
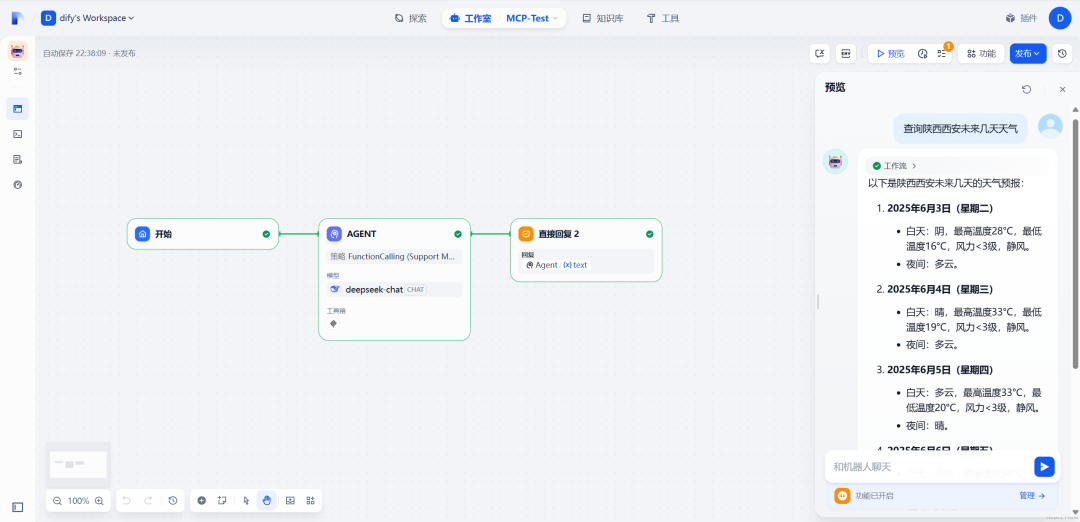
执行符合预期。
小结
Dify 调用 MCP 服务主要依靠的是 HTTP 地址和 MCP 协议,对于用户来说他面向的是大模型,对于程序来说是大模型调用了 MCP 服务,所以大模型端也就是 MCP 的客户端。我们会调用本地 MCP 服务了,那么问题来了,如何调用通用的 MCP 服务呢?
如何学习大模型技术,享受AI红利?
面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,详尽的全套学习资料,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
无论是初学者,还是希望在某一细分领域深入发展的资深开发者,这样的学习路线图都能够起到事半功倍的效果。它不仅能够节省大量时间,避免无效学习,更能帮助开发者建立系统的知识体系,为职业生涯的长远发展奠定坚实的基础。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

结语
大模型作为新时代的风口,确实为那些希望转行或寻求职业突破的人提供了广阔的舞台。然而,是否选择进入这一领域还需综合考虑自身的兴趣、特长以及长远规划。通过构建基础知识体系、参与实际项目、拓展软技能、关注跨学科融合以及建立广泛的社交网络,你可以在这个充满机遇的新领域中迅速站稳脚跟。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









